As your organization progresses through its DevOps journey, what are the best practices that successful teams use that you should follow?

5 Core Practices for How To Establish And Build Successful DevOps Team
Puppet and Splunk surveyed more than 3,000 participants, and the findings reveal a set of core DevOps practices that are critical for mission success. Discover what separates successful DevOps teams from those that fail, and learn the next steps to take on your DevOps journey.
Read on this article to learn:
- Key practices required to be a mature DevOps organization
- Why collaboration is paramount to a team’s success
- The importance of real-time monitoring and observability and key metrics to track
Content Summary
Introduction
Choose your own adventure.
The Evolutionary Scale
The foundational practices and CAMS
It’s all about sharing.
The 5 Foundational Practices, One by One
Monitoring and alerting are configurable by the team operating the service.
What to measure – and how
Importance of monitoring real business metrics
The measure is a core piece of DevOps.
Reuse deployment patterns for building applications or services
Reuse testing patterns for building applications or services
Teams contribute improvements to tooling provided by other teams.
Configurations are managed by a configuration management tool.
Implementing the Foundational Practices in Your Organization
BUT… start where you are
Now share with more teams.
The best path is the path that will show quick results.
Introduction
It’s taken less than a decade for DevOps to move from hot new buzzword to being widely acknowledged as the right way to manage technology change and deliver software in a fast-moving, highly competitive business environment. But even with plenty of examples offered at tech conferences around the world, in books and on leading blogs, most teams still struggle with how to get started, and where to go after these first steps.
The Puppet 2018 State of DevOps Report took a new tack this year, seeking prescriptive guidance for teams to follow. We designed our survey to learn how organizations progress through their DevOps journeys, and after analyzing the data, we found that the successful ones go through specific stages. Our research also revealed a set of core practices — we call them “foundational practices” — that are critical to success throughout the entire DevOps evolution. In this paper, we’ll take you through an in-depth description of these foundational practices, and offer you our advice for how to begin instituting them in the way that makes the most sense for your organization, based on our findings.
Choose your own adventure.
Every organization starts from its own unique place. It has legacy technologies, established ways of doing things, its own specific business mission and its own particular culture. So there is no single path to a DevOps transformation; instead, there are many possible evolutionary paths.
Analysis of the data from the 2018 State of DevOps survey revealed the foundational practices that successful teams employ. These practices correlate so strongly with DevOps success, we’ve determined they are essential at every stage of DevOps development. In other words, the practices that must be adopted at any given stage to progress to the next stage remain important even for those organizations that have evolved the furthest on their DevOps journey, and that has already shown the most success.
Each foundational practice can be described in a sentence:
- Monitoring and alerting are configurable by the team operating the service.
- Deployment patterns for building applications or services are reused.
- Testing patterns for building applications or services are reused.
- Teams contribute improvements to tooling provided by other teams.
- Configurations are managed by a configuration management tool.
When we examined each of these practices more closely, we found that highly evolved organizations (see The evolutionary scale) were much more likely always to be using these practices throughout the evolutionary journey than the less-evolved organizations. What we take from our findings is that the foundational practices listed above are integral to DevOps and critical for DevOps success.
The Evolutionary Scale
For the 2018 State of DevOps Report, we developed a model to measure each respondent organization’s position on the evolutionary scale. We scored responses based on how frequently the respondent’s organization was doing each practice (1 = Never, 2 = Rarely, 3 = Sometimes, 4 = Most of the time, 5 = Always). We then summed these scores to create a composite score. Based on this composite score, we then grouped those responses into three categories: Low, Medium and High. Organizations that employ all the practices with a high frequency are highly evolved, or High. Those organizations employing practices with low frequency are Low, and those doing some practices sometimes are Medium. See the full methodology for the Puppet 2018 State of DevOps Report for a full explanation.
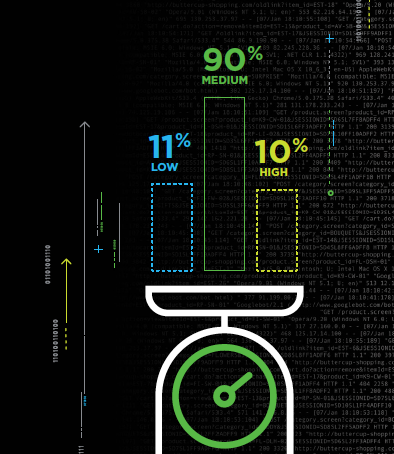
The Evolutionary Scale
90% of respondent organizations are at least Medium. Almost 11% are Low, and just under 10% are High. This tells us that DevOps practices have become mainstream and that it’s much harder to make the leap from Medium to High than it is from Low to Medium. From this, we extrapolate that organizations can gain a serious competitive advantage if they concentrate on further evolving their DevOps practices.
We suspect that people can get to Medium status with less effort because the automation path is relatively well defined. Still, the jump to High requires the implementation of DevOps culture and sharing, which are more difficult to grasp and instil.
The foundational practices and CAMS
The importance of the foundational elements of DevOps shouldn’t surprise anyone who takes more than a passing interest in DevOps. Other well-regarded constructs are built around these same foundations. The CAMS model, one of the earliest descriptions of DevOps, encompasses these foundational known-good patterns, from the importance of measurement and sharing to the need for automation. Other tropes and methodologies are common in the DevOps discourse — concepts such as shifting left, empowered teams, test-driven development and more — also reinforce these foundational patterns and practices.
It’s all about sharing.
On studying the foundational practices revealed by our research, we realized that they are all dependent on sharing and that they all promote sharing.
- Monitoring and alerting are configurable by the team operating the service. Monitoring and alerting is key to sharing information about how systems and applications are running, and getting everyone to a common understanding. This common understanding is vital for making improvements, whether within a single team and function or across multiple teams and functions.
- Deployment patterns and testing patterns for building applications or services are reused. Sharing successful patterns across different applications or services often means sharing across different teams, establishing agreed-upon ways of working that provide a foundation for further improvements.
- Teams contribute improvements to tooling provided by other teams. This form of sharing promotes more discussion between teams around priorities and plans for further improvements in tooling, process and measurement.
- Configurations are managed by a configuration management tool. A configuration management tool enables development, security and other teams outside Ops to contribute changes to system and application configurations. This makes operability and security a shared responsibility across the business.
Our discovery that all the fundamental practices enable or rely on sharing tells us that the key to scaling DevOps success is the adoption of practices that promote sharing.
It makes sense: When people see something that’s going well, they want to replicate that success, and of course, people want to share their successes. Let’s say your team has successfully deployed an application 10 times, and let’s also say this type of deployment has normally given your team (and others) a lot of trouble. Chances are, someone will notice and want to know how you’re doing it. That’s how DevOps practices begin to expand across multiple teams.
The 5 Foundational Practices, One by One
In this section, we describe each of the foundational practices in some detail and how the practice contributes to the evolution of DevOps.
Monitoring and alerting are configurable by the team operating the service.
Core to the DevOps movement is the two-sided coin of empowerment and accountability, which Amazon CTO Werner Vogels summarized in his famous statement: “You build it, you run it.” So our research looked at how many teams that run applications and services in production — whether comprised of devs, operators, software release engineers or others — can define their own monitoring and alerting criteria.
Empowered teams that run applications and services in production can define what good service is; how to determine whether it’s operating properly; and how they’ll find out when it’s not. This empowered monitoring approach can take many forms. For example:
- “Drop a monitoring config in a location, and we’ll pick it up.”
- “Login to this web interface to configure your monitoring.”
- “Add some monitorable outputs to your infrastructure code.”
- “Here’s an API for you to configure monitoring as code.”
We found that once organizations start to see traction with DevOps, 47% of the highly evolved (High) cohort can define their own monitoring and alerting criteria for apps and services in production, compared to just 2% of the least-evolved (Low) cohort. The High cohort is 24 times more likely to have adopted this practice! Conversely, the Low cohort was 23 times more likely never to use this practice.
In our survey, we asked, “How frequently were these practices used after you started to see some traction with DevOps?” To the right is a breakdown of answers for the practice, “Monitoring and alerting are configurable by the team operating the service.”
Empowering teams to define, manage, and share their own measurement and alerting supports multiple elements of a DevOps transformation, including:
- Sharing metrics as a way to promote continuous improvement
- Creating and promoting a culture of continuous learning
- Cross-team collaboration and empowered teams
- Development of systems thinking in individuals and teams.
These factors are core to a strong DevOps culture, as we discussed earlier, so it’s not surprising that the highly evolved organizations we surveyed adopt this practice early.

How frequently were these practices used after you started to see some traction with DevOps?” To the right is a breakdown of answers for the practice, “Monitoring and alerting are configurable by the team operating the service.
What to measure – and how
Our research showed what to monitor and alert for:
- Key system metrics such as latency, response time, resource utilization and more. A majority of respondents (56%) expose these.
- Business objectives derived from system metrics, for example, measuring response time as a proxy for customer satisfaction. More than a third of respondents (37%) monitor these.
- On-demand access to real business metrics such as time on site, the application opens, customer sign-ups, revenue rates, etc. 20% of respondents provide this.
As organizations evolve, they are increasingly likely to incorporate automated measurement techniques into their monitoring practices. Among the most evolved respondents, 66% measure systems-level metrics automatically, compared to just 32% of organizations at the lower end of DevOps evolution. When it comes to producing system metrics manually, 59% of less-evolved organizations do that, while just 38% of highly evolved organizations do.

As organizations evolve, they are increasingly likely to incorporate automated measurement techniques into their monitoring practices.
- 56%: We manually measure key system metrics.
- 20%: Business-level measurements are automatically available on-demand.
- 37%: Business-level measurements are manually gathered using system-level metrics.
- 43%: We automatically measure key system metrics.
Importance of monitoring real business metrics
As organizations evolve, so does their approach to monitoring business impact. Our research data shows that at the higher levels of DevOps evolution, nearly five times as many organizations automatically collect real business metrics (34%), compared to the 7% of less-evolved organizations that automate the collection of business metrics.
Some IT teams use business metrics as primary measures of IT performance. For example, site reliability engineers for a video streaming service track “successful video starts” as a key metric for service health. In contrast, developers at an online gaming service track customer sign-ups and cancellations, plus money gambled and paid out, as measures of release success.

As organizations evolve, so does their approach to monitoring business impact.
Business metrics answer day-to-day service questions such as:
- Can customers buy from us?
- How many people are we serving?
- How much money are we making?
- Is this pattern normal?
Business metrics are also important for long-term measures of success, such as:
- Does the new release do what we expected?
- Does it drive better business outcomes?
- How does its business impact compare to other versions?
For more advanced organizations using data analytics, machine learning, and artificial intelligence, business data provides early warning of failure by alerting to changes such as lower revenue per minute and a higher-than-usual bounce rate that could be caused by undetected website errors. Monitoring business metrics can also help a team get more resources for its DevOps initiative by demonstrating the successes achieved so far in terms the business can understand.
On observability, telemetry, and semantic logging
Among highly evolved organizations, 51% always deploy logging along with the application or service, so that monitoring and alerting are simplified downstream in production operations. This provides “observability”: the aspect of a system that enables its internal states to be inferred from knowledge of its external outputs.
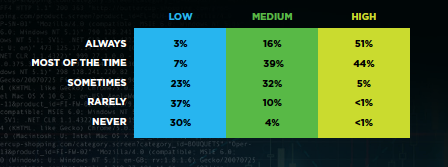
Among highly evolved organizations, 51% always deploy logging along with the application or service.
The term “observability” is used for industrial systems, and achieving observability can be as simple as adding a flow gauge inside a water pipe (i.e., an internal measurement), and connecting it to an external display (i.e., adding telemetry). Doing this allows an operator to observe an internal property of the system (how fast water is flowing inside a pipe) by observing an external output (the flow meter mounted outside the pipe).
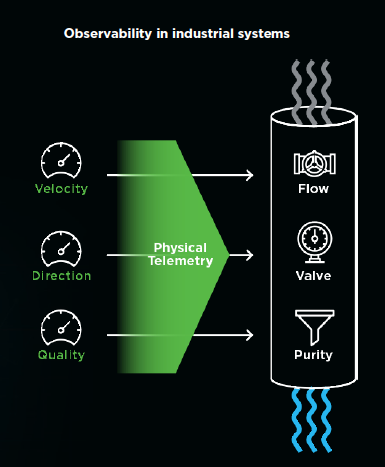
Observability in industrial systems
In an application, observability is often achieved by adding semantic logging to describe the real activity of an application, which can include both technical metrics such as end-to-end response time and business metrics such as revenue per transaction. This enables teams to configure their monitoring using actual measures of success — both technical and business success — rather than having to guess at results from less reliable proxies and approximations.

Observability in software systems
Observability enables teams to work with modern composable architectures such as cloud, microservices, containers, APIs and serverless infrastructure. For all their advantages, these architectures may provide no visibility into infrastructure performance, no ability to inject bytecode instrumentation, and no way to execute synthetic transactions. In such complex, opaque systems, using semantic logging (and more) to build observability into the system at release time puts DevOps practitioners in the driver’s seat, able to define and configure meaningful monitoring.
The measure is a core piece of DevOps.
Empowered monitoring isn’t for just Ops or some newly created DevOps team: It’s for all teams that work with technology. The embrace of empowered monitoring for all teams underlines one of the most important points of DevOps: that you don’t need to create a new team with new superpowers but instead should empower all existing teams so they can work together in new ways.
Self-service monitoring and alerting can just as easily and usefully be adopted by:
- Developers running their own code.
- A team of developers working with their operations counterparts to deliver operable applications.
- A DevOps team working as a single cohesive group to define their own monitoring practice.
- A complex team of teams where ops specialists monitor applications delivered by devs as part of a broader system.
Regardless of the specific circumstances, self-service monitoring and alerting is a countermeasure to the long-standing anti-pattern of Dev and Ops working in silos. Simply opening access to these key metrics enables a sharing culture, populates feedback loops, enables continuous feedback, and promotes a culture of continuous learning across teams.
Instilling ownership and accountability by empowering service delivery teams to collect, share, and customize monitoring data is a fundamental part of the cultural change of DevOps, and enables even more fundamental shifts further along in the process.
Reuse deployment patterns for building applications or services
Our research reveals a second baseline capability that is critical to DevOps success: the ability to reuse pre-defined deployment routines, processes, systems and tools for building either applications or entire end-to-end services.
By the time our survey respondents had gained some traction with their DevOps initiatives, 46% of highly evolved organizations had reported always reusing deployment patterns for building applications or services, versus 2% of the least-evolved organizations. So the High teams are 23 times more likely always to employ this practice.
We asked, “How frequently were these practices used after you started to see some traction with DevOps?” Here is the breakdown of responses for the practice, “We reuse deployment patterns for building applications or services.”

How frequently were these practices used after you started to see some traction with DevOps?
We asked, “How frequently were the following used while you were expanding DevOps practices?” Here is the breakdown of responses for the practices, “We reuse deployment patterns for building applications or services.”

How frequently were the following used while you were expanding DevOps practices?
We asked about the reuse of deployment patterns because of the special nature of application deployment in most, if not all, organizations. Residing at the boundary between development and production, application deployment is where Dev and Ops most often meet — and most painfully collide. So improving application deployment is right at the core of DevOps, as it mediates the “wall of confusion”3 at the intersection of Dev and Ops.
The use of repeatable patterns — whether created in-house or adopted from an external source — does more than alleviate the immediate pain and confusion of deployment. It also makes it possible to share and spread the knowledge of how to deploy more widely in the organization, enabling more teams and individuals to work together on what needs to be a core competency for any business.
Reuse testing patterns for building applications or services
Just like the ability to share and reuse deployment patterns, organizations that are making progress in their DevOps evolution use repeatable testing patterns. As organizations are starting to achieve traction with DevOps, 44% of highly evolved organizations reported that they always use repeatable testing patterns compared to fewer than 1% of the least-evolved organizations. That makes highly evolved organizations 44 times more likely to use repeatable testing patterns.
We asked, “How frequently were these practices used after you started to see some traction with DevOps?” Here’s the breakdown of answers for “We reuse testing patterns for building applications or services.”

How frequently were these practices used after you started to see some traction with DevOps?
Automated testing and reuse of testing patterns can be one of the harder challenges to solve depending on your organization’s structure and complexity. Though we do see this practice adopted by highly evolved organizations in the early stages of a DevOps evolution, it may not be the first thing you tackle. Here are some considerations as you prioritize this practice:
- If quality teams are quite disconnected from Dev and Ops teams, you may want to wait to integrate them into DevOps initiatives later on. Focus on establishing good testing patterns within your own team first. For ops teams, that could mean having a process for testing infrastructure changes before deploying to production. For dev teams, that could mean implementing test-driven development (TDD) or other methodology as part of your agile workflow.
- Activities closest to production, such as provisioning, monitoring, alerting, etc., are an often higher priority for teams because that’s where more issues become visible. Solve your deployment pains first to gain back the time you can then use for improving your testing practices.
- Testing patterns may be less reusable than deployment patterns because testing deals with the specifics of an application or service, and also covers many different processes — smoke tests, unit tests, functional tests, compliance tests, complexity tests — in both static/ white box or dynamic/black box environments.
- Testing in production is harder and often more complex than testing in pre-production, as its goals are different from those of a preproduction test. Quality teams test in pre-production for compliance, stability, security, customer satisfaction and other core goals. With continuous delivery, teams can experiment in production to test new ideas (e.g., via blue/green or canary releases). This is valuable, but it’s different yet again from testing in production, which focuses on quality, functionality, resilience, stability, and more.
- We conclude that adoption of reusable test processes is a fundamental practice, but tends to get pushed out later in the evolutionary journey after deployment patterns are well established. If you have to prioritize, we recommend waiting to tackle this one and focusing on the other practices first. However, once you do adopt this practice, it’s important to ensure that testing patterns are shareable. For example, you can encode reusable tests into automated testing tools, and share access to those tools — along with the resulting reports or dashboards — among all stakeholders.
Teams contribute improvements to tooling provided by other teams.
The ability to contribute improvements to tooling provided by other teams stands out as a key foundational capability.
As organizations expanded their DevOps practices, 44% of the highly evolved cohort reported that teams could always contribute improvements to other teams’ tooling compared to fewer than 1% of the least-evolved cohort. In other words, the highly evolved cohort is 44 times more likely to employ this practice.
We asked, “How frequently were the following used while you were expanding DevOps practices?” Here’s the breakdown of answers for “Teams contribute improvements to tooling provided by other teams.”
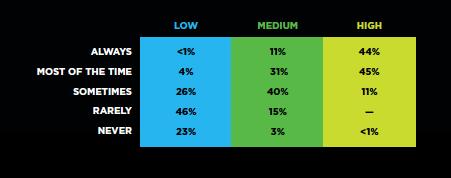
How frequently were the following used while you were expanding DevOps practices?
Improvements to tooling are typically manual and ad hoc and siloed within a single team until some change drives the need to open up to other teams. This change might be division-wide culture or organizational changes; new cross-boundary data sources such as semantic logging; or new collaboration across teams at functional boundaries such as provisioning or release automation.
Because the practice of cross-team contributions to tooling is dependent on teams putting their own houses in order first, we believe the adoption of this practice can be left to a later stage with equal chances of success.
Configurations are managed by a configuration management tool.
The practice of managing configurations with a configuration management tool rapidly takes root once organizations start to see traction with their DevOps evolution. 53% of the highly evolved cohort reported employing configuration management always, compared to 2% of the least-evolved cohort. The highly evolved cohort is almost 27 times more likely always to use a configuration management tool.
We asked, “How frequently were these practices used after you started to see some traction with DevOps?” Here’s a breakdown of answers to “Configurations are managed by a configuration management tool.”

How frequently were these practices used after you started to see some traction with DevOps?
For long-time DevOps devotees, it is not surprising to see this practice emerge as a baseline for success. Automated configuration management was a prime mover of DevOps for many years, especially in the earliest days of thinking about infrastructure as code, and the DevOps movement largely coalesced around the earliest innovators in automated configuration management.
Looking at the early drivers for DevOps explains the importance of configuration management.
As the consumerization of IT drove unprecedented demand for speed and service, developers’ inability to provision and configure key resources for development and testing — let alone production — became a significant impediment to rapidly providing high-quality software that would meet customer and business demands.
Meanwhile, IT ops teams were just as frustrated by their inability to make any substantial changes to the applications and services they were running — changes that would make these apps and services more stable, more efficient, and more operable.
The emergence of cloud computing gave developers the ability to provide for their own needs, just by pulling out a credit card. But this new capability also created more problems and frustration for Ops. As developers resorted to shadow IT, Ops teams were faced with a multitude of uniquely configured, difficult-to-manage, highly brittle and error-prone snowflakes in production.
As developers and operators started working together to solve these difficulties around provisioning, it was natural for many DevOps initiatives to begin with automating configuration and provisioning. It’s a solution that allows both Dev and Ops to win, by enabling developers to move at market speed while encapsulating and codifying known-good configurations to reduce the pain for operators.
As DevOps evolves and expands, and developers liberated by automated provisioning move increasingly toward continuous delivery, Ops is under even greater pressure to maintain uptime, performance and availability in production. Auditability concerns also emerge as an organization’s processes mature. So automated configuration and provisioning for production become just as important as provisioning for development and testing. Achieving repeatability via configuration management assures stable, reliable and auditable production environments, and also enables later-stage capabilities — for example, self-service — that emerge as new goals for the DevOps initiative.
Finally, the importance of automated provisioning and configuration is not just about speed. It also defends against one of the earliest management fears around DevOps: that empowered developers could go rogue on production systems with no recourse, no auditing, and no control. Codifying known-good processes and executing them through preset routines allays these fears, while still enabling Dev and Ops teams to work with greater agility. Especially for larger organizations and those in regulated industries such as healthcare, finance and government, automation offers the added advantage of maintaining a record showing who touched any system, what they did and when they did it — and often, why.
Implementing the Foundational Practices in Your Organization
With so much evidence that the five foundational practices lead to success, we know our readers will want guidance on how to implement them. Fortunately, our research does provide some indication of which practices to start with.
In general, the research suggests organizations should start with baselines that set the foundation for future growth and development, while also helping to deliver immediate value. Which practice to start with depends very much on where an organization is at the outset, and what its most urgent needs are. But do take note: every one of the foundational practices is adopted early by highly evolved organizations.
Three practices were always in active use by the majority of highly evolved organizations by the time they saw some traction in their DevOps initiatives:
- Reusing deployment patterns.
- Using a configuration management tool.
- Allowing a team to configure monitoring and alerting for the service it operates.
While these three practices are foundational capabilities, and form a baseline for progression to higher levels of DevOps evolution, the order in which they are adopted is not important. Do start here, but don’t worry about which comes first. You’ll likely recognize one particular practice as something your own organization needs to prioritize.
One thing to keep in mind: Our research strongly suggests organizations need to have more of the foundational baselines in place before they start to show results. So work to adopt the three practices above, and then expand them to other teams as soon as you can.
The remaining two foundational practices are ones we recommend prioritizing after the other three practices are well established:
- Reuse testing patterns for building applications or services.
- Empower teams to contribute improvements to other teams’ tooling.
BUT… start where you are
Every organization is different. You should start where you are now. Identify the existing conditions in your organizations, and choose the approach that will best show early positive impact where your organization needs it the most. With the fundamental practices offering better monitoring, better configuration control, better deployment patterns, better quality controls, and collaborative tooling, there’s plenty of scope for choosing.
Establish and share baseline measurements for the system, customer, and business metrics at the outset, so everyone knows where you are starting, knows what needs to improve, and knows the impact of their work on the end-to-end system. This will help everyone on your team begin to embrace DevOps concepts like continuous feedback and continuous improvement.
Share work practices and processes early so you can start to move forward as a team. Automate, and shift left with the automation of configuration and provisioning to help developers achieve agility and operators achieve predictability. This will help people on both teams believe in the value of the new venture. Making people’s work lives better is a great way to earn their confidence and their continuing cooperation.
Now share with more teams.
One of our key research hypotheses was—just as with culture—automation starts within teams, for their own use. As organizations evolve, they increasingly share known good practices with other teams across the organization.
Our research confirmed this hypothesis. At the lowest level of DevOps evolution, a high proportion of respondents (59%) share best practices only within their team. Just 26% share with other teams, and only 12% share across the organization. However, as organizations evolve to the highest level of DevOps maturity, 33% share best practices with other teams or across the entire organization. Only 29% limit such collaboration to their own team.
These findings show a clear progression from tighter silos at the lowest levels of DevOps evolution to much broader sharing in organizations that are far along in their evolution. This demonstrates that DevOps practices expand from individual teams to teams of teams, and then to the entire organization, as DevOps evolves.

As organizations evolve, they increasingly share known good practices with other teams across the organization.
The best path is the path that will show quick results.
Every organization is different, so start with what matters most to the people whose blessing you need. Choose an effort that will show the kind of success that will win the confidence of leaders in your organization. This will buy you more time, more resources, and more budget to move forward and build on your early success.