The latest Microsoft AI-900 Azure AI Fundamentals certification actual real practice exam question and answer (Q&A) dumps are available free, which are helpful for you to pass the Microsoft AI-900 Azure AI Fundamentals exam and earn Microsoft AI-900 Azure AI Fundamentals certification.
Question 11
Table of Contents
You need to create a training dataset and validation dataset from an existing dataset.
Which module in the Azure Machine Learning designer should you use?
A. Select Columns in Dataset
B. Add Rows
C. Split Data
D. Join Data
Answer
C. Split Data
Explanation
A common way of evaluating a model is to divide the data into a training and test set by using Split Data, and then validate the model on the training data.
Use the Split Data module to divide a dataset into two distinct sets.
The studio currently supports training/validation data splits
Question 12
You have the Predicted vs. True chart shown in the following exhibit.
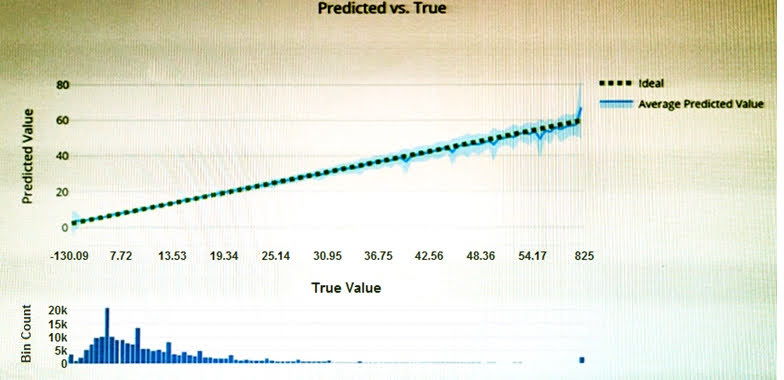
You have the Predicted vs. True chart shown in the following exhibit.
Which type of model is the chart used to evaluate?
A. classification
B. regression
C. clustering
Answer
B. regression
Explanation
What is a Predicted vs. True chart?
Predicted vs. True shows the relationship between a predicted value and its correlating true value for a regression problem. This graph can be used to measure performance of a model as the closer to the y=x line the predicted values are, the better the accuracy of a predictive model.
Question 13
Which type of machine learning should you use to predict the number of gift cards that will be sold next month?
A. classification
B. regression
C. clustering
Answer
C. clustering
Explanation
Clustering, in machine learning, is a method of grouping data points into similar clusters. It is also called segmentation.
Over the years, many clustering algorithms have been developed. Almost all clustering algorithms use the features of individual items to find similar items.
For example, you might apply clustering to find similar people by demographics. You might use clustering with text analysis to group sentences with similar topics or sentiment.
Question 14
You have a dataset that contains information about taxi journeys that occurred during a given period.
You need to train a model to predict the fare of a taxi journey.
What should you use as a feature?
A. the number of taxi journeys in the dataset
B. the trip distance of individual taxi journeys
C. the fare of individual taxi journeys
D. the trip ID of individual taxi journeys
Answer
B. the trip distance of individual taxi journeys
Explanation
The label is the column you want to predict. The identified Featuresare the inputs you give the model to predict the Label.
Example: The provided data set contains the following columns:
vendor_id: The ID of the taxi vendor is a feature.
rate_code: The rate type of the taxi trip is a feature.
passenger_count: The number of passengers on the trip is a feature.
trip_time_in_secs: The amount of time the trip took. You want to predict the fare of the trip before the trip is completed. At that moment, you don’t know how long the trip would take. Thus, the trip time is not a feature and you’ll exclude this column from the model.
trip_distance: The distance of the trip is a feature.
payment_type: The payment method (cash or credit card) is a feature.
fare_amount: The total taxi fare paid is the label.
Question 15
You need to predict the sea level in meters for the next 10 years.
Which type of machine learning should you use?
A. classification
B. regression
C. clustering
Answer
B. regression
Explanation
In the most basic sense, regression refers to prediction of a numeric target.
Linear regression attempts to establish a linear relationship between one or more independent variables and a numeric outcome, or dependent variable.
You use this module to define a linear regression method, and then train a model using a labeled dataset.
The trained model can then be used to make predictions.
Question 16
Which service should you use to extract text, key/value pairs, and table data automatically from scanned documents?
A. Form Recognizer
B. Text Analytics
C. Ink Recognizer
D. Custom Vision
Answer
A. Form Recognizer
Explanation
Accelerate your business processes by automating information extraction. Form Recognizer applies advanced machine learning to accurately extract text, key/value pairs, and tables from documents. With just a few samples, Form Recognizer tailors its understanding to your documents, both on-premises and in the cloud. Turn forms into usable data at a fraction of the time and cost, so you can focus more time acting on the information rather than compiling it.
Question 17
You use Azure Machine Learning designer to publish an inference pipeline.
Which two parameters should you use to consume the pipeline? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. the model name
B. the training endpoint
C. the authentication key
D. the REST endpoint
Answer
A. the model name
D. the REST endpoint
Explanation
A: The trained model is stored as a Dataset module in the module palette. You can find it under My Datasets. Azure Machine Learning designer lets you visually connect datasets and modules on an interactive canvas to create machine learning models.
D. You can consume a published pipeline in the Published pipelines page. Select a published pipeline and find the REST endpoint of it.
To consume the pipeline, you need:
- The REST endpoint for your service
- The Primary Key for your service
Question 18
A medical research project uses a large anonymized dataset of brain scan images that are categorized into predefined brain haemorrhage types.
You need to use machine learning to support early detection of the different brain haemorrhage types in the images before the images are reviewed by a person.
This is an example of which type of machine learning?
A. clustering
B. regression
C. classification
Answer
C. classification
Question 19
When training a model, why should you randomly split the rows into separate subsets?
A. to train the model twice to attain better accuracy
B. to train multiple models simultaneously to attain better performance
C. to test the model by using data that was not used to train the model
Answer
C. to test the model by using data that was not used to train the model
Explanation
The goal is to produce a trained (fitted) model that generalizes well to new, unknown data. The fitted model is evaluated using “new” examples from the held-out datasets (validation and test datasets) to estimate the model’s accuracy in classifying new data.
Question 20
You are evaluating whether to use a basic workspace or an enterprise workspace in Azure Machine Learning.
What are two tasks that require an enterprise workspace? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
A. Use a graphical user interface (GUI) to run automated machine learning experiments.
B. Create a compute instance to use as a workstation.
C. Use a graphical user interface (GUI) to define and run machine learning experiments from Azure Machine Learning designer.
D. Create a dataset from a comma-separated value (CSV) file.
Answer
A. Use a graphical user interface (GUI) to run automated machine learning experiments.
C. Use a graphical user interface (GUI) to define and run machine learning experiments from Azure Machine Learning designer.
Explanation
Note: Enterprise workspaces are no longer available as of September 2020. The basic workspace now has all the functionality of the enterprise workspace.