AI leaders are on a transformation journey, driven by analytics but very often bogged down by cultural and process-related barriers. So, how can they effectively accelerate that AI maturity journey and minimize those challenges?

The 2021 Business Value Guide for AI helps organizations make measuring AI maturity and business value from AI projects a standard practice. Through 6 key drivers (vision, data, systems, value, talent, and governance), this guidebook provides a helpful framework to ensure business value generation from AI is sustainable for the long term.
Make Measuring AI Maturity and Value a Standard Practice
“Enterprises continue to struggle to realize business value from their organizations’ data and analytics (D&A) investments. While recent surveys indicate some progress is being made, demonstrating value is now more critical than ever.” – Gartner, Achieving the Business Value of Data and Analytics, April 2020
To truly extract value from their data science, machine learning, and AI investments, organizations need to embed AI methodology into the core of not only their data strategy but their holistic business model and processes. This is much easier said than done, as organizations often face roadblocks associated with people, processes, technology, and of course, data.
In this article, we’ll cover six main drivers (outlined below) that an organization must effectively deliver on to evolve their AI maturity and create a measure, and maintain business value associated with AI projects:
- Vision: How do organizations ensure their AI transformation aligns with their strategic goals and ends up being meaningful for the business?
- Data: How do organizations acquire the right data and analytics and guarantee access to it in a governed way?
- System: How do organizations select the right technology stack to enable the end-to-end creation, use, and support of AIpowered analytical applications?
- Value: How do organizations create resilient, AI-driven assets to maximize impact?
- Talent: How do organizations solve the skills transformation challenge: getting the right people, training them, and creating AI communities?
- Governance: How do organizations set themselves up to get started and then scale the use of AI across the organization (i.e., effectively manage control versus agility)?
Best Practices per Key Driver to Maximize Business Value From AI
Value
Right Now, Organizations Should:
1. Generate early wins that matter and build on them, such as creating business use cases that will be game-changers for the company, developing talent, and using AI for key functions such as marketing or finance.
2. Implement a use case qualification framework and appoint an owner of use case qualification.
3. Track value creation as early and as often as possible and assign an owner of value tracking to coach and evangelize on the value of AI for the organization, coordinating overall efforts.
4. Share success often, reporting KPIs to management at least quarterly. Showcase success stories to build momentum and inspire other parts of the organization. Engaging the business in this way builds advocacy and, ultimately, has a greater impact.
5. Over time, develop the foundations to quantify value beyond use cases (e.g., the value from reuse and capitalization across projects).
When companies scale advanced analytics, they are essentially looking to increase data- and insights-driven decisions and optimize data-based processes while properly managing how their data and models are being used. To track and continue to generate value beyond use cases, organizations must:
- Break down silos between and among IT, analytics teams, and business stakeholders
- Generate multi-persona collaboration across data projects
- Foster reuse and capitalization of data and analytics assets
- Improve productivity and mitigate risk (embedding these practices into day-to-day business processes over time)
Although all of the key drivers mentioned in this ebook link back to value creation for the business in some way, we would be remiss if we didn’t include value as its driver — touching on the importance of value creation from the get-go, figuring out ways to untap new sources of value, and avoiding the law of diminishing returns.
It’s no secret that AI adoption can help companies increase profitability, unlock new levels of productivity, and deliver strategic business value. However, this last portion remains under-exploited, as organizations don’t always have a systematic or thoughtful approach to measuring or tracking business value. Here are three ways organizations can change that:
Measure Value Creation From the Start
In conjunction with data translators, business leads must be the first responders — it’s their job to identify specific use cases that can deliver value. Then, they should commit to measuring the financial impact of those use cases, perhaps every fiscal quarter. Finance may help develop appropriate business metrics and can also act as the independent arbiter of the use cases’ performance. Beyond that, some leading companies are moving forward with automated systems for monitoring use case performance, including ongoing model validation and upgrades.
According to the O’Reilly book “Introducing MLOps: How to Scale Machine Learning in the Enterprise,” “Business leaders view the rapid deployment of new systems into production as key to maximizing business value. But this is only true if deployment can be done smoothly and at low risk.” Therefore, in order to truly add value, teams need to make sure they develop strong alignment on and governance of their MLOps process, assessing the risks, determining their own set of fairness values, and implementing the necessary process to manage them.
Set Up Processes to Generate Ongoing Ideas for More Value
Workers and executives should establish a prioritization heuristic that allows tactical and strategic projects to emerge from shared efforts and understanding of AI’s capabilities. However, it’s important not to prioritize too prescriptively. Given the innovative and often disruptive nature of AI, there should always be room for experimentation. Adopt a three-lane approach to the organization’s AI project portfolio: experiment, pilot, and production.
Further, when reuse and capitalization become normal business processes, organizations can regularly uncover hidden use cases. By capitalizing on the work of existing projects to spin up new ones, teams might find previously untapped use cases that bring a lot more value than expected, opening up businesses to new possibilities (and sources of profit or cost savings).
“With dozens of potential use cases but limited resources, prioritize projects that have both substantial business value and a high likelihood of success. Why several use cases? The reality is that AI isn’t always the answer. But one failure doesn’t mean that the organization should abandon AI efforts entirely; it just means it hasn’t found the right use case.” – Kurt Muehmel, Chief Customer Officer, Dataiku
Avoid the Law of Diminished Returns
We know that organizations that use a multi-use case approach typically generate more returns from AI investments versus companies pursuing siloed proof of concepts. But where do they go from there? It’s about repeating the process — adding more and more use cases has a positive impact on the balance sheet at first, but eventually, the marginal value of the next use case is lower than the marginal costs. To continue seeing ROI in AI projects at scale, tackling exponentially more use cases, organizations must find ways to decrease both the marginal costs and incremental maintenance costs of Enterprise AI.
Vision
Right Now, Organizations Should:
1. Evaluate their current AI maturity (both big-picture and down to the details) and communicate on it.
2. Based on this, determine the organization’s short-, medium-, and long-term visions for AI at scale. They should be objective about where they are on the journey, as the transformation plan depends on it.
3. Start choosing and mapping out specific use cases for each stage of the vision.
Ultimately, scaling with AI means aligning AI efforts to strategic objectives. It means getting past experimentation and moving beyond initial successes. Many companies tackle the “usual suspects” as a starting point to test and monitor how their operational frameworks do while simultaneously building trust on AI impact. The real transformation happens when teams start building beyond the first few use cases and discover that AI is not an isolated topic but rather the catalyst behind the development of core business. Here are some recommendations for organizations to improve on their vision for AI:
AI Is for All Leaders
Every leader in the organization should invest time in understanding AI and it’s potential in the business, including the leadership team. AI is not a fleeting trend and should not be left in the hands of an elite few or IT exclusively. Whoever is tasked with leading the company’s analytics initiatives (whether it’s the CEO, CAO, CDO, Chief Data Scientist, etc.) should set up a series of workshops for the executive team to coach its members in the key tenets of advanced analytics and eliminate any lingering misconceptions. They can ask questions such as:
- Does pursuing AI or advanced analytics pose any threats for the company?
- What are the opportunities to use these technologies to improve existing processes?
- How can they be used to generate new business opportunities?
- What is the risk of not leveraging AI within the company or for some specific function?
These workshops can form the foundation of in-house “academics” that can continually teach key analytics concepts to a broader management audience. A perfect example of this use of education as a means to enablement is Dataiku customer GE Aviation, where all self-service data users go through the same training.
Known as DDA, or Digital Data Analyst Training, the program includes three levels that increase in difficulty and specificity of content covered, as well as a full day training for executives that is higher level and focuses on the value proposition of the self-serve data program and how/why teams and individuals partake.
Notably, the DDA 200 course is an intensive, week-long course that teaches digital data tools, data science, and process excellence, including a deep dive on Dataiku. The program has proved tremendously successful in both getting high adoption among business users as well as sustaining use of tools and the program over time.
Start Small, Plan Big
Companies in the early stages of scaling analytics use cases — 32% of organizations according to an ESI Thought Lab Survey — must meticulously lay out the top three to five feasible use cases that can create the greatest value quickly, ideally within the first year. This will establish momentum and encourage buy-in for future analytics investments. A helpful way to decide on the use cases is by analyzing the entire business value chain, from supplier to purchase to postsales, to identify the ones with the highest potential value.
Dataiku customer LINK Mobility, Europe’s leading provider of mobile communications, wanted a tool that would allow them to scale up their data requests coming from inside the company and be flexible enough to provide data insights to customers without having to use two different tools or platforms to cover their needs. They used Dataiku to quickly facilitate the deployment of revenue, generating monitoring services to customers with a small staff. In the end, the LINK Mobility team became two times faster building data projects and are now able to focus on growing their greater data strategy and vision for future data products without needing to switch tools.
Have a Plan for Driving and Tracking Value
While budget is indeed a critical requirement, getting value from AI can happen after a few months, with the eventual goal to embed AI within the organization’s business model. AI leaders, IT and business leaders, and lab researchers should all play a role in helping the organization achieve the highest ROI from AI and should manage AI like any new investments made to achieve their business goals, like P+L managers.
Further, AI maturity puts a deep focus on planning and adapting for either an incremental or transformational process change. It is measured by indicators such as reduced cycle times, lower error rates, scalability, and business agility, not exclusively cost reduction. Funding for AI initiatives doesn’t just come from IT budgets, but business unit budgets as well, so it’s critical to ask “What impact will AI have on business outcomes?” To appropriately quantify that, teams need to set aside the time to lay out a blueprint that measures milestones for AI efforts.
Dataiku customer Marlette Funding, Best Egg Loans does this quite well. Before taking on any data project, the team considers the potential business impact of the project. In the case of fraud detection, they calculated that if the model were to catch even one instance of fraud, they could save a personal loan lender an average of $15,000. They didn’t stop there, though. They also considered indirect benefits, like the fact that a more sophisticated model would speed up the process of getting a loan for customers by minimizing the number of cases that are not fraud.
No Transformation Without a Proper Program
Mastering AI won’t happen without setting up AI capabilities in the right way and in the shortest amount of time (without, of course, it being a rushed effort where certain steps are compromised along the way). In addition to the right operating model that fits the organization’s composition, teams must be dedicated to leading the way and implementing change management.
Operating Models for AI Initiatives
The three most common operating models for AI initiatives are hub and spoke, centralized, and decentralized. (Where the first two contain a center of excellence or CoE).
While decentralized models are generally not recommended as a first organizational structure when trying to get AI initiatives off the ground; however, it is presented here because it can be a logical evolutionary step for some organizations that are farther along in their AI maturity.



Data
Right Now, Organizations Should:
1. Make existing data accessible to employees for their day-to-day work so that it can be used for better decision making and start thinking more broadly about possible new sources of data.
Like GE Aviation has done, democratizing data access and using existing data enables both multi-profile collaboration and truly AI-powered assets. Down the road, teams can work toward the integration of other data sources, such as third-party data and alternative data.
2. Provide wide self-access to data to foster democratization.
According to Gartner, “Increasing analytics agility is largely associated with delegating specific tasks along the analytics life cycle to users outside the IT or analytics team, with the help of modern tools.” As a result, non-data teams can get access to better insights, understand key metrics, and streamline processes and everyone with proper access can discover and use data to do their job more efficiently.
It is important to remember, though, that tools aren’t a magic bullet. While they can be transformative, they won’t be impactful without practical ways to apply data and analytics to the work everyone in the organization is doing.
Organizations need to recognize that scaling with analytics and AI starts with conquering a few key challenges: broadening access to data, establishing a framework for data quality and governance, eliminating data silos, and creating data literacy and sustainable, internal data culture. In this section, we’ll share recommendations for how organizations can improve on their data efforts:
Data Democratization Is Paramount
For data and AI to truly become ubiquitous with an organization’s operating model, everyone — regardless of their role or team — needs to have appropriate access (and, with it, literacy and understanding) to the data they need to do their jobs and make decisions based on that data.
As we witnessed in 2020, we’re seeing a wave of change (that will continue in 2021 and beyond) as companies do not want to limit data and AI initiatives to any one business unit or team. We will continue to witness the explosion of data democratization (which will lead to more models in production and more high-value business outcomes) in the form of companies launching self-service analytics (SSA) as they scale AI. To truly transform an organization, leaders should consider SSA a global program so that data and analytics are not used in isolation but rather as a means to evoke collaboration and efficiency.
Dataiku customer La Mutuelle Générale used Dataiku to create a customer acquisition prediction system that allows the sales team to more effectively prioritize their prospects by providing two pieces of information to consider: likelihood of conversion and likelihood of recuperation of acquisition costs.
They are a prime example of data democratization, as the project didn’t just involve the data teams building the prediction system (both data intelligence and data analytics). To ensure the final product aligned with business goals and needs, the organization involved other relevant teams including marketing and sales, internal communications, and the customer accounts division. By using one platform to go from data to insights, various teams and user profiles were able to access data and contribute to the final product.
Similarly, when setting up any self-service data initiative, GE Aviation always works with business lines to make sure the needs of the business are incorporated into the project. To ensure ongoing success, they get even more people involved. They combine both grassroots efforts within the business and executive buy-in and support to increase selfservice program visibility, exposure, and word-of-mouth advocacy.
Striving for a Perfect Master Data Management (MDM) Is Counterproductive
Data cleansing efforts can undoubtedly be costly. However, contrary to what might be seen as the CDO’s core scope, he or she — in conjunction with the company’s line of business leads and IT executives — should orchestrate data cleansing on the data that fuels the most valuable use cases, and build out from there incrementally. In parallel, he or she should work to create an enterprise data ontology and master data model as use cases become fully operational.
Jeff McMillan, Chief Data and Analytics Officer for Morgan Stanley Wealth Management cited data quality as one of the decisive factors to becoming an intelligent organization. He said, “A lack of quality data is probably the single biggest reason that organizations fail in their data efforts.” To control data quality, organizations should be sure they have:
- A sound data quality infrastructure (and data quality from a broader IT perspective)
- Metrics around accuracy and what constitutes usable data
- A clear definition of what “quality” means to the organization
- People who are accountable for the accuracy and in charge of monitoring data quality on a daily basis
- Issues management control
A centralized data repository like Dataiku is a critical piece of the puzzle for building and supporting success with data quality. An end-to-end platform that can be used by everyone not only helps distributed or remote teams work more efficiently by providing one clear data resource point, thus increasing accessibility, but it also helps manage consistency and accuracy
Data Stewards Embody Data Management Efforts
As organizations strive to collect and capitalize on ever-increasing amounts of data, the importance of data fitness and governance is more critical than ever. You may have heard “data stewardship” used in this context. At its core, data stewardship is the management and oversight of an organization’s data assets to help provide business users with high-quality data that is not only easily accessible in a consistent manner but also compliant with policy and/or regulatory obligations. The task is usually a joint effort between IT, line of business data owners, and the central data office, if it exists.
In chaotic environments with highly distributed systems and projects, data stewardship promises a central point of contact for increasingly complex and growing data volumes. In companies where roles are vague, data stewardship assigns decision rights around data, enforcing accountability. In very political environments, data stewardship holds the promise of more ownership and visibility. There are different models of data stewardships, so the onus is on each organization to select the one that works for them.
Quality Is Step One, Reuse and Capitalization Are the Goal
Not only can data quality be the reason that a data project fails, but it can also be the driver behind significant resource drain (such as a data scientist being given data that is outdated or incorrectly labeled, leaving them forced to do extra data prep work instead of working on higher priority or more fruitful projects).
Data stewardship can play a significant role here — at its core, it’s the management and oversight of an organization’s data assets to help provide business users with high-quality data that is not only easily accessible in a consistent manner but also compliant with policy and/or regulatory obligations. This task is usually a joint effort between IT, line of business data owners, and the central data office, if it exists.
Therefore, companies should pay particular attention to data quality by establishing the right processes. The real value, though, will come when organizations set themselves up to encourage the reuse and capitalization of data and analytics. Not only will this avoid duplication of work, but will allow new ideas and use cases to come to the forefront. However, to see returns on investment (ROI) in AI projects at scale, it’s not enough to take on more use cases and stop there. Companies need to unlock ways to decrease both the marginal costs and incremental maintenance costs of Enterprise AI.
One Dataiku customer, a multinational bank and financial services company, has developed a data marketplace that people across the organization can use when they need to get answers from other datasets. For example, an analyst trying to understand the cost of property can use the balance sheet from the data marketplace and plug in lease data.
The model represents a unique take on a self-service data program where the center of excellence owns the core structured intelligence of the company, but enables other teams to build experiences on top of that data, relevant to their specific function or line of business. As a result, people from various teams around the organization can use the apps within the enterprise-level data and analytics marketplace to get their answers to day-to-day business problems, which not only gets more people using data on a regular basis, but does so in a way that is set up for long-term scalability.
System
Right Now, Organizations Should:
1. Start operationalizing their AI projects in parallel to their infrastructure transformation projects. They should think in terms of a platform to cover the data and analytics product’s full life cycle — design, orchestration, deployment, monitoring, alerting, training, and usage with confidence.
2. Experiment in agile mode, setting up formal and regular use case ideation and review sessions, iterating on as many ideas as possible for the bandwidth available.
3. Take a platform mindset — one platform with multiple instances to scale resources up and down in an elastic, responsible, and governed way. They should also target scalable compute and storage right away and let the platform handle the scalability, not the IT team.
4. Engineer multiple levels of deployments depending on needs, ensuring clarity on who touches what and putting a system in place to validate models before they go into production. In essence, they need to define an operating model that allows scaling across the business and favors collaboration across business, analytics, and IT stakeholders. This requires a strategic combination of tools and processes to work.
When discussing systems, we are generally referring to the data science technology landscape at large, the evolution of data science and AI tools, storage and compute, and deployment into production. In this section, we’ll share recommendations for how organizations can pinpoint the right technologies and processes to enable the end-to-end creation and use of AI-powered analytical applications.
Rationalization Efforts Require a Platform Mindset
Harmonizing analytics technologies across the organization has obvious virtues but is far from being trivial. It requires both completeness of needs being matched by one or a couple of technologies and those being recognized by lines of business, as well as the search for software that will cover the largest number of steps in the life cycle of the creation of a data and analytics product. Ultimately, only platforms fit that description, as they bring cohesion across those aforementioned steps and provide a consistent look, feel, and approach as data teams move through those steps.
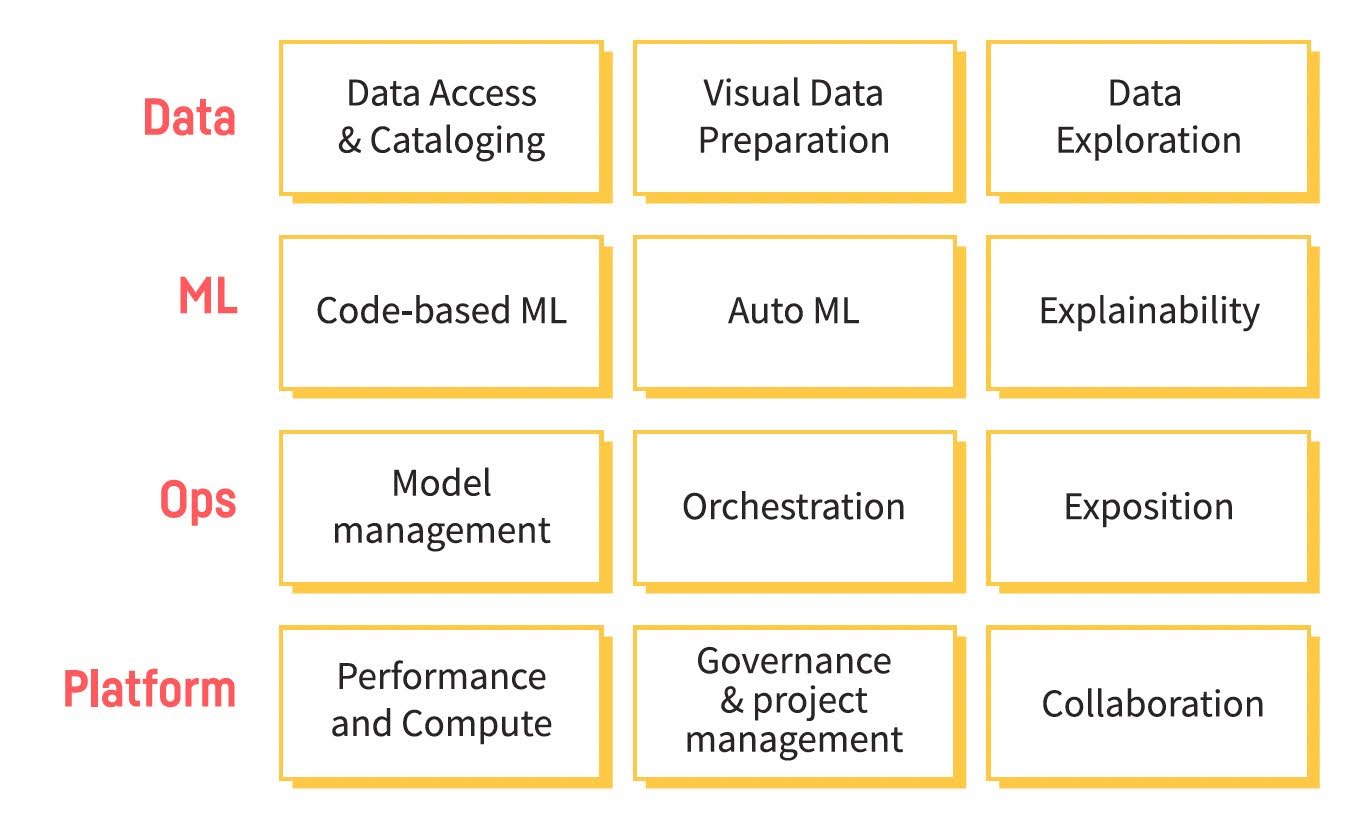
When building a modern AI platform strategy, it’s important to consider the value of an all-in-one platform for everything from data prep to monitoring machine learning models in production. The alternative, buying separate tools for each component, can be immensely challenging as there are multiple pieces of the puzzle across different areas of the data science, machine learning, and AI lifecycle — as illustrated in the image above. That’s not the only issue, though.
When moving between tools, other roadblocks include:
- Difficulty tracking data lineage across tools (which can bubble up to larger issues such as lack of visibility of AI processes or lack of model explainability, both of which can lead to trouble with the modelers themselves and auditors)
- More complicated handoffs between tools which take more time (not to mention the risk of losing critical information when moving projects from tool to tool
- Missed opportunities for automation between steps in the lifecycle
- No orchestration or clear way to manage approval chains between tools (which can lead to errors related to model fairness, data privacy, and more)
- No scalable approach to auditioning and versioning the various artifacts as they are pushed between tools
It doesn’t come down to simply the ability of the potential platform to be integrated with all current technologies, but about the company’s vision, culture, and overall strategy. Therefore, organizations should look for a holistic platform (like Dataiku) that can easily integrate new technologies, allows organizations to drive down costs due to the ability to reuse parts of or entire data and analytics projects, and helps them mitigate risk via sound governance facilitation and Responsible AI features.
Dataiku, the only end-to-end platform for data science and machine learning, provides:
1. Cost savings via reuse (such as data that has already been cleaned and prepared by analysts can be used by data scientists in other business units, avoiding repetitive work and bringing more ROI from AI at scale)
2. A focus on implementing high-impact technologies (which benefit everyone instead of needing to maintain the interplay between different tools for working with data across business units)
3. Seamless governance and monitoring (think risk mitigation, adherence to data privacy regulations, and formulating a sound operationalization strategy)
Avoid Technical Debt at All Costs
In an ever-evolving technology landscape, many large organizations succumb to purchasing the latest, shiniest piece of technology, many of which become obsolete before proving their value-adding layers of both complexity and costs. Being locked into a non-future-proof solution means significant upgrade costs in the future and limited infrastructure options, both of which can hinder growth. Further, building their own AI platform will not only pile on technical debt but is complex, as it involves cobbling together features outside of the core functionality of building a model which is not a smooth process.

According to a Google research paper on the topic, “The goal is not to add new functionality but to enable future improvements, reduce errors, and improve maintainability. Deferring such payments results in compounding costs. Hidden debt is dangerous because it compounds silently.” When organizations continue to add new tools and systems, not only do they generate more and more unseen debt, but they also might start creating a data pipeline that is more and more fragmented across different technologies.
How can organizations overcome this? Analytics and IT leaders’ objectives should include looking for future-proof technologies and decreasing existing technical debt. Analytics software should be tech stack agnostic and open enough so that change remains an option.
Think Operationalization From the Start
The ability to capitalize on what data has to offer hinges on a series of fundamentals. Broadly speaking, capturing the most value from the wealth of potential data begins with:
- Excellence in identifying, capturing, and storing that data
- Identifying the technical capabilities to analyze and visualize that data
- Complementing analytics with the domain knowledge of human talent
- Relying on a cross-functional, agile structure to implement relevant insights
- Putting adequate, but not burdensome, processes in place to drive appropriate behaviors
Ultimately, this process should end with the operationalization of the data and analytics product. Despite success in the earlier steps, projects can be reduced to nil if the operationalization requirements have not been thought through ahead of time.
Dataiku customer Heetch, a French ride-hailing app, uses Dataiku for operationalization — so far the team has pushed over 100 projects to production, driving daily business processes and, therefore, company-wide impact. Further, the team at Heetch uses Dataiku’s abstraction layer to leverage elastic resources in a way that allows good performance and avoids resource overconsumption.
Dataiku enables teams to operationalize data and analytics projects without compromising on security and auditability by enforcing the existing security measures setup in the data layer and enables fine-grained security access for the Dataiku projects themselves. Dataiku also enables full auditability of any data transformation operations.
Elastic Compute Should Not Make You Forget About Total Cost of Ownership (TCO)
There is no question that elasticity (i.e., on-demand compute resource management and flexibility) is the future of Enterprise AI. Companies need the ability to scale up and down resources depending on their needs. For example, with Dataiku organizations can:
- Push computation to cloud services and data warehouses
- Provide a unified way to run in-memory, machine learning, and Spark jobs on Kubernetes.
- Automatically scale computing resources up or down according to usage.
The development of elastic compute has therefore allowed organizations to adjust computing costs to their exact needs. However, focusing on these costs can be deceiving because it makes leaders less focused on value (i.e., it might seem like you’re getting a good deal only using what you pay for, but what value is the business ultimately getting from this spend?). It also distracts them from the costs associated with gluing together various tools needed for different phases of the data science lifecycle, which will ultimately hinder their ability to sustain long-term growth.
When organizations are running a TCO to determine the optimal data science and machine learning platform for their organization’s needs (and look beyond the value that is being promised), there are a few things to keep in mind. First, it is important to compare apples to apples. Are the solutions comparable from a capabilities perspective?
Next, the costs involved with each platform should be properly scoped. What should be included? What existing costs will be impacted by the platform? What costs will remain the same? Finally, run different customer scenarios, taking into account team size, team skill level, data needs, and complexity levels of varying analytics projects.
Talent
Right Now, Organizations Should:
1. Define and lead the initial effort for talent hiring, retention, and upskilling.
They can do so by building an environment that fosters cross-profile collaboration, optimizing existing talent through upskilling sessions, and investing in training, coaching, and support.
2. Design the best experience for their existing cross-profile workforce. Over time, they should:
- Empower non-technical users and subject matter experts (on top of their analytics experts) with the tools to enable them to collaborate and create artifacts together, despite a diversity of AI skills
- Create an internal user community leveraging AI super users, assigning power users to non-technical or new teams and leveraging them to enable the broader population
- Roll out the training and coaching program to demonstrate the organization’s investment in their staff
Delivering on AI and data objectives is not an overnight task, and many companies get stuck at one of the most challenging pitfalls — knowing who and what to look for when building teams and staffing initiatives. In this section, get the top four recommendations to ensure organizations find the right people, upskill and retain them, and create AI communities pocketed within the enterprise.
Focus on Non-Experts to Scale Out
Despite the efforts to train more AI experts (across academic, governmental, and corporate entities, for example), the truth remains: there is a lack of AI experts, particularly in less tech-savvy or sexy industries. As a result, enterprises can’t rely on experts alone when aiming for massive change. The democratization of AI within the organization will take time and can be thought about in three ways. First, setting up upskilling programs for different competency levels (a process that is unfortunately overlooked at most companies); second, setting the standards to allow more and more autonomy from non-experts; and third, creating an environment that drives and supports collaboration.

Dataiku customer Mercedes-Benz empowers the organization through knowledge sharing of analytics, providing users across departments access to data tools and visualizations relevant to them. In one instance, the data and analytics team aimed to forecast, analyze, and predict how the business was going to change in the future, particularly as it relates to financial KPIs. After working on more than 25 financial KPI forecasts (from univariate modeling to multivariate forecasting to automated forecasting), the team was able to put their findings into a software package. The package can be used by business users (who aren’t necessarily AI experts) to combine their expertise with cutting-edge machine learning.
Cross-Profile Collaboration Roots in Organizational Choices
Executives must consider a hybrid organizational model in which agile teams combine talented professionals from both the business and analytics sides of the house. A hybrid model will retain some centralized capability and decision rights, namely around data governance and other formal standards, but the analytics teams are still embedded in the business and accountable for defining and delivering business impact.
For many companies, the degree of centralization might change over time. For example, a company with a lower AI maturity may work more centrally, since it’s easier to build and run a central team and ensure the quality of the team’s outputs. Over time, as the business moves closer to embedded AI, it may be possible for the center to step back to more of a facilitation role, allowing the business more autonomy. Go deeper on best practices for centers of excellence in this white paper.
Structure Roles and Responsibilities
Analytics talent can be viewed as a combination of many varying skill sets and roles. Naturally, many of these capabilities and roles overlap — some regularly and others depending on the project. Each piece of that puzzle must have its own carefully crafted definition, from detailed job descriptions to organizational interactions, specifically along the AI product lifecycle.
To drive value, organizations need to be thinking of the future blueprint for scaling AI instead of just focusing on making it to the next day. One part of that is carving out the job roles they need now and will need in the future, identifying any gaps, and determining if they have anyone who can fill the role(s) internally (along with providing upskilling opportunities).
The CDO should work with HR executives to accomplish this, detailing job descriptions for the analytics roles that will be needed in the months and years ahead. They should inventory those currently within the organization that would meet the job descriptions (think capabilities, not job titles). Then, the remaining roles should be filled by hiring externally.
Your Employees Are Your First Customers
As mentioned earlier, every leader in the organization should take the time to understand AI and its potential business impacts. Then, organizations should take that a step further to empower the rest of their employees with training, which unfortunately is an underutilized tactic — only 27% of data professionals say their organization has formal training and education to help staff understand the roles data, machine learning, and/or AI play within the business.
Not only should the training involve a technology perspective (i.e., what is the technology and how is it used?) but from an applied perspective. While organizations may provide the tech piece, they miss out on the applied piece, which trains employees on how to use the tools to solve real business problems, identify what kinds of problems can be solved, etc.
For experts, training is a need to stay knowledgeable, with their finger on the pulse of dynamic, ever-evolving technology space. For non-experts, AI at scale requires such a dramatic shift that it requires time, energy, and resources behind it. Organizations should establish a bespoke, multi-step training program that is ingrained in the company’s strategy and culture, including a focus on hard and soft skills.
Governance
We want to preface this section by saying that we could write an entire guidebook on AI governance alone, so this section is by no means all-encompassing but rather scratches the surface on high-level governance recommendations.
Right Now, Organizations Should:
1. Ensure their data is of high quality (the complete lineage is traceable), usable (data can be readily found and permissions are documented), and secure (only those who should have access do).
In Dataiku, for example, all processes are visually mapped in the Flow, so it’s easy to understand the lineage of datasets back to their origin, including if they are shared as an exposed object from another Dataiku project. Dataiku projects are also under version control, so every action is recorded in a Git repository to ensure traceability and the ability to revert changes when necessary.
2. Aim to find a balance between audibility and permission management that doesn’t stagnate the organization’s efforts to accelerate its ability to use data at scale.
3. Ensure they are using tools that ensure audit trails (i.e., logs for user access and activity) for troubleshooting and compliance with internal controls and external regulations.
Sustainable governance and its associated processes seek to ensure all data initiatives are properly governed from a security and suitability perspective. As the amount of data continues to grow, this leads to more opportunities for analytics initiatives, more proofs of concept, more people involved, and more projects pushed to production and monitored.
To effectively scale and eventually reach embedded Enterprise AI, there needs to be trusted throughout the organization in the integrity of the data and analytics at each stage of the data science pipeline. However, that is easier said than done. According to an IBM survey on AI adoption, only 16% of respondents said that employees trust AI-generated insights. It goes on to say, “Since the nature of learning systems means they evolve unless business people are empowered to measure and manage the performance of AI doing work on their behalf, they will not trust the system to do a good job.”
Highly regulated industries even demand the documentation of processes behind machine learning models. Here are some recommendations for organizations aiming to accelerate their AI maturity when it comes to governance:
Risks Should Be Managed, No Matter Your Sector
As one element of a broader risk management program, the CDO should work with HR executives and the company’s business ethics experts and legal counsel to set up testing services that can accurately and quickly expose and interpret the secondary effects of the company’s analytics programs. Data translators will also be critical to this effort. The organization’s leadership needs to grasp the range of possible negative uses and impacts of AI and take a stand on Responsible AI and its associated strategy and execution.
Build Reliable and Resilient AI Assets
Organizations should make sure their data and analytics strategy — including any models in place — are resilient during moments of disruption (new technology, economic turndown, new competition, or environmental disaster, to name a few). Dataiku allows people across an organization to access all data and work together on projects in a central location, facilitating good data governance practices combined with widespread vertical and horizontal collaboration.
During the health crisis, large, multinational Dataiku clients (such as GE and Pfizer) avoided machine learning operations disruptions due to their data-driven culture and global distribution. They simply use VPNs and web browsers to access data, projects, and colleagues via Dataiku, enabling granular levels of control and the ability to trace every aspect of machine learning as organizations empower more employees to leverage the power of AI.
Conclusion
For any organization to make their AI program a success — so much so that it is less of a formal program and fades in the background as entrenched with the organization’s business model — they need to be set up with the right capabilities. Whether an organization is just starting on the mission to improve and accelerate its AI maturity or is determining how to scale a specific element such as governance or talent, here are helpful steps to keep in mind:
- Set the enterprise-wide vision for AI, including goals and desired outcomes
- Ensure global adoption and lay the groundwork for value quantification (and communication of that value)
- Equip the users with ongoing training and coaching, instead of ad-hoc enablement
- Structure the processes to create data and analytics products at scale (think core concepts such as operationalization and capitalization)
- Ensure an optimal user experience for everyone, so they remain excited to continue using data and analytics to drive work efficiency and productivity
By following the steps outlined in this guidebook, organizations will be poised to keep pace with the ever-shifting landscape of data, analytics, and AI. With more models, deeper insights, and more potential for organizational growth and transformation, it’s critical that organizations have a sound framework for creating and maintaining business value from their data and analytics projects.