Learn about the history of data governance, best practices for implementation, the business value data governance can bring to your organization, and how a platform can enable your data governance initiatives.

Topics covered include:
- Benefits and business value of data governance
- Essential data governance capabilities
- Data governance frameworks for success
Anyone looking to drive business value from data or gain more insight into data governance for job roles, such as a data steward, will benefit from this article. No previous knowledge of data governance is required.
So get ahead and start now.
Intro to Data Governance
Table of Contents
- Intro to Data Governance
- What is data governance?
- History of data governance
- Knowledge check
- Data challenges
- Knowledge check
- Data governance enables
- Knowledge check
- Data governance maturity model
- Data Governance Strategy
- People
- Process: DataOps Cycle
- Policies
- Process: Zone-based Architecture
- Process: Governance Models
- Platform
- Knowledge Check
- Data Governance Capabilities
- Discover and catalog your data
- Knowledge check
- Understand and trust your data
- Use and share your data
- Knowledge check
- Avoiding risk with your data
- Knowledge check
- Data Governance Framework
- How to get started
- Define working metrics
- Governance execution framework
- Knowledge check
- Prioritizing a use case
- Defining functional requirements
- Knowledge check
- Governance at scale
- The Value of Data Governance
- The value of data governance
- Budget considerations
- Real world success story: Alexion Pharmaceuticals, Inc.
What is data governance?
Data Governance explained…
Data governance is an integral part of data management, focusing on building trust, availability, accessibility, and compliance of an organization’s data assets. It is based on internal data standards and policies, ensuring organizations are compliant with any data privacy or industry regulations. With data governance practices in place, enterprises can guarantee that their data assets are consistent and trustworthy for data citizens to use for analytics, AI/ML, and business decision-making.
What Data Governance is not
It is important to note what data governance is not. For instance, if an organization stores its data in a central repository or data lake, it doesn’t mean they have incorporated governance practices into the data environment. Controls on who can access certain types of data, what types of processing can be done on the data, and standards around data privacy and quality are vital components of data governance.
Data governance is not a one-time project or practice applied all at once; additionally, data governance projects should not be solely designated for IT teams to fulfill. Instead, data governance is an ongoing cycle and collaborative effort across multiple teams. As a result, data governance programs are often implemented gradually and strengthened over time once an organization finds its best practices for current use cases and future goals.
History of data governance
Data governance has historically had a negative connotation.
Traditionally, companies focused on building enterprise data environments for analytics and business intelligence but didn’t have the proper tools or practices in place to efficiently implement data governance.
Technical components required to enable data governance practices and use cases, like regulatory compliance, data privacy, and data quality, were often overlooked.
Mostly, data governance was an afterthought. It wasn’t always considered until something broke, went wrong, or there was a data breach.
Below are common implementation mistakes which result in negative assumptions surrounding data governance.
Data protection was an afterthought
Organizations built a database or a data lakehouse first and then considered the necessary security protocols after the fact. Companies often assume that protection could happen later by somebody else rather than considering it prior to a build. Instead, the organization could get ahead and avoid issues that otherwise could be prevented.
Lack of job clarity
When there is no specific function defined for a governance role, employees are at a detriment because they are not provided with the proper clarity to understand what skills are necessary to do their job efficiently. Additionally, it is common for employees to assume that governance is a part of another co-worker’s job role, so the lack of confusion about who implements and manages governance adds to the confusion.
Zaloni teamed up with Dataversity to create “The 2022 State of Cloud Data Governance” white paper that reports on several survey questions based on the responses of data professionals across several industries. For example, one of the survey questions asked, “Who is responsible for executing and managing data governance within your organization?” Below is a snapshot of the top survey answer where you’ll see the variation in responses:

Hinders data agility
When tasks are unclear to employees and they don’t know how to implement specific processes, there is often a hindrance to progress. For example, a wildly known myth around data governance is that it slows time to insight and hinders agility for the organization. In actuality, data governance does the opposite by providing the security and controls needed to rapidly deliver high-quality, secured data, ultimately allowing organizations to experience accelerated time to insight.
Neverending regulations
Without the proper policies and security in place, it makes an organization’s data more susceptible to violating industry regulations. There is an abundance of common compliance laws for data privacy and security, including GDPR, CCPA, and HIPAA, to name a few. However, organizations without a holistic approach to data governance cannot quickly react when revisions to current laws or new laws are passed, leaving companies vulnerable to non-compliance events.
Painful to implement
Frequently, organizations don’t have the proper understanding of where to start because implementing governance is relatively new. There are few existing frameworks and examples that organizations can reference, so the lack of knowledge and resources creates difficulty.
Additionally, every organization has a unique data tech stack. The complexity of these tech stacks can make governance implementations tricky, especially if different teams or departments use different tools or technologies.
Siloed business units
Siloed business units that are not aligned on the processes, technologies, and people that drive governance initiatives can hold back an organization from reaching success. For example, it’s not uncommon for employees to become protective of their data and only think of their use cases as priorities. Understandably, not everyone likes change, but the absence of a holistic and enterprise-wide approach to implementing data governance becomes more problematic and complex across the siloed business units.
These can be avoided with the proper understanding of data governance
Ultimately, modern data software and tools must promote data governance as a foundation for securely and rapidly delivering analytics, AI, and ML use cases, improving overall efficiency, accelerating time to insight, and ensuring data quality.
Knowledge check
Previously, you were given a list of the reasons companies have struggled with data governance. Remember, they are notable for understanding why many companies have a negative connotation of data governance.
For this knowledge check, match each reason to the correct description.
- Delayed Protection: Organizations build a database or a data lake house first and consider the necessary security protocols after the fact. There is often an assumption by companies that protection could happen later by somebody else rather than considering it prior to a build.
- Lack of Role Clarity: When there is no specific function defined for a particular role, employees are at a detriment because they are not provided with the proper clarity to understand what incentives or skills are necessary to do their job efficiently.
- Hinders Data Agility: When tasks are not clear to employees and people or organizations don’t have the clarity of how to implement certain processes, then there is often a hindrance to progress and a perception that data governance delays time to insight.
- Compliance: Without the proper policies and security in place, it makes an organization’s data is more susceptible to violating compliance laws or requirements.
- Painful to Implement: When the plan or project for establishing data governance within an organization is not clear or the organization has a complex technology stack implementing data governance becomes difficult
- Siloed Business Units: Internal teams and business units are disjointed and not aligned on the governance initiative, holding back the organization from reaching success.
Data challenges
Insights into the state of data governance in 2022
Zaloni teamed up with Dataversity to research and report on the state of data governance within the industry. The following survey discovered:
- More than two-thirds of respondents said a lack of understanding of governance is the biggest challenge.
- The three most significant challenges in implementing data governance in the cloud are skills to manage new cloud technologies, growing cloud ecosystem complexity, and increased data sprawl.
- Data quality, data catalogs, and business glossaries are the top three data governance capabilities organizations need most.
To elaborate on the data challenges found in this survey, use the set of flip cards to review the six common data challenges.
- Data Sprawl & Silos: As data technology stacks grow, data may exist in databases, SaaS applications, or other environments that are isolated from the organization’s primary data environment creating data silos within the organization.
- Lack of Self-Service Data Access: Data citizens, such as data scientists or analysts, lack the ability to access data in a self-service manner resulting in slow time to insights and completion of ML/AI projects.
- Inconsistent Data Governance: Companies face challenges standardizing governance and visibility across tools to ensure data quality, PII/sensitive data protection, and control data access.
- Fragmented Observability: Due to complex data technology stacks and data sprawl, full data observability is difficult leading to inefficiency and security risks.
- Lack of Automation: Data management processes for storing and processing data, and applying data governance policies are not automated, creating time-consuming and repetitive tasks for IT teams, data engineers, and data stewards.
- Knowledge Gap: The difference in workers’ skills and expertise across an organization creates a gap between what an organization needs and what the current staff can do.
Think about the data challenges your company may face.
Knowledge check
As described in the previous section, there are several data challenges an organization may face. For this knowledge check, determine which data challenge statements below are true or false.
- Fragmented observability is the data literacy, data-driven culture, and the knowledge gap with modern data architectures that remain a challenge for most companies today.
- The knowledge gap is the difference in workers’ skills and expertise across an organization that creates a gap between what an organization needs and what the current staff can do.
- Data citizens, such as data scientists or analysts, who cannot access data in a self-service manner will experience a slow time to insight and incompletion of ML/AI projects.
- Companies with inconsistent governance have the proper visibility across all tools to ensure data quality, PII/sensitive data protection, and control data access.
Data governance enables
In this section, we’ll cover seven common data governance use cases. Each arrow in the graphic below represents a different use case. The arrows create an ongoing cycle, symbolizing how data governance use cases overlap and how data governance practices actively enable new use cases and benefits for an organization.

- Data Marketplace: Where data citizens go for self-service access to different types of data across various sources. Data Governance practices ensure all data accessed is secure and trustworthy.
- Customer 360: A 360 degree view of a single customer’s data can be used to improve marketing and sales effectiveness and customer experience. To create a Customer 360 view, disparate data sources must be matched and merged into a single customer view. In some cases, without a unique identifier available. Governance rules and workflows can be established to speed up the matching process and ensure the highest data quality and accuracy.
- Increase/Improve Data Analytics: With proper data governance practices in place, companies can increase time to analytics and have access to trusted data in a timely manner for analytics that empowers data-driven decision making.
- Risk Management: With proper data governance practices in place, companies can increase time to analytics and have access to trusted data in a timely manner for analytics that empowers data-driven decision making.
- Cloud Migration: The scalability and flexibility of the cloud opens the door for improved efficiency and reduced costs. Migrating and establishing a cloud environment allows for a data governance foundation that enables control and security across a data enterprise.
- Data Monetization: Companies should be able to utilize and view their data as an asset. Data Governance is the catalyst for data monetization, where data can be leveraged for economic benefit and help grow business revenue.
- Regulatory Compliance: Pertains to the federal, state, or international laws or policies that a company must abide by. With the many different types of regulations in place, governance processes can provide regulatory compliance peace of mind.
These are some of the common data governance use cases we have implemented with our customers. Some of these use cases will be described in greater detail throughout this course!
The benefits of data governance
So how does an organization benefit from data governance and the use cases described? That’s a great question! There are several outstanding benefits worth discussing that an organization can experience when establishing data governance.
- Data-Driven Decision Making: Through trusted, accurate analytics and reporting, businesses are able to make data-driven decisions that improve efficiency and maximize business performance.
- Data Trust and Integrity: Data citizens can have access to accurate, consistent, timely data that they can trust to use for analytics, AI, and ML use cases.
- Reduced Time to Insight: Data governance can make self-service data access a reality, reducing time to data delivery and accelerating time to business value.
- Reduced Risk: An organization can experience reduced risk across the board knowing their data is high-quality, secure, and in compliance with internal policies and external regulations.
Knowledge check
Which of the following is a benefit of data governance?
A. Regulatory Risk
B. Lack of Compliance
C. Reduced Time to Insight
D. Delayed data delivery
E. Poor data quality
Answer:
C. Reduced Time to Insight
Data governance maturity model
Where are you in the model?
Below is a chart that explains the different stages of where companies are in their data governance journey. This can be a helpful insight into understanding how far your company has come with data governance and what phases you can work towards.

The Maturity Phases Explained
Each stage describes specific data characteristics to depict each stage of maturity and the business impact of each stage:
- Unmanaged: Typically, companies start in an unmanaged state with limited visibility and are mainly using their data for ad-hoc reporting or analytics.
- Characteristic:
- Limited visibility, governance and usability of data
- Emphasis on retrospective reporting
- Business Impact:
- Ad-hoc and siloed insights, slow time to analytics
- Characteristic:
- Managed: Once they begin implementing data management, they are able to improve data visibility and understanding through technical metadata and cataloging.
- Characteristic:
- Data discovery for various enterprise datasets
- Improved understanding via technical metadata
- Business Impact:
- Improved visibility and control, reduce duplication of data
- Characteristic:
- Operationalized: Once proper data management is in place, companies may begin operationalizing many of the steps in the data supply chain, improving efficiency and reducing costs.
- Characteristic:
- Reusable data pipelines
- Automation, CI/CD of data pipelines
- Business Impact:
- Supply chain efficiency reduces operating costs, reduce duplication of effort
- Characteristic:
- Governed: With operationalized data management in place, companies can begin to focus on various aspects of data governance, such as building and implementing data privacy and quality policies to make trusted data accessible in a self-service manner, ultimately reducing time to insight.
- Characteristic:
- Data quality
- Data profiling and Classification
- Security – masking and tokenization, RBAC
- Self-service provisioning
- Business Impact:
- Trusted data with Standardized governance and self-service accelerates time to insight
- Characteristic:
- Augmented: The final stage is leveraging ML and AI techniques to improve automation and efficiency, creating a frictionless delivery of trusted data to end-users and improving employee productivity.
- Characteristic:
- Self-improving DataOps via ML and AI
- Intelligent data remediation/curation
- Automatic data classification
- Data insights
- Business Impact:
- Frictionless delivery of timely, trusted data improves Al/ML and analytics outcomes
- Characteristic:
Not all data governance journeys are alike, and there are many variables and unique challenges a company may face. This model provides a high-level progression that companies typically follow on their path to maturity.
Data Governance Strategy
This section will cover the 4 P’s of data governance and why they are critical components for achieving enterprise-wide data governance success.
What are the four P’s of Data Governance?
A successful data governance program requires a mix of people, processes, policies and platforms.
We have broken down data governance into what we describe as the “4 Ps”:
- People
- Processes
- Policies
- Platform
Each of these pillars is a critical component of modern data governance. With the right balance of each, companies can experience an array of benefits.
In the following sections, we will dive deeper into each one.
People
People are a vital part of data governance as the workforce’s knowledge and skills contribute to the success of implementing data governance and propelling their data governance journey further. Therefore, the organization’s employees should be split into roles and teams to make data governance effective.
Teams: As simple as a collection of employees, data governance should be carried out by a team of people. By doing so, teams can carry out daily governance tasks and collaborate on executive decisions around what’s best for the organization’s governance initiatives. Some organizations build a data governance council or center of excellence with representative members across various lines of business.
Roles: Data governance responsibilities are often lumped together with another role, but making it a role of its own can be far more beneficial. Designating roles to each team member allows for a clear understanding of the expectations of each person and what they are expected to accomplish on a daily and long-term basis with the company.
Establishing governance with a RACI Matrix
This type of matrix is used as a tool to help a company establish roles and responsibilities when building a data governance program within their organization.
An example of a RACI matrix for data governance is below:
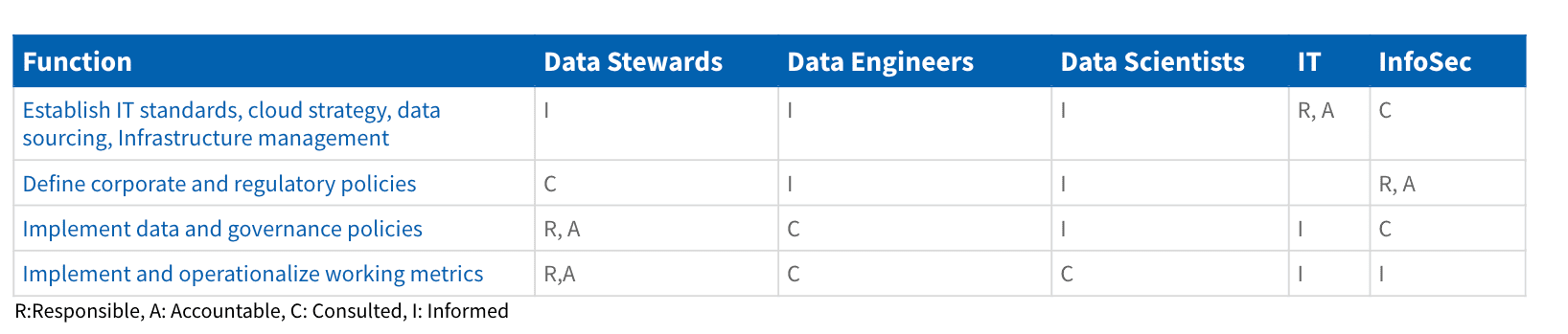
RACI stands for responsible, accountable, consulted, and informed:
- R: who will do the work (responsible)
- A: who makes final decisions and/or owns the service (accountable)
- C: who should be consulted prior to any action or decision (consulted)
- I: who should be notified of actions or decisions (informed)

Data stewards and data engineers
Data stewards and data engineers are critical positions to fill for data governance teams. Data Stewards oversee data governance processes within the organization and are responsible for ensuring data quality and how to utilize that data to its fullest extent.
On the other hand, data engineers are looking at company data to understand the requirements to build a data platform that best suits the business needs and goals. Data engineers are the employees who are responsible for building data pipelines and understanding how to maximize the efficiency of those pipelines.
Ultimately, data governance allows for better collaboration across both roles for a win-win.
You will learn more about this from the DataOps Cycle next!
Process: DataOps Cycle
Next, let’s take a look at one of the three processes involved in the implementation and management of data governance.
DataOps Cycle
We think of data governance holistically and as an integral piece of the data management foundation. Our recommended methodology for data management is DataOps. DataOps is the data management practice that views data pipelines as an end-to-end data supply chain that requires the proper visibility, controls, and governance of every step from a data source to the end-user, or data consumer.
DataOps draws inspiration from lean manufacturing and the agile nature of DevOps. This method of data management focused on optimizing the end-to-end data supply chain. Ultimately, DataOps provides:
- A “single pane of glass” that connects people, processes, and platforms through one collaborative view
- Agility and extensibility, bringing together 1st and 3rd party data pipelines
- A continuous cycle that improves and becomes more efficient over time
In the diagram below, you will see our version of the DataOps cycle. At the top of the cycle, data is coming into the intelligent data catalog. On the left side, you see the steps the data goes through once it’s cataloged. Data is profiled and classified, data quality is checked, metadata is applied, and lineage is tracked. Typically, these tasks are performed by a data engineer or data steward. On the right side of the cycle, you see the typically performed tasks by data citizens such as data analysts or scientists. You’ll notice they are also accessing the data catalog to shop and provision data. Metadata from the AI/ML or analytics tools is fed back into the catalog, providing observability and insights to support continuous improvement. You’ll see that the entire cycle has data governance as the backdrop, and it should be applied at each step of the cycle.

Policies
Policies are a set of rules in place to establish standards for data quality, security, privacy, usage, and data access. Governance policies help governance teams define and enforce data governance across the organization.
Below is a list of the most common governance policies:
Security
Data security is the means of securing and protecting data from unauthorized users. Data security policies guide security processes for data storage and movement.
Data Quality
Data quality rules can be established to determine if data is fit for use and if not, what needs to be done in order to make it acceptable for use.
Access Control
Administrators control which users have access to which data sets and types of data within a given environment.
Role-Based Access Control
Role-Based Access Control provides administrators with the option to designate a set of restrictions or a certain amount of access to types or amounts of data based on role title.
Data Privacy
Data privacy rules can be used to ensure certain types of data, such as PII, is protected.
Masking, also known as data obfuscation, hides original data with modified content to protect classified or personal information.
Tokenization is the process of substituting sensitive data with another ID element. The new ID element is known as a token and allows a user to safely access or retrieve sensitive data. See the screenshots below for an example of data before and after data quality rules have been applied.
Here you can see the original data with all data exposed:

The next view shows the same preview of the data but with the phone number masked and email tokenized:

Let’s review these next.
Process: Zone-based Architecture
EndZone Governance
Zone-based architectural approach, also known as EndZone Governance™, can be designed to isolate data as it moves through a data pipeline from a raw zone to a trusted and finally to a refined zone where data can be transformed into trusted data ready for secure abstraction by data consumers. Below is a visual representation of the EndZone Governance and the processes that occur within each zone, along with the roles that would most likely interact with each.
When it comes to data governance, a zone-based architecture simplifies data movement and access at various stages of a data pipeline. For example, only a data steward or engineer may have access to the raw data containing sensitive information that is located in the raw zone. As governance policies are applied and data is protected, data moves into the trusted zone where users, such as data scientists, can find the data and begin data enrichment. Once the data is enriched and ready for end-users, it can be moved to a refined zone where access is provided to data analysts.
Each zone can have its own set of rules and policies, simplifying data governance enforcement.

The next section will cover governance models.
Process: Governance Models
Centralized, Decentralized, and Hybrid Data Governance
There are a few different types of governance models that organizations can choose. Although every organization is unique with its own set of use cases and goals, the chosen data governance model should be based on its current needs, prioritized use cases, and current governance practices (if applicable).
Below, learn about the three different governance models:
- Centralized Data Governance: One or multiple primary persons or teams are responsible for managing and maintaining data and building and enforcing data governance policies. Data citizens make requests to access certain types of data, and the centralized governance team or unit manages those access requests and the overall data repository. In a centralized model, it’s easier to ensure data security and policy compliance.
- Decentralized Data Governance: In a decentralized data governance model, individual teams or business units own, manage, and govern their data. Data citizens are able to freely access, manage, or use data without having to input access requests to another person or unit.
- Hybrid Data Governance: In some cases, an organization may take a hybrid approach and leverage aspects of centralized and decentralized data governance models. For example, there may be a centralized unit for building data governance policies, but the individual business unit or team is responsible for following and enforcing those policies.
In our 2022 State of Data Governance report, our survey found that hybrid governance models were the most popular with 35% of respondents saying that was how they executed data governance within their organization.

Platform
Last, but certainly not least, the platform provides the capabilities required to orchestrate people, policies, and processes, serving as the foundation for a company’s data management practice.
Consider a single, unified platform
Not all platforms are created equal; finding a single data platform that provides end-to-end data governance capabilities is critical to standardizing data governance at every step in the data lifecycle. Below you will see a diagram of a typical data lifecycle and the roles associated with each step. A unified governance platform can enforce governance policies and track lineage across the end-to-end lifecycle.

In the next section, we’ll dive deeper into these capabilities that are essential to modern data governance platforms.
Knowledge Check
Is the statement below true or false?
- A unified, end-to-end governance platform provides all of the governance capabilities to govern data throughout the data lifecycle: True
- Point solutions provide all capabilities required for modern data governance: False
Data Governance Capabilities
This section explains the different capabilities organizations should consider when evaluating tools to implement data governance.
Discover and catalog your data
Discovering and inventorying your data is one of the first steps in proper data management and governance.
Below is a list of capabilities to help organizations discover and create a catalog of clean and reliable data.
- Catalog: Provides an inventory of an organization’s data and data-related assets that are available for analytics, reporting, and data science. Data catalogs provide detailed technical, operational, and business metadata along with tools that help users search, find and understand data sets.
- Data Discovery: The ability to crawl and scan data sources on-prem, in the cloud, or in SaaS applications to discover data that’s available for cataloging.
- Data Ingestion: Data ingestion is where data is moved from one or multiple sources to another environment where it can be stored and analyzed. Data can be ingested and processed in batch and streaming, plus data ingestion procedures can be scheduled and automated as needed.
- Custom Metadata: Custom metadata attributes allow companies to establish custom metadata fields to improve metadata consistency and promote knowledge-sharing and collaboration across users and teams.
- Business Glossary: A business glossary is a searchable collection of data terms, their definitions, and characteristics. Business glossaries drive a consistent understanding of metadata by adding business context.
Knowledge check
Choose all that apply to custom metadata attributes.
A. Allow companies to establish custom metadata fields.
B. Custom metadata attributes provide metadata consistency.
C. Custom metadata is a difficult practice to implement.
D. Custom metadata decreases time to insight.
E. Custom metadata promotes knowledge-sharing and collaboration across users and teams.
Answer:
A. Allow companies to establish custom metadata fields.
B. Custom metadata attributes provide metadata consistency.
E. Custom metadata promotes knowledge-sharing and collaboration across users and teams.
Understand and trust your data
This section will provide detail on the capabilities that help companies trust and better understand their data. Improving data quality is considered one of the key objectives of governance by many industry professionals.
The Dataversity poll showed that 83% of companies list data quality as the most crucial data governance capability.
Below you will find more information on common data governance functions:
- Data Profiling: When data is cataloged or ingested, data profiling can be run to provide statistics and insights on the data, such as the number of records, number of null records, number of distinct records, and the data types.
- Data Classification: A process for organizing data into defined categories. Data classification may also be used to flag sensitive data to improve data security and privacy. Data quality rules are an example of how an organization may classify its data. For instance, a data quality rule could be applied to a data set containing information on different customers. Hypothetically, let’s say this data set included the customer’s first and last name, zip code, and email address. A data engineer could apply a data quality rule to that data set that enforces a specific 5-digit zip code and that data set would then be categorized based on that given zip code. Applying data quality rules like this can help sort out data that may be inaccurate or not needed for a specific project.
- Data Quality: Relates to the overall state and usability of a dataset. A data governance platform should allow companies to easily build and apply data quality rules, and provide data remediation to ensure accurate, high-quality data is available for analytics, AI, and ML.
- Data Mastering: The process of matching and merging internal and external data sources to create a single master record. This master record is often considered the “Single Source of Truth” for many companies.
- Data Lineage: From data creation to consumption, data lineage tracks and records every action taken upon data throughout its lifecycle. Data lineage shows what has happened to data over time and who has accessed the data. See an example of a data lineage graph below:

Having the ability to use and share data is critical for any organization. A data catalog or data marketplace can provide a self-service experience for data citizens to easily find and share data.
50% Time reduced to integrate data delivery and improve the productivity of data teams by 20%.
Below you will find the governance capabilities that help to reduce time to data delivery and improve team productivity.
- Self-Service Data Marketplace: A curated catalog of certified data that users can access in a self-service manner. Users can search, preview, and provision data through a simple shopping-cart experience.
- Data Access Requests: Users can request access to data from the data owner. Once access is approved, a user will be able to see the data preview and provision the data to the destination of their choice.
- Data Provisioning: Users can provision data from within the data catalog into a sandbox environment or to a BI, AI, or ML tool in a self-service manner, reducing time spent by IT or data engineers to provision the data.
Knowledge check
Select which statement describes a self-service data marketplace best.
A. The ability to move data into a sandbox environment or to a BI, AI, or ML tool.
B. An inventory of an organization’s data.
C. A curated catalog of certified data that can be accessed by users in a self-service manner. Users are able to search, preview, and provision data through a simple, shopping-cart experience.
Answer:
C. A curated catalog of certified data that can be accessed by users in a self-service manner. Users are able to search, preview, and provision data through a simple, shopping-cart experience.
Avoiding risk with your data
Companies have access to an array of functions and practices that could prove useful in combating potential risks with their data and staying compliant with the multitude of data regulations and laws.
Data can be a risky business.
It’s important to note the potential dangers that can occur if a business does not comply with the various laws and regulations surrounding data and data privacy. If there is a data breach within an organization, for example, there is a lot more at risk than just a hefty fine. On top of the average 15 million fine for a violation of compliance, that company’s reputation is also on the line. Customer’s who once trusted that particular company pre-data breach might easily change their mind and take their business elsewhere, ultimately raising the customer churn rate for the organization.
As mentioned in the first chapter of this course, there is a growing number of new regulations and laws around data security and privacy, plus the numerous additions and revisions to the regulations and laws currently in place. Companies must act proactively to avoid regulatory risk by implementing data governance.
Below provides greater detail on capabilities to manage data securely and meet security and privacy requirements.
- Policies & Rules: Policies and rules around data quality, data privacy, access controls, and more can be built and enforced within the data platform to ensure security and compliance.
- Role-Based Access Controls (RBAC): Role-Based Access Control allows companies to control which users have access to data based on their role. Each role has a predetermined level of access and can be applied to a group of users.
- Zone-Based Architecture: Where the data architecture is established in zones to better manage data movement, security, and access at each stage of the data pipeline.
- Tokenization & Masking: Sensitive data can be tokenized or masked to ensure data privacy while allowing users to safely access or retrieve sensitive data. Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry’s standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book.
Knowledge check
Select true or false for the statements below.
- RBAC stands for Role-Based Access Control.
- Data that is not sensitive should be tokenized and masked.
- Policies and rules are built and enforced within a data platform to ensure security and compliance.
- Zone-based architectures help companies better manage their data movement, security, and access at each stage of the data pipeline.
Answer:
- RBAC stands for Role-Based Access Control: True
- Data that is not sensitive should be tokenized and masked: False
- Policies and rules are built and enforced within a data platform to ensure security and compliance: True
- Zone-based architectures help companies better manage their data movement, security, and access at each stage of the data pipeline: True
Data Governance Framework
This section provides information on executing a data governance framework within an organization, including defining success metrics, utilizing AI/ML to scale governance, and budget considerations.
How to get started
Whether you have already started your data governance journey or are starting from scratch, we recommend following the process below to get started on your data governance initiative or new project.
Step 1: Define Working Metrics
Best practices and industry trends are useful, but don’t let that overwhelm you.
Start with 3 to 4 working metrics that make sense for your business.
Step 2: Establish the Right Culture
Establish a data-centric culture where people feel comfortable surfacing data problems and management is open to embracing them and collectively prioritizing to address the problems.
Identify roles and define a RACI matrix across data stewards, data engineering, IT, InfoSec, and analytics.
Step 3: Develop a Governance Execution Framework
Develop a logical diagram to reflect data flow, security controls, metadata, and data consumption.
Identify applications that interoperate within the ecosystem.
Step 4: Execute 1-2 use cases to establish benchmarks for your working metrics
Prioritize use cases, implement tools and technology, and establish working metrics benchmarks.
Celebrate success!
Next, let’s look at how to define working metrics for your data governance project or initiative.
Define working metrics
Before metrics are defined…
The first thing companies must do prior to defining their working metrics is to have a clear understanding of where they are in the data governance maturity model.
For your convenience, find the model below.
Data governance maturity model
As we discussed and showcased previously, this model helps companies recognize where they are in their data governance journey.
Remember, each company will be starting at a different place when building out its modern data governance platform, tools, and overall plan.
Project planning
The company should start by defining working metrics. Defining metrics helps a company pinpoint what they are trying to achieve with their data and, ultimately, their data governance initiatives. An organization should figure out 3 to 4 success metrics that make the most sense for current objectives and have viable benchmarks to measure the success of designated company goals.
Let’s dive into some examples of different metrics. The metrics below show various ways to measure success for common data governance objectives. The front of each flip card states the data governance objective, and the back defines one or multiple metrics that a company should consider for each.
Data Discovery and Visibility
- Time to find a data asset (i.e. source, destination, active users consuming the asset)
- # of days to onboard a new data source or application to support new use cases
Trust and Transparency
Establish a trust score (e.g. 80%) for the following data quality dimensions:
- Completeness
- Uniqueness
- Timeliness
- Validity
- Accuracy
- Consistency
Information for Use
- # of days between requests by a data citizen and fulfillment of data within their requested tool
- # of active assets (Data, reports, ML models)
- # of incidents to minimize business impact due to change in data source or pipelines
Avoidance of Risk
- Auto detect # of threats for non-pseudonymized PII and sensitivity attributes
- # of data assets covered by policy type (access, GDPR, etc.)
Governance execution framework
A data governance execution framework shows the data flow and all of the data functions that are interconnected across a data ecosystem. Companies normally create this framework when they are ready to develop a program structure or a project plan.
The diagram below represents a common data flow, and each icon below represents a governance function that takes place. By hovering over each icon, read through a list of different governance actions that may take place within each function.
Note that with a RACI model mapped out, that can help companies designate what each role is responsible for a specific function.
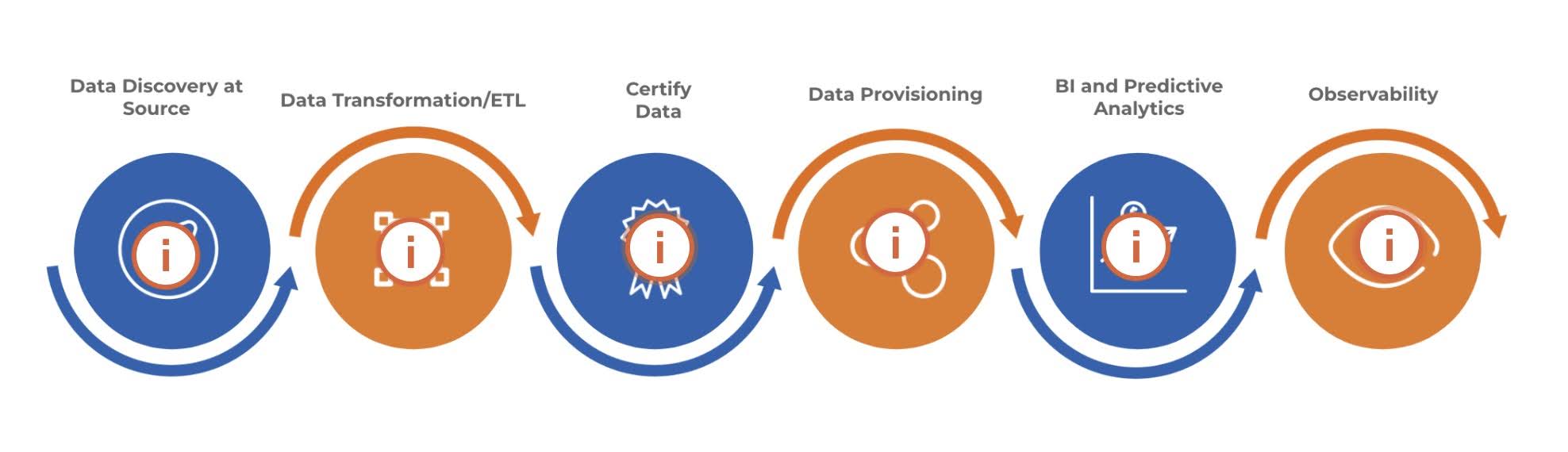
Data Discovery at Source
Actions:
- Catalog technical metadata using predefined connectors
- Augment business metadata
- Profile data and provide rules to curate data
- Classify Data
Data Transformation/ETL
Actions:
- Data Transformation/ETL
- Develop persistent schema
- Ingest data
- Build data pipelines and transformations
- Optimize performance
Certify Data
Actions:
- Update catalog with tables created in database or lakehouse
- Pseudonymize data
- Create a business glossary/glossaries
- Certify data
Data Provisioning
Actions:
- Requests certified data
- Requests are approved within existing ITSM tool
- Governance platform provisions data without duplicating data
BI and Predictive Analytics
Actions:
- BI and analytics reporting
- Predictive model development
- Model Deployment
Observability
Actions:
- Capture report and model metadata systematically
- Combine lineage from source, database, provisioning, and report metadata
Interconnecting data governance functions and roles
With a better understanding of what is expected in each function, it’s time to consider the roles that could be associated with each and an estimated amount of time spent for each function. By designating roles to a specific function, companies are providing the job role clarity, aligning business units with a shared vision and understanding, and establishing a solid framework to build out future governance initiatives.
On the flip cards below, we have listed three different job roles, and the associated functions are listed on the back with an estimated time spent. Remember, every organization is unique, so the functions for each role and the time expected for them to spend can vary based on the organization’s preference.
Data Engineers
- Functions (Time): Data Transformation/ETL (25% time spent)
Data Scientists
- Functions (Time):
- BI and Predictive Analytics (30% of time spent)
- Data Provisioning (5% time spent)
Data Stewards
- Functions (Time):
- Observability (5% time spent)
- Certify Data (15% time spent)
- Data Discovery at Source (20% time spent)
Knowledge check
Select true or false for the statement below.
- Governance execution frameworks show interconnected data functions across a data ecosystem. Companies normally start to create this framework when they are ready to develop a program structure or a project plan.
- Pseudonymizing data is a governance action under the data observability function.
Answer:
- Governance execution frameworks show interconnected data functions across a data ecosystem. Companies normally start to create this framework when they are ready to develop a program structure or a project plan: True
- Pseudonymizing data is a governance action under the data observability function: False
Prioritizing a use case
Now that we understand the data flow and data governance functions, how do you define your use cases? Which one should be your main priority? It depends on the company’s goals, objectives, and needs.
Below is a chart that shows four different use cases as an example. Each color designates a use case, and the circles connecting to the “criteria” in the center describe the different classification attributes or requirements for each use case.
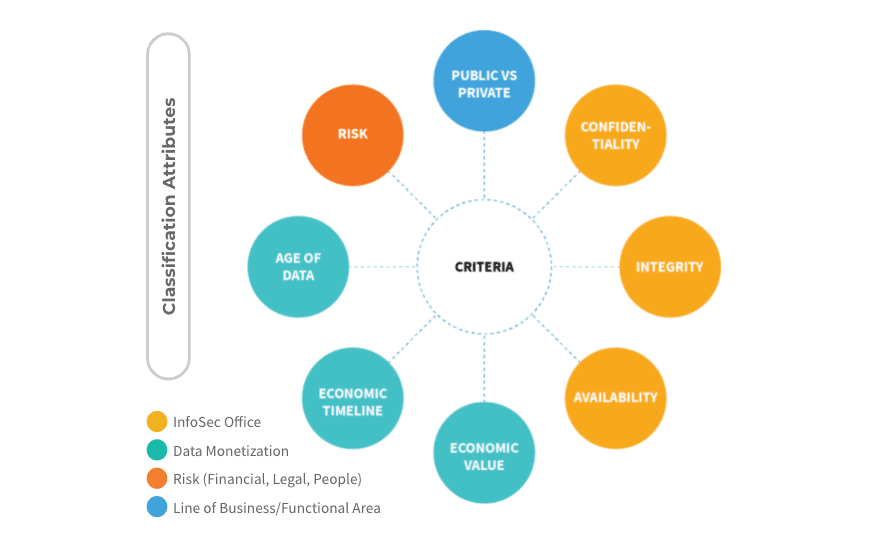
Let’s Set the Scene
For this section, we are going to create a hypothetical situation where you, the learner, are a retailer wanting to use historical and current data to create a new stream of revenue. After evaluating use cases and their potential business impact, data monetization is the use case that has been prioritized and selected.
According to the circle chart above, we can see that the teal-colored circles are associated with the data monetization use case. Age of data, economic timeline, and economic value are the classification attributes associated with the data monetization use case. In the flip cards below, read about the value each of these data attributes could provide.
- Age of Data: By understanding the age of data, the retail business will be able to remove low-quality, inaccurate, our outdated customer and product data.
- Economic Timeline: Data serves as a timeline for your business, showing the number of sales, customer information and trends over time.
- Economic Value: Economic value can be derived from data. For a retailer, data can provide insight into consumer behavior, helping the business develop new products to unlock revenue streams.
Defining functional requirements
With each attribute, there are functional requirements. Functional requirements provide developers with the specific functionality needed so they are able to develop or provide the tools or technology to implement the use case successfully.
In the case of data monetization, there would be requirements related to how data is pulled from different sources and how it can be categorized within a data catalog.
Below is a list of examples that could be functional requirements for a data monetization use case:
- Define catalog
- Data
- Reports
- Analytics models
- Images
- Offline files (PDFs, Words)
- Define data domains and topics
- Business glossary and terms (aka Ontology)
- Tagging
- Searchable attributes
For your retail business, a data catalog would be beneficial for data citizens to easily find data, reports, analytics models, images, and various document types in a simplified, organized, and self-service fashion. This easily referencable catalog can allow retailers to understand the data they already have and how it can be utilized for current and future projects or use cases. The catalog can easily adapt to change too, as companies can set different rules or policies for how data citizens catalog data and other data-related assets.
Tagging data or data-related assets, such as images, documents, and anything stored in the catalog, can also increase a data catalog’s searchability for your retail business. This means that data citizens can search a catalog based on tags and their search results are filtered based on the tags selected. With filtered results, citizens can access the data that is most relevant to what they are working on.
In Conclusion…
Ultimately, your retail business can build out and utilize the different functional requirements associated with data monetization to achieve its goal of developing a new line of revenue for the business.
Laying out the use case most relevant to the desired business objective and defining the functional requirements will make the overall project a more manageable process with greater clarity of their data requirements and intended goal.
Knowledge check
Is the following statement true or false?
Functional requirements provide developers with the specific functionality needed so they are able to develop or provide the tools or technology to implement the use case successfully.
Answer:
Functional requirements provide developers with the specific functionality needed so they are able to develop or provide the tools or technology to implement the use case successfully: True
Governance at scale
Automation and machine learning
This section dives into how organizations can utilize automation and machine learning to apply governance at scale. Organizations are constantly changing and so does the type and amount of data they are ingesting and storing. AI and ML make it easy for an organization to automate, and apply governance across the entirety of their data ecosystem in a consistent manner.
Below is a compilation of different ways that organizations can utilize AI and ML for their governance needs:
- Classification and Relationship across Entities: Classify data using ML to identify PII, PHI, PCI and non-PII attributes. Recommend relationships between entities. Improve accuracy using supervised learning.
- Automate Rules and Pipelines: Recommend data quality rules based on profiling results. Integrate rules with ETL applications for engineers to implement in data pipelines.
- Automate Pseudonymization: Pseudonymize sensitive attributes based on data classification results.
- Contextual Search: Rank search results based on ML models taking into consideration user behavior, recency and other parameters.
- Catalog: Catalog data and capture source schema changes in a no-code tool.
- InfoSec: Implement policies and ensure they are tightly integrated with a governance platform for execution and reporting.
- IT: Setup infrastructure as code (IAC).
The Value of Data Governance
This section summarizes data governance, the value it provides organizations, and provides access to other data governance educational resources.
The value of data governance
Why should you care?
Data Governance is the key to ensuring data is secure and trusted by your end-users. Missing essential governance features such as data quality, lineage, and role-based access controls results in increased security and regulatory risk, and a lack of data usability. Implementing governance practices improves data integrity, reduces time to insight, reduces risk, and increases operational efficiency.
Below you will see some examples of the types of business value that can be achieved by having actionable, high-quality, timely data through data governance.
Increased Revenue
- Competitive differentiation
- Cross-selling and up-selling
- Customer acquisition
- Customer retention and loyalty
- Data products or services
Decreased Costs
- Improved operational efficiency
- Improved productivity
- Risk mitigation
- Regulatory compliance
- Marketing optimization
- Supply chain optimization
- Management of data infrastructure
Innovation
- New data products
- New business models
- New revenue streams
- Personalized customer experience
- Improved product development
- Speed to market
Industry Inside Look
More and more companies are realizing the value of data governance and how it can benefit their organization. In the 2022 State of Cloud Governance eBook, data professionals were able to share what they value most when it comes to measuring the success of their data governance initiatives. According to the poll, 71% of participants chose “consistent data quality” as their primary data governance metric, followed by reduced time to insight and compliance with industry regulation.

The report also shares the following:
“Along with data quality, companies want data governance to generate faster and more reliable analytics. Organizations recognize that they need timely data to make good decisions. Getting the most relevant business insights faster than their competitors means companies can be more competitive and survive in a fluctuating business environment.”
The poll asked participants their perception of data governance, and 71% responded that data governance improves the time to get data for analytics.
In another section of the report, 57% of participants reported that analytics and business intelligence (BI) drove their organization’s investment in data governance technology and tools. Ultimately, this statistic proves that organizations are also considering data governance to improve and experience faster business analytics.
Concluding Thoughts…
Successfully implementing and accelerating data governance practices in an organization can take plenty of time, money, and effort. But, with the proper framework, planning, and designating of teams and roles for the project, data governance can help organizations achieve various benefits and experience business value firsthand. Moreover, data governance is more than just improving data quality and staying compliant with industry regulations. Obtaining value from data governance initiatives, like cost savings and improved efficiency, can result from streamlining data pipelines through automation via ML and AI and reducing time to insight through self-service marketplaces for data citizens. Although not a brand new subject within the industry, data governance is becoming a more common practice as it sets the organization up for analytics, AI, and ML success.
Budget considerations
Consider this…
The list below lists different factors that companies should consider when putting together a budget for a data governance project or initiative. The list below listed should give you a good starting point as budget planning begins.
- New Revenue: Project revenue from data product and/or services.
- Optimization: Improve efficiency to deliver data faster and implement new use cases.
- Infrastructure and License Savings: End-to-End observability will allow sunsetting of data assets that are no longer needed. Saving infrastructure and licensing costs.
- People: Resource required to implement and manage the program. Industry expert to review and educate.
- Technology: Infrastructure, platform license, implementation services, security, and ongoing monitoring.
Real world success story: Alexion Pharmaceuticals, Inc.
Zaloni worked with Alexion Pharmaceuticals Inc. to propel the next step in their digital transformation journey. The data experts at Zaloni were able to deliver Alexion with the proper data governance practices to accelerate their business initiatives, such as improving data quality, time to insight, and data privacy and security throughout their data environment.
In this section, learn the real-life success story of Alexion Pharmaceuticals Inc. and how data governance transformed their data journey.
Introduction
Many companies are looking to modernize their data architectures to scale their data and save money in the long run. Modernizing often includes migrating or expanding into cloud-based or hybrid data environments. It all sounds like a great plan, but knowing where to start is often the biggest challenge.
For Alexion Pharmaceuticals Inc., they were looking to modernize by creating a next-generation data architecture in the cloud. To begin, they needed to migrate their current data warehouse to a new data lake built in the AWS(Amazon Web Services)-based cloud environment. To obtain their goal of a next-generation platform and further their digital transformation journey, a key requirement was to establish centralized management and governance across their cloud-based data warehouse and data lake.
Challenge
Alexion’s goal was to modernize its data architecture and build an enterprise-wide data governance program to derive greater business value from its data, but there were a few obstacles that stood in their way.
Alexion had a large, complex, and siloed data ecosystem, and because of that, its data strategies and tools were fragmented across business functions. The complexity of their data ecosystem resulted in delayed data access, poor data quality, data duplication, and a lack of cross-functional collaboration. IT teams were spending exponential time on data management, which proved inefficient as they could not designate their time to other projects and tasks.
Ultimately, Alexion needed a unified solution to provide complete visibility and control of its data across the organization, facilitate its enterprise data governance initiative, and quickly deliver trusted data to analysts.
Solution
Zaloni and their data governance platform, Arena, were best suited to resolve Alexion’s data challenges. To achieve Alexion’s modernization goals, Zaloni started by migrating its data to the cloud. First, a cloud-based data platform was established by creating a data lake with Amazon EMR and a Hive-based data warehouse on AWS using the Zaloni Arena platform.
With Arena in place, Alexion could ingest, manage, and govern its data at scale while providing role-based access to business users through an enterprise-wide data catalog. Through the use of ML and automation, the organization’s data pipelines within their cloud-based environment improved overall data supply chain efficiency and helped reduce costs across the board. With self-service access to reliable data, data citizens are allowed to request data instantly and gain access quickly, which traditionally took months. By building the data foundation with the enterprise-wide data lake, Alexion can continually expand and achieve new use cases that drive business value.
Result
With Zaloni’s expertise and innovative data solutions, Alexion’s enterprise data platform provides end-to-end visibility and control of its entire data ecosystem. With the capability to streamline and automate data pipelines along with standardized data governance to ensure regulatory compliance, data quality improved exponentially along with data citizens and consumers’ experience with managing, accessing, and utilizing organizational data.
As a result of the latest data governance initiatives and enhancements to their data ecosystem, Alexion had a global view of their data for commercial analytics and other beneficial use cases in less than three months. Alexion was also proud to report that 69% of their new patients for rare disease drugs were found utilizing their new and improved data platform. With their new data and governance procedures, their data consumers now have more time to spend on answering pressing questions that may save the lives of those with rare diseases.