Knowledge of terms to know
Table of Contents
- Knowledge of terms to know
- What is SSL VPN (Secure Sockets Layer virtual private network)?
- What is Cloud Management?
- What is End-to-end encryption (E2EE)?
- What is Master Data Management (MDM)?
- What is Orphaned VM?
- What is C Shell (csh)?
- What is Citizen Data Scientist?
- What is Big Data?
- What is Voice of the customer (VOC)?
- What is Hyperautomation?
- What is Db2?
- What is mIRC?
- What is FTP Server?
- What is Bare-metal Cloud?
- What is Multithreading?
- What is MiniDisc (MD)?
- What is Social Engineering?
- What is Internet Art?
- What is Network Flooding?
- What is Air Gap?
- What is Crosstalk?
- What is Gramm-Leach-Bliley Act (GLBA)?
- What is Maximum Transmission Unit (MTU)?
- What is Integrated Services Digital Network (ISDN)?
- What is Amazon Machine Image (AMI)?
- What is NetBIOS (Network Basic Input/Output System)?
- What is Remote Desktop Connection Manager (RDCMan)?
- What is Turing Test?
- What is Azure Kubernetes Service (AKS)?
- What is natural language understanding (NLU)?
- What is Customer Journey Map?
- What is Digital Divide?
- What is Node?
- What is Tech ethicist?
- What is Form Factor?
- What is Hand Coding?
- What is Programming Logic?
- What is Digital Asset?
- What is Heuristic Programming?
- What is Extreme Programming (XP)?
- What is Natural Language Processing (NLP)?
- What is Asimov’s Three Laws Of Robotics?
- What is Change Control?
- What is Spear Phishing?
- What is Soft Robotics?
- What is Digital experience (DX)?
- What is Wearable Robot?
- What is Artificial Intelligence Robot (AIBO)?
- Question and Answer
- Free Tool
- Course
- Training Resource
- Podcast
- Cheatsheet
What is SSL VPN (Secure Sockets Layer virtual private network)?
An SSL VPN is a type of virtual private network (VPN) that uses the Secure Sockets Layer (SSL) protocol — or, more often, its successor, the Transport Layer Security (TLS) protocol — in standard web browsers to provide secure, remote-access VPN capability. SSL VPN enables devices with an internet connection to establish a secure remote-access VPN connection with a web browser. An SSL VPN connection uses end-to-end encryption (E2EE) to protect data transmitted between the endpoint device client software and the SSL VPN server through which the client connects securely to the internet.
Enterprises use SSL VPNs to enable remote users to securely access organizational resources, as well as to secure the internet sessions of users who are accessing the internet from outside the enterprise. SSL VPNs are important because they provide an E2EE mechanism for client internet sessions and because they can be easily implemented without the need for specialized client software other than a modern web browser. By providing a higher level of compatibility with client platforms and configurations for remote networks and firewalls, SSL VPNs provide more reliable connections.
Because the SSL protocol itself has been deprecated by the Internet Engineering Task Force (IETF) and replaced by TLS, SSL VPNs running on modern browsers now use TLS for encrypting and authenticating data transmitted across the VPN.
SSL VPNs enable users to access restricted network resources remotely via a secure and authenticated pathway by encrypting all network traffic and making it look as if the user is on the local network, regardless of geographic location.
The primary reason to use an SSL VPN product is to prevent unauthorized parties from eavesdropping on network communications and extracting or modifying sensitive data. SSL VPN systems offer secure and flexible options for enterprise employees, telecommuters and contractors to remotely connect to private enterprise networks.
To implement an SSL VPN, organizations can purchase a stand-alone appliance that functions solely as an SSL VPN server; a bundled device, such as a next-generation firewall or unified threat management product that offers SSL VPN capability; or as a service, using a virtual SSL VPN appliance.
How SSL VPNs work?
SSL VPNs rely on the TLS protocol, which has replaced the older SSL protocol, to secure remote access. SSL VPNs enable authenticated users to establish secure connections to internal HTTP and HTTPS services via standard web browsers or client applications that enable direct access to networks.
There are two primary types of SSL VPNs: VPN portal and VPN tunnel. An SSL portal VPN enables one SSL VPN connection at a time to remote websites. Remote users access the SSL VPN gateway with their web browser after they have been authenticated through a method supported by the gateway. Access is gained via a webpage that acts as a portal to other services.
An SSL tunnel VPN enables users to securely access multiple network services via standard web browsers, as well as other protocols and applications that are not web-based. The VPN tunnel is a circuit established between the remote user and the VPN server; the server can connect to one or more remote websites, network services or resources at a time on behalf of the client. The SSL tunnel VPN requires the web browser to handle active content and provide functionality that is not otherwise accessible through an SSL portal VPN.
What are the advantages of SSL VPNs?
One of the primary advantages of an SSL VPN is that it uses the TLS technology implemented in modern web browsers, so there is no need to install specific client software. That makes it easy to deploy. In addition, the encrypted circuits created using TLS provide much more sophisticated outbound connection security than traditional VPN protocols.
Another benefit is that SSL VPNs require less administrative overhead and technical support than traditional VPN clients due to their ease of use and reliance on widely used web clients. SSL VPNs enable users to choose any web browser, regardless of the operating systems (OSes) their devices are running.
In addition, users do not need to download any additional software or configuration files or go through complex steps to create an SSL VPN. Unlike other tunneling security protocols, such as Layer 2 Tunneling Protocol (L2TP) or IP security (IPsec), SSL VPNs only require an updated browser to establish a secure network.
L2TP operates at the data link layer — layer 2 — of the Open Systems Interconnection (OSI) networking model, while IPsec operates at the OSI network layer — layer 3. This means that more networking metadata can be encrypted when using those tunneling methods, but it also requires additional software and configuration to create VPNs with those protocols.
SSL VPNs operate at the transport layer, so network traffic can be more easily split into securely tunneled circuits for accessing protected resources, or applications and untunneled circuits for accessing public resources or applications.
SSL VPN servers can also be configured to enable more precise access control because they build tunnels to specific applications rather than to an entire enterprise network. That means users on SSL VPN connections can be restricted to only those applications for which they have been granted, not the whole network.
What are the security risks?
Despite the benefits an SSL VPN provides, security risks are also associated with the technology. Notwithstanding its enhanced security measures, an SSL network can be susceptible to spreading Malware, including spyware, worms, viruses and Trojan horse programs.
Because users can access an SSL VPN server remotely, a remote user’s device that’s not running updated antivirus software can spread malware from a local network to an organization’s network.
Hackers can also exploit the split tunneling feature of an SSL VPN, which enables users to transmit secured traffic over an SSL VPN tunnel while using untunneled channels to communicate over unsecured channels. Split tunneling enables a user with remote access to share network traffic with both private and public networks at the same time, which can give an attacker the ability to execute an assault using the unsecured channel as an intermediary in the attack.
Additionally, if a remote computer has an established SSL VPN network connection to a company’s internal network and a user leaves a session open, that internal corporate network will be exposed to anyone who has access to that system.
Another potential danger occurs when users attempt to set up an SSL VPN connection using a publicly accessible computer, such as those at kiosks. In those cases, the user may be vulnerable to attacks involving keyloggers installed on an untrusted system that is unlikely to meet enterprise security policies and standards. If keystroke loggers are present, attackers may be able to intercept user credentials and other confidential information.
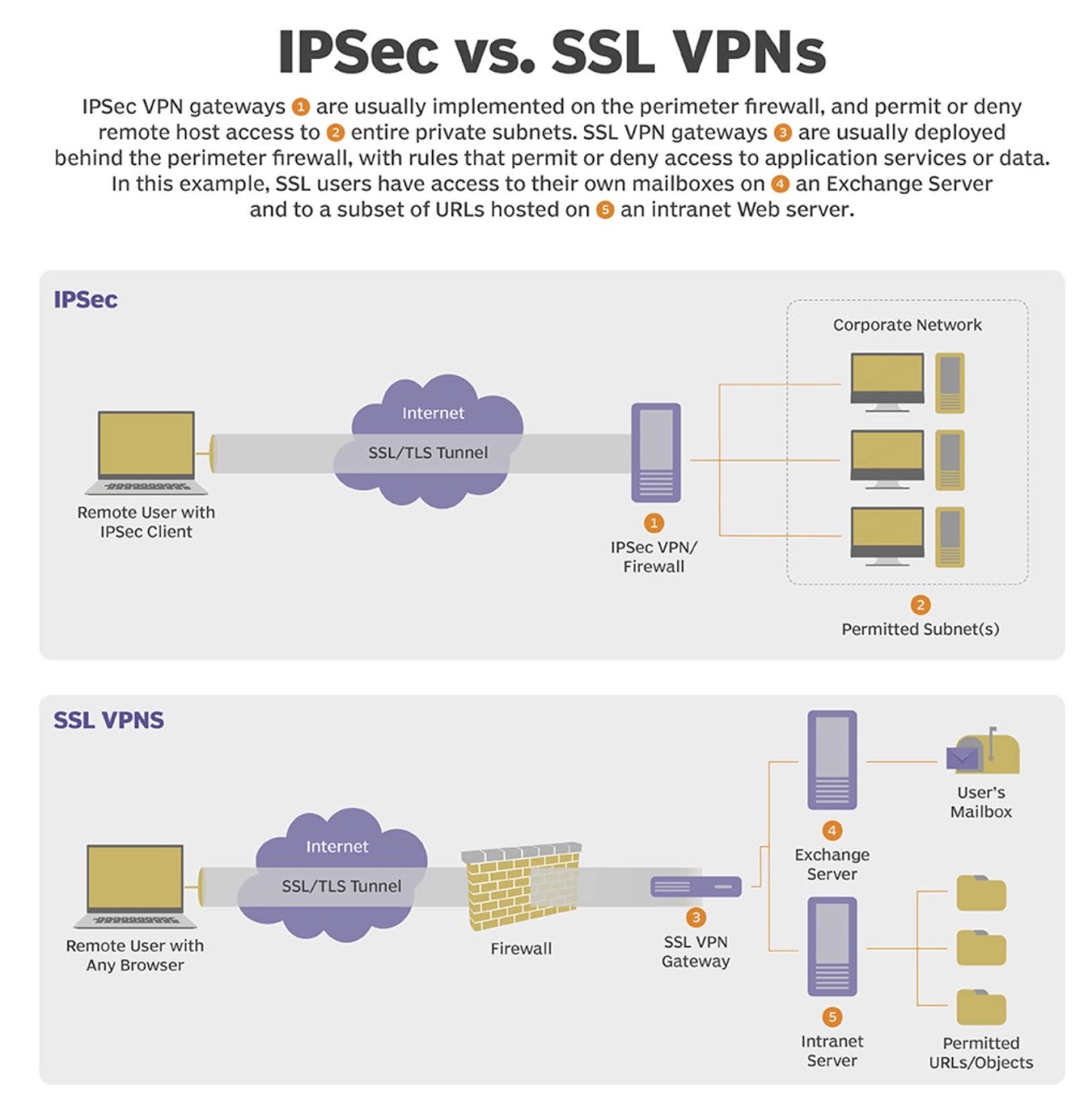
What are the differences between IPsec VPN and SSL VPN?
Using an SSL VPN can have advantages over using an IPsec VPN. First, IPsec remote-access VPN connections require installation of IPsec client software on client systems, which may, in turn, require the purchase and configuration of additional software. SSL VPNs can be set up using existing browsers and minimal configuration modification.
Another advantage of SSL VPN over IPsec VPN lies in its ease of use. While different IPsec VPN vendors may have different implementation and configuration requirements, SSL VPNs can be deployed with virtually any modern web browser.
Also, once the user is authenticated to an IPsec VPN, the client computer has full access to the entire private network, which violates the principle of least privilege (POLP) and, as a result, may expose some private resources to attack. Using an SSL VPN, on the other hand, can enable more precise access control by enabling creation of tunnels to specific applications using sockets rather than to the entire network. This enables organizations to provide different access rights for different users.
What is Cloud Management?
Cloud management is the process of evaluating, monitoring and optimizing cloud computing based solutions and services to produce the desired efficiency, performance and overall service level required. Cloud management is the practice of end-to-end supervision of the cloud environment by an organization, cloud service vendor or both. It ensures that the cloud computing services are delivered and operated in the most optimal form.
As an IT service, cloud management incorporates most of the underlying tasks and approaches from IT service management. It includes very basic to complex management tasks such as maintaining the availability of resources, providing completely functional software/systems and implementing standardized security controls and procedures. Some companies are also providing vendor-neutral cloud management software/services to effectively manage and operate cloud services.
Although the customer or end user is also responsible for their part, cloud management is primarily a vendor end process and includes every task that directly or indirectly affects the cloud environment.
What is End-to-end encryption (E2EE)?
End-to-end encryption (E2EE) is a method of secure communication that prevents third parties from accessing data while it’s transferred from one end system or device to another.
In E2EE, the data is encrypted on the sender’s system or device, and only the intended recipient can decrypt it. As it travels to its destination, the message cannot be read or tampered with by an internet service provider (ISP), application service provider, hacker or any other entity or service.
Many popular messaging service providers use end-to-end encryption, including Facebook, WhatsApp and Zoom. These providers have faced controversy around the decision to adopt E2EE. The technology makes it harder for providers to share user information from their services with authorities and potentially provides private messaging to people involved in illicit activities.
How does end-to-end encryption work?
The cryptographic keys used to encrypt and decrypt the messages are stored on the endpoints. This approach uses public key encryption.
Public key, or asymmetric, encryption uses a public key that can be shared with others and a private key. Once shared, others can use the public key to encrypt a message and send it to the owner of the public key. The message can only be decrypted using the corresponding private key, also called the decryption key.
In online communications, there is almost always an intermediary handing off messages between two parties involved in an exchange. That intermediary is usually a server belonging to an ISP, a telecommunications company or a variety of other organizations. The public key infrastructure E2EE uses ensures the intermediaries cannot eavesdrop on the messages that are being sent.
The method for ensuring a public key is the legitimate key created by the intended recipient is to embed the public key in a certificate that has been digitally signed by a recognized certificate authority (CA). Because the CA’s public key is widely distributed and known, its veracity can be counted on; a certificate signed by that public key can be presumed authentic. Since the certificate associates the recipient’s name and public key, the CA would presumably not sign a certificate that associated a different public key with the same name.
How does E2EE differ from other types of encryption?
What makes end-to-end encryption unique compared to other encryption systems is that only the endpoints — the sender and the receiver — are capable of decrypting and reading the message. Symmetric key encryption, which is also known as single-key or secret key encryption, also provides an unbroken layer of encryption from sender to recipient, but it uses only one key to encrypt messages.
The key used in single-key encryption can be a password, code or string of randomly generated numbers and is sent to the message recipient, enabling them to unencrypt the message. It may be complex and make the message look like gibberish to intermediaries passing it from sender to receiver. However, the message can be intercepted, decrypted and read, no matter how drastically the one key changes it if an intermediary gets ahold of the key. E2EE, with its two keys, keeps intermediaries from accessing the key and decrypting the message.
Another standard encryption strategy is encryption in transit. In this strategy, messages are encrypted by the sender, decrypted intentionally at an intermediary point — a third-party server owned by the messaging service provider — and then reencrypted and sent to the recipient. The message is unreadable in transit and may use two-key encryption, but it is not using end-to-end encryption because the message has been decrypted before reaching its final recipient.
Encryption in transit, like E2EE, keeps messages from being intercepted on their journey, but it does create potential vulnerabilities at that midpoint where they are decrypted. The Transport Layer Security encryption protocol is an example of encryption in transit.
How is end-to-end encryption used?
End-to-end encryption is used when data security is necessary, including in the finance, healthcare and communications industries. It is often used to help companies comply with data privacy and security regulations and laws.
For example, an electronic point-of-sale (POS) system provider would include E2EE in its offering to protect sensitive information, such as customer credit card data. Including E2EE would also help a retailer comply with the Payment Card Industry Data Security Standard (PCI DSS), which mandates that card numbers, magnetic stripe data and security codes are not stored on client devices.
What does end-to-end encryption protect against?
E2EE protects against the following two threats:
- Prying eyes: E2EE keeps anyone other than the sender and intended recipient from reading message information in transit because only the sender and recipient have the keys to decrypt the message. Although the message may be visible to an intermediary server that is helping move the message along, it won’t be legible.
- Tampering: E2EE also protects against tampering with encrypted messages. There is no way to predictably alter a message encrypted this way, so any attempts at altering would be obvious.
What doesn’t end-to-end encryption protect against?
Although the E2EE key exchange is considered unbreakable using known algorithms and current computing power, there are several identified potential weaknesses of the encryption scheme, including the following three:
- Metadata: While E2EE protects the information inside a message, it does not conceal information about the message, such as the date and time it was sent or the participants in the exchange. This metadata could give malicious actors with an interest in the encrypted information clues as to where they may be able to intercept the information once it has been unencrypted.
- Compromised endpoints: If either endpoint has been compromised, an attacker may be able to see a message before it is encrypted or after it is decrypted. Attackers could also retrieve keys from compromised endpoints and execute a man-in-the-middle attack with a stolen public key.
- Vulnerable intermediaries: Sometimes, providers claim to offer end-to-end encryption when what they really offer is closer to encryption in transit. The data may be stored on an intermediary server where it can be accessed.
What are the advantages of end-to-end encryption?
The main advantage of end-to-end encryption is a high level of data privacy, provided by the following features:
- Security in transit: End-to-end encryption uses public key cryptography, which stores private keys on the endpoint devices. Messages can only be decrypted using these keys, so only people with access to the endpoint devices are able to read the message.
- Tamper-proof: With E2EE, the decryption key does not have to be transmitted; the recipient will already have it. If a message encrypted with a public key gets altered or tampered with in transit, the recipient will not be able to decrypt it, so the tampered contents will not be viewable.
- Compliance: Many industries are bound by regulatory compliance laws that require encryption-level data security. End-to-end encryption can help organizations protect that data by making it unreadable.
What are the disadvantages of end-to-end encryption?
Although E2EE generally does a good job of securing digital communications, it does not guarantee data security. Shortcomings of E2EE include the following:
- Complexity in defining the endpoints: Some E2EE implementations allow the encrypted data to be decrypted and reencrypted at certain points during transmission. This makes it important to clearly define and distinguish the endpoints of the communication circuit.
- Too much privacy: Government and law enforcement agencies express concern that end-to-end encryption can protect people sharing illicit content because service providers are unable to provide law enforcement with access to the content.
- Visible metadata: Although messages in transit are encrypted and impossible to read, information about the message — date sent and recipient, for instance — is still visible, which may provide useful information to an interloper.
- Endpoint security: If endpoints are compromised, encrypted data may be revealed.
Not future-proof. Although end-to-end encryption is a strong technology now, there is speculation that eventually quantum computing will render cryptography obsolete.
Applications that use E2EE
The first widely used E2EE messaging software was Pretty Good Privacy, which secured email and stored files and digital signatures. Text messaging applications frequently use end-to-end encryption, including Apple’s iMessage, Jabber and Signal Protocol (formerly TextSecure Protocol). POS providers, like Square, also use E2EE protocols to help maintain PCI compliance.
In 2019, Facebook announced that all three of its messaging services would begin using E2EE. However, law enforcement and intelligence agencies argue that encryption limits Facebook’s ability to police illegal activity on its platforms. The debate often focuses on how E2EE can make it more difficult to identify and disrupt child abuse on private messaging platforms.
“In an end-to-end messaging encryption model, no third party should be able to decrypt messages or access unencrypted data. Many end-to-end encrypted services support customers holding their own keys in a key management server.” – Irwin Lazar
Related Terms: public key, certificate authority, Transport Layer Security, regulatory compliance, SSL VPN
What is Master Data Management (MDM)?
Master data management (MDM) is the management of specific key data assets for a business or enterprise. MDM is part of data management as a whole, but is generally focused on the handling of higher level data elements, such as broader identity classifications of people, things, places and concepts.
Some theories of business management begin with the master data, valuable data units that can be linked to other data in various ways. Transactional data, data about official transactions that is often formalized in transactional documents, can establish relationships between master data units. A broader category of free data that is not codified in formal business documents can also be applied to a more detailed study of master data relationships. In addition, metadata can help to provide pointers for single data assets within a complex data storage infrastructure.
Like other kinds of data management, good master data management relies on excellent protocols, as well as sufficient hardware and software assets. Strategic data management will use guiding principles and time-tested methodologies to actively promote the efficient use of business data, which, as experts point out, is becoming more valuable to many businesses than physical assets like vehicles and equipment. Better use of data can make a company more appealing to investors, streamline operations to increase revenue, and even save a business from financial troubles. This is one of the reasons why a concept like master data management gets so much attention in today’s corporate world.
What is Orphaned VM?
An orphaned VM is a virtual machine that has been disconnected from its host. This problem happens in various network virtualization systems, indicating that a single virtual machine is not correctly connected to the greater software environment.
The issue behind the “orphaned VM” is that virtual machines (VMs), or logical machines created by a virtualization system, are typically connected to a host that manages their implementation and use. There are various reasons why the system cannot find the host for an orphaned VM. These include deleted configurations, unsuccessful failover operations where backup strategies leave the machine disconnected, or even certain kinds of network stress, where the usual protocols become distorted in some way.
Systems administrators use different solutions for dealing with orphaned VMs under different kinds of network virtualization systems. In many cases, they can migrate an orphaned VM to another host. Alternatively, they can delete the orphaned VM and reappropriate the resources. This type of work is part of virtual network management and of the analysis and observation of how network virtualization works in the field.
What is C Shell (csh)?
The C shell (csh) is a command shell for Unix-like systems that was originally created as part of the Berkeley Software Distribution (BSD) in 1978. Csh can be used for entering commands interactively or in shell scripts. The shell introduced a number of improvements over the earlier Bourne shell designed for interactive use. These include history, editing operations, a directory stack, job control and tilde completion. Many of these features were adopted in the Bourne Again shell (bash), Korn shell (ksh) and in the Z shell (zsh). A modern variant, tcsh, is also very popular.
The C shell was created by Bill Joy while he was a graduate student at UC Berkeley in the late 1970s. It was first released as part of the 2BSD Berkeley Software Distribution of Unix in 1978.
The C shell gets its name from its syntax, which is intended to resemble the C programming language.
The C shell introduced features that were intended to make it easier to use interactively at the command line, though like other shells it is capable of being scripted. One of the most notable features was command history. Users can recall previous commands they have entered and either repeat them or edit these commands. Aliases allow users to define short names to be expanded into longer commands. A directory stack lets users push and pop directories on the stack to jump back and forth quickly. The C shell also introduced the standard tilde notation where “~” represents a user’s home directory.
Most of these features have been incorporated into later shells, include the Bourne Again shell, the Korn shell and the Z shell. A popular variant is tsch, which is the current default shell on BSD systems, as well as on early versions of Mac OS X.
What is Citizen Data Scientist?
A citizen data scientist is any individual who contributes to the research of a complex data initiative but who does not have a formal educational background in data analytics (DA) or business intelligence (BI). A citizen data scientist is able to contribute valuable research to a topic, whether through performing time consuming data checks, meticulous data preparation or by discovering anomalies and alerting professionals to spend more time looking into a particular area of their analytics.
While a citizen data scientist may not perform a formal job function at a company, they still play a vital role and may participate in breakthrough discoveries. When citizen data scientists are able to master the tools used by the experts, they act as valuable members of an organization. Citizen data scientists do not replace data scientists, but are intended to collaborate with them to accomplish more work in shorter timeframes.
How to become a citizen data scientist?
Anyone can perform the role of a citizen data scientist, but it helps to have a parallel background in something similar to the field that the experts are researching. Becoming a citizen data scientist involves doing some research and following a few simple steps:
- Request access to the newest and best data.
- Learn how to use business software and other analytical programs.
- Stay familiar with security protocols and be careful not to compromise raw, protected data or secured storage areas.
- Work with an expert in the research. For instance, some companies have created a role called data guardian, who is someone that checks in with data scientists to learn best practices and receive other guidance.
- Become familiar with complex skills like machine learning, business analytics, statistics and coding in various programming languages.
How importance of citizen data scientists?
The role of a citizen data scientist has become more important for organizations to incorporate as there is a shortage of trained data scientists. Instead, data science roles can be filled by employees with various backgrounds that know how to use big data tools and create data models. By using skills across teams or training employees in new areas, organizations can save money, operate more efficiently and make better use of data.
What is difference between Citizen data scientist and analytics translator?
Analytics translators are similar to citizen data scientists in that they do not require specialized data analytics or IT training. However, analytics translators start the process that is carried out by a data scientist or citizen data scientist. They use tools and business intelligence to help identify patterns, trends, problems and potential opportunities is cross-functional initiatives like production or pricing. Once the initial research is done by an analytics translator, it is passed on to the rest of the data analytics team to dive further into the nuances, produce reports and make decisions.
What is Big Data?
Big data refers to a process that is used when traditional data mining and handling techniques cannot uncover the insights and meaning of the underlying data. Data that is unstructured or time sensitive or simply very large cannot be processed by relational database engines. This type of data requires a different processing approach called big data, which uses massive parallelism on readily-available hardware.
Quite simply, big data reflects the changing world we live in. The more things change, the more the changes are captured and recorded as data. Take weather as an example. For a weather forecaster, the amount of data collected around the world about local conditions is substantial. Logically, it would make sense that local environments dictate regional effects and regional effects dictate global effects, but it could well be the other way around. One way or another, this weather data reflects the attributes of big data, where real-time processing is needed for a massive amount of data, and where the large number of inputs can be machine generated, personal observations or outside forces like sun spots.
Processing information like this illustrates why big data has become so important:
- Most data collected now is unstructured and requires different storage and processing tthan that found in traditional relational databases.
- Available computational power is sky-rocketing, meaning there are more opportunities to process big data.
- The Internet has democratized data, steadily increasing the data available while also producing more and more raw data.
Data in its raw form has no value. Data needs to be processed in order to be of valuable. However, herein lies the inherent problem of big data. Is processing data from native object format to a usable insight worth the massive capital cost of doing so? Or is there just too much data with unknown values to justify the gamble of processing it with big data tools? Most of us would agree that being able to predict the weather would have value, the question is whether that value could outweigh the costs of crunching all the real-time data into a weather report that could be counted on.
What is Voice of the customer (VOC)?
Voice of the customer (VOC) is the component of customer experience that focuses on customer needs, wants, expectations and preferences.
In most businesses, the quality of customer experience is a key differentiating factor against competitors. Therefore, deploying a VOC program is important for ensuring that customer input is requested and valued.
To determine the VOC, an organization analyzes indirect input — data that reflects customer behaviors — and direct input — data that reflects what a customer says. Gathering indirect input includes a close examination of customer data that businesses gather through monetary transactions, market research, product usage data and web analytics. Gathering direct input includes social media monitoring for brand or product mentions, collecting both negative feedback and positive feedback from customers and conducting customer interviews.
“Customer data is always valuable, but the structured, all-inclusive approach of a VoC program boosts that value considerably.” – Scott Robinson
How importance of voice of the customer?
Customer feedback helps ensure that organizations deliver features that customers want and need. With subscription-based, digitally delivered product offerings, such as software as a service (SaaS), customer retention and the ability to upsell are important factors in revenue. Therefore, VOC-enabled customer success is crucial to organizations with a “pay-as-you-go” pricing model. Additionally, it is important to communicate organizational changes that are made as a result of VOC data to inform customers that businesses are acknowledging their opinions.
How to collect customer feedback?
There are multiple channels from which businesses can collect direct feedback from customers. These methods include:
- Organizing a customer advisory council that meets with existing customers to receive their feedback.
- Sending customers a request to complete surveys or product reviews. These include online surveys, phone surveys, SMS surveys and those sent by mail.
- Creating a mystery shopping program for customers to complete audits and provide feedback on brand services, products and location cleanliness.
- Calculating customer scores such as the net promoter score (NPS), customer health score (CHS) and customer effort score (CES).
- Using social media monitoring tools to monitor brand mentions on the web.
- Gathering live chat logs from customer support phone calls and text messages.
- Selecting topics and customers to create focus groups.
Related Terms: social media listening, customer health score, customer satisfaction, customer effort score, Net Promoter Score
What is Hyperautomation?
Hyperautomation refers to techniques and methods that can automate processes in significant and profound ways.
Although the term is not clearly defined, in 2020 bodies like Gartner and big companies in the tech space are defining hyperautomation as the next wave of automation or “automation 2.0.”
Many experts describe hyperautomation in several key ways. First, they identify advanced technologies such as artificial intelligence and machine learning. Then they describe the ways that hyperautomation works — to augment human work and combine the resources of humans and technologies for a more effective result.
Hyperautomation in enterprise IT means going back to the drawing board with the cutting-edge technologies and resources that we now have in looking at how to automate processes more fully then we did in the past.
What is Db2?
Db2 is a family of database management system (DBMS) products from IBM that serve several different operating system (OS) platforms. Used by organizations of all sizes, Db2 provides a data platform for both transactional and analytical operations, as well as continuous availability of data to keep transactional workflows and analytics operating efficiently.
In addition to being a relational DBMS, Db2 also offers integrated support for several NoSQL capabilities, including XML, graph store and JavaScript Object Notation, or JSON.
What is a Db2 database?
A Db2 database is a group of data treated collectively as a unit. A database is a large structured set of persistent data, and its purpose is to store, retrieve and manipulate related information.
How does Db2 database work?
A database administrator (DBA) uses Db2, which is DBMS or database server, to create and use Db2 databases. The Db2 DBMS operates as the server to manage data in databases across a multiuser environment, enabling many concurrent users to access the same data simultaneously. The Db2 DBMS also prevents unauthorized access, provides utilities for backing up and recovering data and offers performance tools and data management capabilities.
Db2 databases have logical structures and physical structures which the DBMS manages separately. The physical storage of data can be managed without affecting the access to logical storage structures. Db2 databases are created using Data Definition Language, or DDL, commands and are composed of tablespaces, tables with rows and columns, views, indexes, stored procedures and other supporting structures.
Once created, a DBA or developer can use a Db2 database and its underlying structures to create, read, update and delete data to support an organization’s business requirements.
What are the advantages of Db2?
Db2 offers many advanced features for improving data and database management, including the following:
- Actionable compression can deliver storage space savings without sacrificing performance. Many query predicates can be evaluated without having to decompress the data.
- Hybrid transaction analytical processing, or HTAP, performance is accelerated by the Db2 BLU column store with single instruction, multiple data, or SIMD, exploitation and data-skipping technology on LUW platforms and by the IBM Db2 Analytics Accelerator on z/OS.
- A DBA can build a temporal database using Db2 to enable system and business changes to be captured, maintained and queried. This enables organizations to store information relating to past, present and future time, as well as use time-travel queries to view past and future data states.
- AI and machine learning (ML) capabilities, including the augmented data explorer, deliver natural language query capabilities, a ML query optimizer, and a hybrid data management platform to enable seamless sharing of structured, unstructured and semistructured data.
- Choice of deployment model includes on-premises, hosted cloud deployment or managed cloud deployment.
- Db2 on LUW platforms offer an Oracle SQL compatibility option.
- Db2 for z/OS enables organizations to run mixed workloads with exceptional scalability, high performance and round-the-clock availability.
What are the disadvantages of Db2?
Being relational, the disadvantages common to the RDBMS type apply to Db2 as much as any other RDBMS. These include the following:
- An impedance mismatch between object-oriented (OO) and relational means that object relational mapping is required for OO application programs, such as Java, to access the data.
- The relational model requires a rigid schema that does not necessarily fit with some types of modern development. NoSQL database systems cover the niche areas for which the RDBMS is not well-suited.
- Db2 does not scale as well horizontally as NoSQL because of the consistency model it uses, but it can scale vertically by adding CPU and memory.
- Because there are more users of database systems like Oracle and Microsoft SQL Server, it can be difficult to find talented and knowledgeable Db2 professionals.
What is mIRC?
mIRC is one of the earliest and most iconic Internet Relay Chat messaging services. It was created in 1995 and distributed as a shareware program. It reached its peak use around 2003-2005, long before the full advent of modern social media. Still functional even in modern times, mIRC is compatible with the Windows operating system architecture. In fact, its scripting language is ever-evolving and has never stopped being updated.
Although it was just one of many IRC clients, mIRC rapidly became the most popular, especially among gamers, who used it for decades to gather in groups and guilds. One of its most appreciated features was its ability to share files via the DCC protocol and built-in file server.
Internet Relay Chat (IRC) networks accommodate digital chatting in the form of ASCII-based character messaging. mIRC offers closed discussion forums known as “channels” or private messaging between individual pairs of users.
IRC, which is an open protocol using IP/TCP protocols, has been around since the 1980s when it was used for fairly primitive BBS and local networking systems. These tools grew as the internet grew, and the modern mIRC interface shows how simpler command-line–based interfaces have been replaced by a Windows-based and icon-driven menu system. Eventually, mIRC became so popular that the term mIRC became a synonym of IRC itself.
Other features of modern mIRC include buddy lists, file transfer capability, multi-server connections, compatibility with IPv6, SSL encryption, and even sound and audio components. mIRC also has its own scripting for display features and more. Possibly one of the most appealing features provided by the extra coding added to mIRC was its “stylish” and customizable appearance. Compared to the other bland and somewhat primitive clients, mIRC allowed users to add color to the text, play sound files such as .wav and .midi within the chat, and add colorful icons.
mIRC also uses its own Turing-complete embedded scripting language and GUI scripting editor to allow end-users to alter and extend it even further.
In using mIRC and other IRC systems, users have come up with a wide variety of terminology called “chat slang,” where combinations of characters are used to create visuals or abbreviations are used to communicate ideas and emotions. A lot of this chat slang has also become useful in email, text messaging and other digital text-based communication.
Although mIRC has lost a large number of users compared to its peak in 2003-2005 (up to 60%), it is still alive and kicking even today. Although, some earlier versions were found to contain vulnerabilities, mIRC now provides a secure and private option to chat for those who are concerned about privacy. In fact, all servers are decentralized and there is no overseeing authority collecting users’ data.
What is FTP Server?
The primary purpose of an FTP server is to allow users to upload and download files. An FTP server is a computer that has a file transfer protocol (FTP) address and is dedicated to receiving an FTP connection. FTP is a protocol used to transfer files via the internet between a server (sender) and a client (receiver). An FTP server is a computer that offers files available for download via an FTP protocol, and it is a common solution used to facilitate remote data sharing between computers.
An FTP server is an important component in FTP architecture and helps in exchanging files over the internet. The files are generally uploaded to the server from a personal computer or other removable hard drives (such as a USB flash drive) and then sent from the server to a remote client via the FTP protocol.
An FTP server needs a TCP/IP network to function and is dependent on the use of dedicated servers with one or more FTP clients. In order to ensure that connections can be established at all times from the clients, an FTP server is usually switched on; up and running 24/7.
An FTP server is also known as an FTP site or FTP host.
Although the FTP server actually sends files over the internet, it generally acts as the midpoint between the real sender of a file and its recipient. The recipient must access the server address, which can either be a URL (e.g., ftp://exampleserver.net) or as a numeric address (usually the IP address of the server). All file transfer protocol site addresses begin with ftp://. FTP servers usually listen for client connections on port 21 since the FTP protocol generally uses this port as its principle route of communication. FTP runs on two different Transmission Control Protocol ports: 20 and 21. FTP ports 20 and 21 must both be open on the network for successful file transfers.
The FTP server allows the downloading and uploading of files. The FTP server’s administrator can restrict access for downloading different files and from different folders residing in the FTP server. Files residing in FTP servers can be retrieved by common web browsers, but they may not support protocol extensions like FTPS. With an FTP connection, it is possible to resume an interrupted download that was not successfully completed; in other words, checkpoint restart support is provided.
For the client to establish a connection to the FTP server, the username and password are sent using USER and PASS commands. Once accepted by the FTP server, an acknowledgment is sent to the client and the session can start. Failure to open both ports 20 & 21 prevents the full back-and-forth transfer from being made.
The FTP server can provide connection to users without login credentials; however, the FTP server can authorize these to have only limited access. FTP servers can also provide anonymous access. This access allows users to download files from the servers anonymously but prohibits uploading files to FTP servers.
Beyond routine file transfer operations, FTP servers are also used for offsite backup of critical data. FTP servers are quite inexpensive solutions for both data transfer and backup operations, especially if security is not a concern. However, when simple login and authentication features are not sufficient to guarantee an adequate degree of security (such as when transferring sensitive or confidential information), two secure file transfer protocol alternatives, SFTP and FTP/S, are also available. These secure FTP server options offer additional levels of security such as data encryption.
What is Bare-metal Cloud?
Bare-metal cloud is a public cloud service where the customer rents dedicated hardware resources from a remote service provider. It offers the hardware resources without any installed operating systems or virtualization infrastructure.
Commercial cloud service infrastructure enables the virtualization and subdivision of compute, storage and database resources so that servers and storage arrays can be carved up and shared by multiple customers. But while virtualized compute instances provide flexibility and cost benefits, there are drawbacks, particularly related to resource contention — the so-called noisy neighbor problem. There are also risks from incomplete isolation of execution environments and virtual networks. Bare-metal cloud solves these issues, allocating isolated physical resources to customers.
The bare-metal-cloud is a good option for big data applications and high-transaction workloads that do not deal well with latency. Most of the largest cloud vendors, such as AWS, IBM, Oracle and Rackspace, offer bare-metal cloud services.
“The primary difference with bare-metal is that the service maps to a physical server rather than a virtual machine.” – Stephen J. Bigelow
Related Terms: noisy neighbor, multi-cloud strategy, RESTful API, high-performance computing, nested virtualization
What is Multithreading?
Multithreading is a CPU (central processing unit) feature that allows two or more instruction threads to execute independently while sharing the same process resources. This means multiple concurrent tasks can be performed within a single process. A thread is a self-contained sequence of instructions that can execute in parallel with other threads that are part of the same root process.
In programming, an instruction stream is called a thread and the instance of the computer program that is executing is called a process. Each process has its own memory space where it stores threads and other data the process requires to execute.
When data scientists are training machine learning algorithms, a multithreaded approach to programming can improve speed when compared to traditional parallel multiprocessing programs.
Multithreading and multiprocessing are complementary. Multithreading allows a process to create more threads in order to improve responsiveness. In contrast, multiprocessing simply adds more CPUs to increase speed.
Even though it’s faster for an operating system (OS) to switch between threads for an active CPU task than it is to switch between different processes, multithreading requires careful programming in order to avoid conflicts caused by race conditions and deadlocks. To prevent race conditions and deadlocks, programmers use locks that prevent multiple threads from modifying the value of the same variable at the same time.
In programming, a thread maintains a list of information relevant to its execution, including the priority schedule, exception handlers, a set of CPU registers, and stack state in the address space of its hosting process.
Threading can be useful in a single-processor system because it allows the primary execution thread to be responsive to user input while supporting threads execute long-running tasks in the background that do not require user intervention.
The 32- and 64-bit versions of Windows use pre-emptive multithreading in which the available processor time is shared. All threads get an equal time slice and are serviced in a queue-based model. During thread switching, the context of a pre-empted thread is stored and reloaded in the next thread in the queue. This takes so little time, that the running threads seem to execute in parallel.
Types of Multithreading
Different types of multithreading apply to various versions of operating systems and related controls that have evolved in computing: for example, in pre-emptive multithreading, the context switch is controlled by the operating system. Then there’s cooperative multithreading, in which context switching is controlled by the thread. This could lead to problems, such as deadlocks if a thread is blocked waiting for a resource to become free.
Many other types of models for multithreading also apply, for example, coarse-grained, interleaved and simultaneous multithreading models will determine how the threads are coordinated and processed. Other options for multithreading include many to many, many to one and one to one models. Some models will use concepts like equal time slices to try to portion out execution among threads. The type of multithreading depends on the system itself, its philosophy and its build, and how the engineers planned multithreading functionality within it.
In the active/passive system model, one thread remains responsive to a user, and another thread works on longer-term tasks in the background. This model is useful for promoting a system that looks parallel from a user viewpoint, which brings us to a major point in evaluating processes like micro threading from both ends: from the perspective of the engineer, and the perspective of the end-user.
How does Multithreading Work?
When thinking about how multithreading is done, it’s important to separate the two concepts of parallel and concurrent processing.
Parallel multiprocessing means the system is actually handling more than one thread at a given time. Concurrent processing means that only one thread will be handled at a time, but the system will create efficiencies by moving quickly between two or more threads.
Another important thing to note is that for practical purposes, computer systems set up for human users can have parallel or concurrent systems, with the same end result – the process looks parallel to the user because the computer is working so quickly in terms of microseconds.
In addition, much of the parallel or concurrent processing is made available according to the vagaries of the operating system. So in effect, to the human user, either parallel or concurrent process, or processes that are mixed, are all experienced as parallelism in real-time.
Then, too, the evolution of multicore systems means that there is more parallelism, which alleviates the need for efficient concurrent processing. The development of faster and more powerful microchips and processors on this end of the expansion of Moore’s law is important to this type of hardware design and engineering in general.
What are the advantages of Multithreading?
Experts also point out some of the benefits of multithreading including economical advantages. There is also the potential for resource sharing and the responsiveness of active threads. Engineers may also point to scalability as a reason to pursue multithreading or similar concepts in systems management.
What is MiniDisc (MD)?
A MiniDisc (MD) is a magneto-optical disc-based audio storage and playing device released in 1992 under the Sony brand. They were a strong competitor of cassette recorders and players, offering more space and convenience. MiniDiscs could be purchased in preloaded or empty and recordable form with 140 MB of space to store data or record, erase and play music on the go.
Although MiniDiscs were targeted for use among teenagers, they were generally too expensive in 1992 and hence could not attract many users. Sony tried lowering the price, but $250 was still out of range for a regular teenager at the time. MiniDiscs gained some popularity in Japan, where they came to be commonly used, but failed to gain a foothold in other regions.
A MiniDisc is similar to a small floppy disk, except that it can hold almost 100 times more data than ordinary floppy disks (140 MB of audio data storage vs. 1.44 MB capacity of floppy). The audio files were stored in the ATRAC audio data compression format, but later the default format was changed to linear PCM digital recording for better quality and convenience as well as better storage.
Production of MiniDisc players was discontinued in 2013.
What is Social Engineering?
Social engineering is an attack vector that relies heavily on human interaction and often involves manipulating people into breaking normal security procedures and best practices to gain unauthorized access to systems, networks or physical locations or for financial gain.
Threat actors use social engineering techniques to conceal their true identities and motives, presenting themselves as trusted individuals or information sources. The objective is to influence, manipulate or trick users into releasing sensitive information or access within an organization. Many social engineering exploits rely on people’s willingness to be helpful or fear of punishment. For example, the attacker might pretend to be a co-worker who has some kind of urgent problem that requires access to additional network resources.
Social engineering is a popular tactic among attackers because it is often easier to exploit people than it is to find a network or software vulnerability. Hackers will often use social engineering tactics as a first step in a larger campaign to infiltrate a system or network and steal sensitive data or disperse malware.
How does social engineering work?
Social engineers use a variety of tactics to perform attacks.
The first step in most social engineering attacks is for the attacker to perform research and reconnaissance on the target. If the target is an enterprise, for instance, the hacker may gather intelligence on the organizational structure, internal operations, common lingo used within the industry and possible business partners, among other information.
One common tactic of social engineers is to focus on the behaviors and patterns of employees who have low-level but initial access, such as a security guard or receptionist; attackers can scan social media profiles for personal information and study their behavior online and in person.
From there, the social engineer can design an attack based on the information collected and exploit the weakness uncovered during the reconnaissance phase.
If the attack is successful, the attacker gains access to confidential information, such as Social Security numbers and credit card or bank account information; makes money off the targets; or gains access to protected systems or networks.
How to prevent social engineering attacks?
There are a number of strategies companies can take to prevent social engineering attacks, including the following:
- Make sure information technology departments are regularly carrying out penetration testing that uses social engineering techniques. This will help administrators learn which types of users pose the most risk for specific types of attacks, while also identifying which employees require additional training.
- Start a security awareness training program, which can go a long way toward preventing social engineering attacks. If users know what social engineering attacks look like, they will be less likely to become victims.
- Implement secure email and web gateways to scan emails for malicious links and filter them out, thus reducing the likelihood that a staff member will click on one.
- Keep antimalware and antivirus software up to date to help prevent malware in phishing emails from installing itself.
- Keep track of staff members who handle sensitive information, and enable advanced authentication measures for them.
- Implement 2FA to access key accounts, e.g., a confirmation code via text message or voice recognition.
- Ensure employees don’t reuse the same passwords for personal and work accounts. If a hacker perpetrating a social engineering attack gets the password for an employee’s social media account, the hacker could also gain access to the employee’s work accounts.
- Implement spam filters to determine which emails are likely to be spam. A spam filter might have a blacklist of suspicious Internet Protocol addresses or sender IDs, or they might detect suspicious files or links, as well as analyze the content of emails to determine which may be fake.
What is Internet Art?
Internet art is a kind of art that uses the Internet as its mode of dissemination. The art is often interactive and/or participatory in nature and may use a number of different mediums. This method strays from the traditional gallery and museum system and gives even small artists a way of sharing their work with a large audience. Artists who do this kind of art are usually called net artists.
Internet art is also known as Net art.
Internet art can be created in all different types of media, including websites, software projects or gaming, streaming video or audio and networked performances.
Internet art has its roots in various other genres, such as conceptual art, video art, performance art, telematics art and kinetic art. The more recent emergence of image-based social networking sites such as Flickr have provided yet more avenues for Internet artists.
What is Network Flooding?
In a computer network, flooding occurs when a router uses a nonadaptive routing algorithm to send an incoming packet to every outgoing link except the node on which the packet arrived.
Flooding is a way to distribute routing protocols updates quickly to every node in a large network. Examples of these protocols include the Open Shortest Path First and Distance Vector Multicast Routing Protocol.
Network flooding also has some other uses, including the following:
- Multicasting data packets from one source node to many specific nodes in a real or virtual network
- Bridging
- Peer-to-peer file sharing
- Ad hoc wireless networks
How do flooding algorithms work?
In computer science, flooding algorithms can be configured in one of two ways:
- Every node acts as a sender and a receiver; or
- Every node tries to send the packet to each of its counterparts except for the source node.
Either way, the end result is that the flooded information eventually reaches all nodes within the network.
What are the different types of network flooding?
Network flooding can occur in one of three ways, controlled flooding, uncontrolled flooding and selective flooding.
- In controlled flooding, two algorithms are used in order to ensure that the flooding can be contained. These algorithms are Reverse Path Forwarding and Sequence Number Controlled Flooding.
- In uncontrolled flooding, there is no conditional logic to control how the node distributes information packets to its counterparts. Without these restraints, repeated distribution of the same packet can occur. These are referred to as broadcast storm or ping storm.
- In selective flooding, nodes are configured to only send incoming packets to routers in one direction. This can help to prevent some of the mishaps that occur with uncontrolled flooding, but is not as sophisticated as controlled flooding.
What are the downfalls of network flooding?
While network flooding is simple to implement, it can have a number of drawbacks. For example, network flooding can waste network traffic bandwidth if information packets are sent needlessly to all IP addresses when only a few require the information.
Furthermore, cybercriminals can use flooding in denial of service (DoS) attacks to cause a service timeout or to disrupt a computer network.
How to prevent network flooding issues?
Network administrators can prevent flooding attacks and connectivity issues caused by uncontrolled flooding with a few best practices:
- Implement a firewall to prevent cybercriminals from gaining the access they need to implement a DoS attack.
- Use a time to live or hop count when implementing network flooding to prevent the number of nodes that a packet must move through to reach its final destination.
- Employ controlled flooding to ensure packets are only forwarded to a node once.
- Eenforce a network topology that does not allow loops.
What is Air Gap?
An air gap is a security measure in which computers, computer systems or networks are not connected in any way to any other devices or networks. This is used in instances requiring airtight security without the risk of compromise or disaster. It ensures total isolation of a given system — electromagnetically, electronically and, most importantly, physically — from other networks, especially those that are not secure. In other words, data can only be transferred by connecting a physical device to it, such as a flash drive, external hard disk or DVD.
The term “air gap” is a merely metaphoric description of the conceptual gap required by the physical separation between the computers. Air-gapped networks and computers are used when maximum security of that system or the data stored in it must be ensured. Air gaps protect systems from malware, keyloggers, ransomware or other unwanted accesses. Typical examples include life-critical power plant controls, military and aviation computers, government networks, financial computer systems or computerized medical equipment, among others.
A lot of traditional electronic equipment like thermostats and home appliances have always been air-gapped due to their inherent limits rather than for security reasons. However, with the widespread diffusion of wireless components and “smart” devices, these products are no longer air-gapped, as they are connected to the internet.
Technically, even a simple desktop PC that is not connected to the internet could be considered an air-gapped system.
An air gap is also known as an air wall.
An air gap is maximum protection between a system and other devices/systems — apart from actually turning it off. Two disconnected systems or devices designate two security levels: low (unclassified) and high (classified). To move data, it often must be saved in some type of transportable medium. Moving data from low to high is simple, whereas moving classified data from high to low security requires a strict procedure prior to performing the transfer, due to the data’s classified nature.
What is the advantages of an Air Gap?
- The air gap might prevent data destruction or leakage due to power fluctuations.
- The machine is protected from any malware that might be circulating the internet.
- The machine is secure.
- It’s considered to be the most foolproof way of securing files and information from hackers, thieves, or spies due to the lack of connection in this type of system.
An air gap is one way to make it harder for hackers, thieves, or spies to access your files and generally control your computer system. It’s important to note that just because a computer is not connected, it doesn’t mean it’s safe. There are still ways for hackers like viruses from USB devices that are plugged into the air-gapped machine or by Bluetooth connections from nearby devices other than Mobile phones.
The usual configuration of an air gap is a “sneakernet,” so-called because one must walk to the system and connect a method of data transfer. The idea is to make sure the only way to breach an air-gapped computer and compromise the system is to “cross the air gap.” This means having someone physically access the system themselves by sitting in front of it with a Wi-Fi dongle or USB device as it is otherwise inaccessible.
A system or device may require certain security precautions, such as:
- Entirely banning local wireless communications
- Preventing electromagnetic (EM) leakage by placing the system/device in a Faraday cage to block wireless transmissions
- Protecting the system from other types of attack, such as optical, thermal or acoustic
Despite the high level of security produced by an air gap, some advanced techniques have been ideated to find a way to breach air-gapped computers, although some of them are still more theoretical than practical. Cutting-edge acoustic channels employing ultrasonic, inaudible sound waves can be used as an attack vector against hackable smartphones that are capable of picking up higher frequencies. Data can also be siphoned through radio signals even when Bluetooth is disabled. That is why, in many high-security environments, mobile phones are not allowed in range of the most critical systems.
Surveillance cameras can also be hacked, as they allow optical transmission of data through their LEDs. Thermal hacks can also be used, but the bandwidth is very low, so they are far from representing a practical threat at the moment.
What is Crosstalk?
Crosstalk is a disturbance caused by the electric or magnetic fields of one telecommunication signal affecting a signal in an adjacent circuit.
Essentially, every electrical signal has a varying electromagnetic field. Whenever these fields overlap, unwanted signals — capacitive, conductive or inductive coupling — cause electromagnetic interference (EMI) that can create crosstalk.
Overlap can occur with structured cabling, integrated circuit design, audio electronics and other connectivity systems. For example, if there are two wires in close proximity that are carrying different signals, their currents will create magnetic fields that induce a weaker signal in the neighboring wire.
There are several examples of crosstalk that occur in various technical capacities. Here are a few of the most common.
Crosstalk in telephony
The definition of crosstalk, as it relates to telecommunication or telephony, is when there is leakage from a separate conversation from a nearby circuit into the phone conversation of someone else nearby.
The crosstalk issue can be extremely disruptive, particularly in a business setting. If it’s an analog connection, twisted pair cabling can often be employed to reduce the likelihood of crosstalk.

Crosstalk in cabling
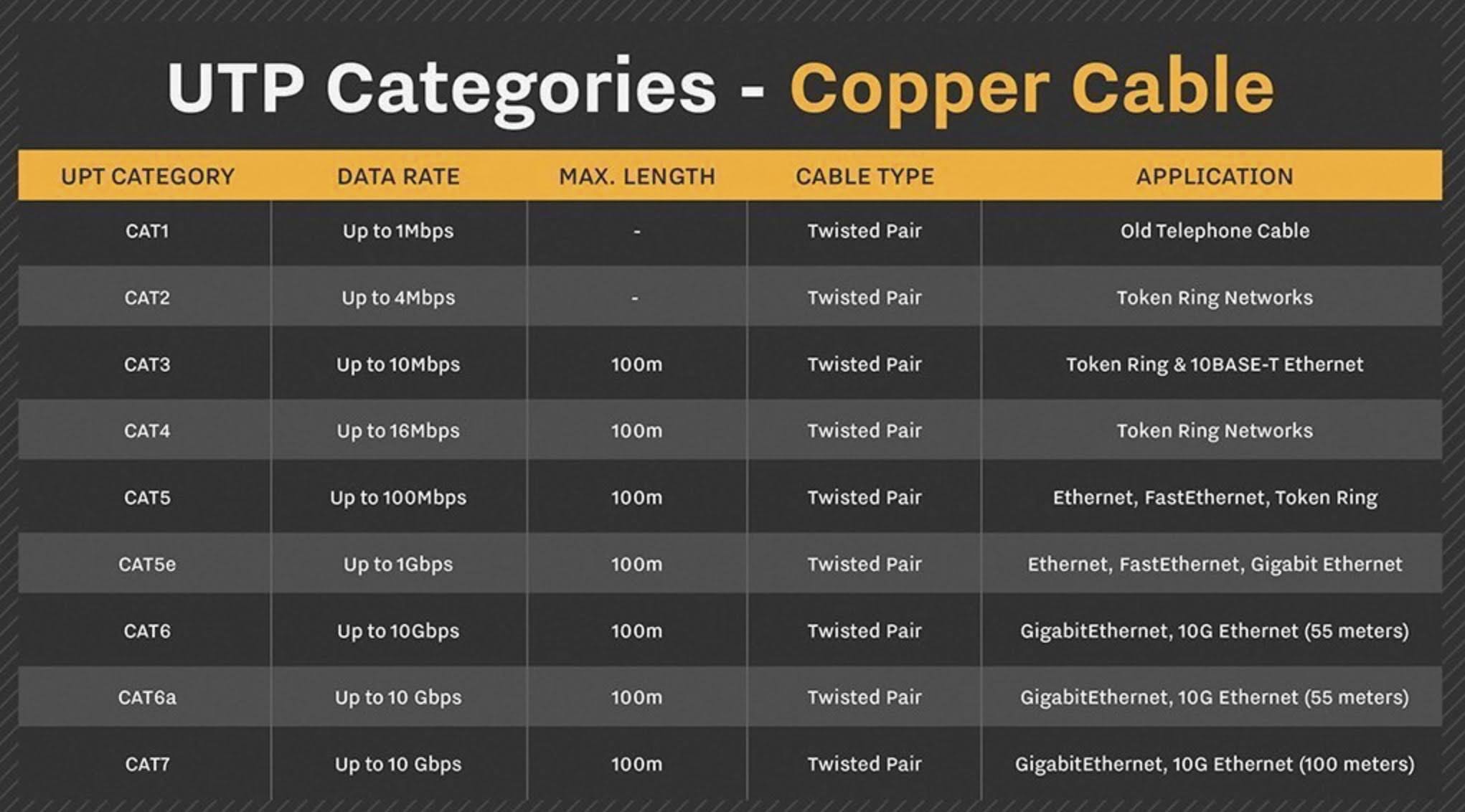
As it relates to structured cabling, crosstalk is electromagnetic interference from one unshielded twisted pair (UTP) to another. Typically, it occurs because they are running in close proximity to each other.
The currents traveling through these adjacent pairs of cabling create magnetic fields that interact and disrupt one another. There are several important terms to understand as crosstalk relates to cabling.
Near-end crosstalk (NEXT)
NEXT refers to a cable’s ability to reject crosstalk. In other words, the higher the NEXT value, the better the connection’s ability to reject crosstalk. The NEXT value is expressed in decibels per foot, and will vary significantly with the frequency of the transmission.
It is referred to as “near-end” because the interference between the cables is measured at the same end of the cable that is introducing the interference.
Power sum near-end crosstalk (PSNEXT)
PSNEXT is a NEXT metric that denotes the sum of crosstalk attribution from all adjacent pairs as the sum of the NEXT of the three-wire pairs as they impact the fourth pair in a four-pair cable system.
Evaluating for PSNEXT involves measuring all pair-to-pair crosstalk groupings, and then adding up the values for each pair. This evaluation mechanism was created to address the impact of adjacent pair transmissions. This is relevant for any connecting hardware and associated cabling.
PSNEXT evaluation is especially relevant for any cabling bandwidth in excess of 100 MHz. In other words, anything from Gigabit Ethernet to CAT 6 that uses four wire pairs bidirectionally and simultaneously.
Far-end crosstalk (FEXT)
FEXT is the measure of interference between two pairs of a cable. It is determined at the “far end” of a cable with an interfering transmitter.
Equal level far-end crosstalk (ELFEXT)
ELFEXT is the measure of the FEXT that contains attenuation compensation.
Alien crosstalk (AXT)
AXT is a measure of interference created by non-related cables routed in close proximity to the cable of interest.
Crosstalk in integrated circuit design
In an integrated circuit design, crosstalk refers to interfering signals. Typically, this will be a capacitive coupling to the nearest neighboring connection, although this can sometimes occur in signals that are further apart — especially as it relates to analog circuits.
There are a number of options available to address this scenario, including spacing circuits further apart, reordering wires and shielding pairs.
What is Gramm-Leach-Bliley Act (GLBA)?
The Gramm-Leach-Bliley Act (GLB Act or GLBA), also known as the Financial Modernization Act of 1999, is a federal law enacted in the United States to control the ways financial institutions deal with the private information of individuals. The Act consists of three sections: The Financial Privacy Rule, which regulates the collection and disclosure of private financial information; the Safeguards Rule, which stipulates that financial institutions must implement security programs to protect such information; and the Pretexting provisions, which prohibit the practice of pretexting or accessing private information using false pretenses. The Act also requires financial institutions to give customers written privacy policy notices that explain their information-sharing practices.
The GLBA repealed large portions of the Glass-Steagall Banking Act of 1933 and the Bank Holding Company Act of 1956. It amended the rules to permit banks, brokerage houses and insurance firms to merge. This created a new structural framework whereby a bank holding company could acquire full-service investment banks and insurance companies, while allowing the latter types of firms to form holding companies to acquire banks. As a consequence of GLBA, the U.S. Federal Reserve was granted expanded supervisory power to regulate these new types of financial structures.
What is the purpose of GLBA?
The standards established by GLBA complement data security requirements imposed by the Federal Deposit Insurance Corporation (FDIC). The purpose of the GLB Act is to ensure that financial institutions and their affiliates safeguard the confidentiality of personally identifiable information (PII) gathered from customer records in paper, electronic or other forms. The law requires affected companies to comply with strict guidelines that govern data security.
According to the law, financial institutions have an obligation to respect their customers’ privacy and securely protect their sensitive personal information against unauthorized access.
GLBA compliance requires that companies develop privacy practices and policies that detail how they collect, sell, share and otherwise reuse consumer information. Consumers also must be given the option to decide which information, if any, a company is permitted to disclose or retain for future use.
A related requirement governs data storage and security as part of a comprehensive written information security policy. This objective addresses protections against “any anticipated threats or hazards” to data that could result in “substantial harm or inconvenience” to consumers.
GLBA’s PII guidelines apply to any non-public personal information, which is defined as information a customer may provide to facilitate a transaction or which is otherwise obtained by the institution.
Data covered by GLBA
GLBA compliance is intended to decrease the likelihood an organization will have a data breach and face the resulting fallout, including significant financial and legal penalties and damage to its reputation. GLBA has become a top priority for chief information security officers and other IT professionals charged with managing corporate data.
Best practices have emerged, including internal risk assessments, periodic testing of internal controls and ensuring third-party compliance by business partners and service providers. Practical advantages of the law’s requirements include an increased ability to identify critical data, eliminate data errors, locate dark data, improve consolidation and enhance data classification.
Data that falls under the requirements of GLBA includes the following:
- addresses;
- bank account and financial data;
- biometric and related data;
- birth dates;
- car dealers;
- credit history (including property records or purchasing history);
- education level and academic performance;
- employment data;
- inferences drawn from other data;
- internet and other electronic information;
- geolocation data;
- names;
- personal income;
- Social Security data; and
- tax information.
Organizations regulated by GLBA
The passage of GLBA coincided with the emergence of internet technologies for transacting business, which in turn generated reams of new data and new ways of accessing data. The law broadened the definition of companies classified as financial institutions.
GLBA regulates any institution significantly engaged in financial activities. Even organizations that do not disclose non-public personal information are required by GLBA to develop a policy to protect information against potential future threats.
In addition to banks, brokerage firms and insurers, GLBA applies to companies that process loans or otherwise assume credit risk. Any organization that falls within the scope of GLBA must comply with its provisions, although individual states have the power to enact more stringent privacy regulations, as is the case in California and Virginia.
Professions and businesses subject to GLBA’s provisions include:
- accountants
- ATM operators
- car rental companies
- courier services
- credit reporting companies
- credit unions
- debt collectors
- financial advisory firms
- hedge funds
- non-bank mortgage lenders
- payday lenders
- property appraisers
- real estate firms
- retailers
- stockbrokers
- tax preparers
- universities
How GLBA compliance works
GLBA is broken into three main sections, each of which defines a subset of rules that govern compliance. The three sections include the following:
Financial Privacy Rule
This rule, often referred to as the Privacy Rule, places requirements on how organizations may collect and disclose private financial data. An organization must give “clear and conspicuous notice” of its privacy policy at the start of a customer relationship. Subsequently, customers must get an annual notice for the duration of the relationship, unless the organization meets certain criteria.
The Privacy Rule outlines which data will be collected, how it will be used and shared, who has access to it and the policies and procedures used to protect it. As required by the Fair Credit Reporting Act, customers are to be notified of the privacy policy annually, including the right to opt out of sharing information with unaffiliated third-party entities. If a customer agrees to share information, the organization must abide by the provisions of the original privacy notice.
Safeguard Rule
As the name implies, steps to ensure information security are the key focus of GLBA’s Safeguard Rule. The Federal Trade Commission (FTC) issued this rule in 2002 and continues to enforce it. The rule instructs organizations to implement administrative, physical and technical protections as safeguards against cyber attacks, email spoofing, phishing schemes and similar cybersecurity risks.
The rule also requires an organization designate at least one person to be accountable for all aspects of the information security plan, including development and regular testing. Data encryption and key management are recommended as best practices, but they are not FTC requirements under the Safeguard Rule.
Pretexting Rule
This rule aims to prevent employees or business partners from collecting customer information under false pretenses, such as social engineering techniques. Although GLBA does not have specific requirements regarding pretexting, prevention usually entails building employee training to avoid pretexting scenarios into the written information security document.
Who enforces GLBA requirements?
State and federal banking agencies have varying degrees of authority to enforce GLBA provisions. The FTC can take action in federal district courts against organizations that fail to comply with the Privacy Rule. Section 5 of GLBA grants the FTC the authority to audit privacy policies to ensure they are developed and applied fairly.
Enforcement of the Safeguard Rule remains with the FTC, although the Dodd-Frank Act in 2010 transferred new rulemaking authority to the Consumer Financial Protection Bureau (CFPB). Other federal agencies that play a role in GLBA enforcement include the Federal Reserve Board, the FDIC, the Office of Thrift Supervision and the Office of the Comptroller of the Currency. The responsibility for regulating insurance providers falls to individual states.
To avoid making compliance mistakes, a company may choose to hire independent consulting firms. These companies conduct a GLBA audit to assess an organization’s information security posture and develop strategies to stay abreast of changing legal regulations.
Penalties for GLBA noncompliance
Failure to comply with GLBA can have severe financial and personal consequences for executives and employees. A financial institution faces a fine up to $100,000 for each violation. Its officers and directors can be fined up to $10,000, imprisoned for five years or both. Companies also face increased exposure and a loss of customer confidence.
Heightened awareness of security risks is among the benefits companies may derive from GLBA compliance, especially as hackers develop more sophisticated tools to breach computer systems. Aside from enhanced brand reputation, a company can gain new insights from existing data and improve its data management capabilities.
Recent GLBA cases brought by the FTC include:
- Ascension Data and Analytics. In 2020, the Arlington, Texas, company agreed to an undisclosed financial settlement after a vendor, OpticsML, was found to have stored customer financial information in plain text in insecure cloud storage.
- PayPal. The online payment processor agreed to pay $175,000 to the state of Texas in 2018 to settle GLBA and Federal Trade Act violations that compromised data security and privacy of customers using its Venmo peer-to-peer application.
- TaxSlayer. Hackers were able to access nearly 9,000 of the Augusta, Ga., online tax preparer’s customer records for several months in 2015. The FTC said it failed to implement a comprehensive security program, including providing a privacy notice to customers, as required under GLBA. Under the settlement with the FTC, the company is prohibited from violating the GLBA’s Privacy Rule and the Safeguards Rule for 20 years and is required to have a third party assess its compliance every two years for 10 years.
Criticism, problems and GLBA revisions
Critics of the GLBA have contended the measure’s enforcement lacks the regulatory capabilities of the Health Insurance Portability and Accountability Act (HIPAA) and privacy regulations like those enacted in California. The GLBA places the responsibility on individuals to notify companies when they are opting out of data collection. The limited opt-out rights facilitate greater data sharing among larger entities, which is the opposite of what was intended, critics said.
Some economists blamed the GLBA for contributing to the 2008 financial recession. They argued the repeal of the Glass-Steagall Act opened the doors for banks to engage in speculative investments using short-term hedge funds and other high-yield, high-risk financial instruments.
Other financial experts claimed the GLBA played only a marginal role in the economic crisis. They pointed to a glut of Fannie Mae- and Freddie Mac-owned subprime mortgages that Congress directed be bought to supply affordable housing in low-income neighborhoods.
The CFPB revised the GLBA in 2018 to exempt some companies from the requirement to deliver annual privacy notices to customers under certain conditions. In general, financial institutions are exempted in two ways: if they restrict information sharing and don’t trigger a customer opt-out requirement or if there are no changes to the privacy policy previously delivered to the customer. The CFPB said the revision conforms with GLBA amendments established by Congress.
GLBA and GDPR
GLBA and Europe’s General Data Protection Regulation (GDPR) have different goals, but both define data security and consumer privacy. Whereas GLBA sets data privacy rules for financial institutions, GDPR encompasses any organization that processes an individual’s personal data in the course of transacting business.
Like GLBA, GDPR encourages companies to be more transparent in how they capture and handle sensitive information. That includes individuals’ personal data and any metadata that may be used to identify or characterize them.
In 2021, the Commonwealth of Virginia General Assembly passed the Virginia Data Protection Act, becoming the second U.S. state to enact regulations that toughen consumer protections. Virginia’s law mirrors many provisions in the California Privacy Rights Act (CPRA). CPRA is an expanded version of the California Consumer Privacy Act, which guarantees individuals the right to know all personal information a company may collect. CPRA gives Californians and others broad authority to obtain, delete and restrict the use of any personal data. Any organization that transacts business in California may be subject to CPRA provisions.
Illinois, New York, Oregon, Texas and Washington are updating existing security laws, and the National Association of Insurance Commissioners has developed a model law to enable states to develop laws that uniformly protect personal data.
What is Maximum Transmission Unit (MTU)?
The maximum transmission unit (MTU) is the largest size frame or packet — in bytes or octets (eight-bit bytes) — that can be transmitted across a data link. It is mainly used in reference to packet size on an Ethernet network using the Internet Protocol (IP).
Each device in a structure has a maximum transmission unit size that it can receive and disseminate. The MTU of the next receiving design is determined before sending a packet to it. If the packet is too large and the next receiving device cannot accept it, the packet is divided into multiple containers and sent. This is called fragmentation.
Fragmentation is bad for performance, as it adds delay and extra data. For best performance, the original sending device’s MTU is set as large as possible while still smaller than the MTU of all of the devices in the network between the sender and final receiver. In practice, a transmitting device will not know the MTU of all intermediary devices, but only of the next one in line.
Only IPV4 allows packet fragmentation. If a packet larger than the MTU is sent over IPv4, it will be automatically fragmented unless the do-not-fragment flag is set. IPv6 does not allow fragmentation. If a packet size exceeds the MTU in IPv6, it will be dropped.
What is Integrated Services Digital Network (ISDN)?
Integrated Services Digital Network (ISDN) is a set of communication standards for digital telephone connection and the transmission of voice and data over a digital line, and is a development of the plain old telephone service (POTS). These digital lines are commonly telephone lines and exchanges established by the government. They are used instead of the traditional circuits of the classic switched telephone network since they can integrate data and speech on the same line. Before ISDN, it was not possible for ordinary telephone lines to provide fast transmission over a single line.
ISDN was designed to run on digital telephone systems that were already in place. As such, it meets telecom’s digital voice network specifications. Originally, it was largely used by businesses that needed to support many desk phones and fax machines. However, it took so long for ISDN to be standardized that it was never fully deployed in the telecommunications networks it was intended for.
ISDN was formally standardized in 1988 and gained some significant popularity in the 1990s as a faster (128 Kbps) alternative to the 56 Kbps dial-up connection for internet access. However, as soon as telecom companies switched from analog to digital infrastructures, modern long-distance networking and broadband internet technologies eventually made it an obsolete technology.
ISDN can simultaneously transmit all kinds of data over a single telephone line. As such, voice and data are no longer separated as they were in earlier technologies, which used separate lines for different services. ISDN is a circuit-switched telephone network system, but it also allows access to packet-switched networks.
ISDN is also used with specific protocols, such as Q.931, where it acts as the network, data link and physical layers in the OSI model. Therefore, in broad terms, ISDN is actually a suite of transmission services on the first, second and third layers of the OSI model. [See also ISDN replacement – Sessions Initiated Protocol (SIP)]
There are three different ISDN iterations, although the third never obtained mainstream use. They are:
- Basic Rate Interface (BRI-ISDN): Basic Rate Interface (BRI) is the entry-level alternative that was generally used as the standard internet access option. It is capable of reaching data transmission speeds of up to 128 Kbps and was generally advertised for small business and home use. However, since the ISDN works over preexisting copper telephone lines, the speed rarely truly reached the 128 Kbps advertised by telecom companies. Also known as ISDN2, the BRI carried data over two 64 Kbps bearer channels (hence the name) known as B channels, while control information was handled by a 16 Kbps channel. The 16 kbps channel, known as the D (data) channel is used for protocol negotiation.
- Primary Rate Interface (PRI-ISDN): Primary Rate Interface (PRI) was a higher speed ISDN mostly intended for enterprise use as it supports full T1 speeds of 1.544 Mbps and up to 2.048 Mbps on E1 (E-carrier system). Instead of the two channels used for BRI, PRI makes full use of 23 parallel 64 Kbps bearer channels. E1 lines can support 30 bearer channels and were mostly used in Europe and Asia. They were also known as ISDN30 to differentiate them from ISDN2.
- Broadband ISDN (B-ISDN): Broadband ISDN (B-ISDN) is a very advanced form of ISDN that was designed to improve its performance even further over the PRI-ISDN. B-ISDN could run over fiber optic cables using ATM switching technology to transmit hundreds of Mbps of data both in download and upload. However, it was overtaken by ADSL technologies which made it obsolete before it could become a mainstream technology. It never saw any substantial practical application but still survives as a low-level, entry-level layer for DSL technologies and in WiMAX.
What is Amazon Machine Image (AMI)?
An Amazon Machine Image (AMI) is a master image for the creation of virtual servers — known as EC2 instances — in the Amazon Web Services (AWS) environment.
The machine images are like templates that are configured with an operating system and other software that determine the user’s operating environment. AMI types are categorized according to region, operating system, system architecture — 32- or 64-bit — launch permissions and whether they are backed by Amazon Elastic Block Store (EBS) or backed by the instance store.
Each AMI includes a template for the root volume required for a particular type of instance. A typical example might contain an operating system, an application server and applications. Permissions are also controlled to ensure that AMI launches are restricted to the appropriate AWS accounts. Block device mapping ensures that the correct volumes are attached to the launched instance.
What is NetBIOS (Network Basic Input/Output System)?
NetBIOS (Network Basic Input/Output System) is a network service that enables applications on different computers to communicate with each other across a local area network (LAN). It was developed in the 1980s for use on early, IBM-developed PC networks. A few years later, Microsoft adopted NetBIOS and it became a de facto industry standard. Currently, NetBIOS is mostly relegated to specific legacy application use cases that still rely on the suite of communication services.
NetBIOS has been used in Ethernet and Token Ring networks and, is included as part of the NetBIOS Extended User Interface (NetBEUI). Because NetBIOS is not a network protocol, it originally used NetBEUI to facilitate network communications on NetBIOS’s behalf. NetBEUI was used to create network delivery frames with data being loaded into the frame’s payload section. While NetBEUI could operate on a flat network, it could not route data between networks. Thus, NetBEUI was quickly replaced with a TCP/IP transport alternative and has long become extinct.
NetBIOS was originally created to standardize and free applications from having to understand the details of the network, including error recovery in session mode. A NetBIOS request is provided in the form of a network control block, or NCB, which, among other things, specifies a message location and the name of a destination.
NetBIOS delivers services at the session layer — Layer 5 — of the Open Systems Interconnection (OSI) model.
NetBIOS by itself is not a network protocol, as it does not provide a standard frame or data format for transmission. Thus, as mentioned, original NetBIOS iterations used a standard frame format that was provided by the NetBEUI protocol and later revisions used the IPX (Internetwork Packet Exchange)/SPX (Sequenced Packet Exchange) and TCP/IP (Transmission Control Protocol/Internet Protocol) protocols, which operate at Layer 3 and 4 of the OSI model.
NetBIOS may still be in use when it is combined with the TCP/IP protocol suite on enterprise networks. This combination is referred to as NetBIOS over TCP/IP (NBT). NetBIOS for Microsoft operating systems is only supported on IP version 4 networks and is not compatible with the newer IP version 6 protocol stack.
NetBIOS provides two communication modes: session or datagram. Session mode enables two computers to establish a connection for a conversation, enables larger messages to be handled, and provides error detection and recovery. Datagram mode is connectionless, so each message is sent independently, messages must be smaller, and the application is responsible for error detection and recovery. Datagram mode also supports the broadcast of a message to every computer on the LAN.
What is the difference between NetBIOS and DNS?
Both NetBIOS and the domain name system (DNS) use naming processes that map physical or logical computer addresses to names that are easier for humans to work with. In the case of DNS, a computer or device’s IP address is mapped to a unique domain name such as techtarget.com. From a NetBIOS over TCP/IP perspective, the IP address is mapped to a human-friendly NetBIOS name that uses up to 16 alphanumeric characters. However, note that Microsoft’s implementation of NetBIOS reserves one of those 16 characters to define specific NetBIOS functions. Thus, Microsoft NBT uses names up to 15 alphanumeric characters long.
The other major difference between DNS and NetBIOS is that DNS uses a hierarchical naming structure while the NetBIOS structure is flat. With DNS, a “.” designates the hierarchy within the system. For example: test1.techtarget.com and test2.techtarget.com both live within the “.com” top-level domain and “.techtarget” second-level domain. This enables improved efficiencies within the mapping structure itself.
NetBIOS, on the other hand, does not use a hierarchical or nested structure. Instead, all devices on a corporate LAN reside inside a single, flat structure. This makes NetBIOS far less scalable as the number of devices increases when compared to DNS.
Finally, DNS has become far more popular compared to NetBIOS. DNS is used on virtually all corporate networks and across the internet, while NetBIOS is now only used for legacy application use cases.
What is Remote Desktop Connection Manager (RDCMan)?
Remote Desktop Connection Manager is a tool that enables information technology administrators to organize, group and control remote desktop connections. It was created by a developer on the Windows Live Experience team to improve the management of multiple remote desktop protocol connections.
Using RDCMan, system administrators can supervise multiple RDP connections in a single window, use different RDP settings for separate servers or groups and save user credentials, allowing for automatic authentication on RDP and remote desktop service servers.
The tool is especially useful for individuals who work with groups of computers or large server farms where regular access to each machine is required. This includes system administrators, lab managers, developers and testers. RDCMan helps these individuals by consolidating multiple RDP connections into a single window, thus reducing desktop clutter.
RDCMan is a free tool which can be downloaded from the Microsoft website. It supports all versions of Windows, including Windows 10 and Windows Server 2019. However, Microsoft urges its customers to use the Microsoft Terminal Services Client or a universal remote desktop client for Windows 10 instead of RDCMan, stating that the RDCMan tool is unable to keep up with continuing advancements in technology.
Microsoft discontinued its Remote Desktop Connection Manager application in March 2020 after the discovery of a major security flaw. Microsoft encourages users to migrate to the free Microsoft Remote Desktop app (which runs the Microsoft Terminal Services Client) or the Remote Desktop Connection tool that is built into Windows.
Other alternatives to RDCMan include Remote Desktop Manager Standard Edition from Devolutions, which offers Windows PowerShell support and integrates with Microsoft Azure. Another alternative is the Terminals Remote Desktop Client, which is available on CodePlex. Other options include MultiDesk, which emphasizes security and only enables a connection after the user confirms a shared piece of information, and mRemoteNG, which is open source.
What is Turing Test?
The Turing Test is a method of inquiry in artificial intelligence (AI) for determining whether or not a computer is capable of thinking like a human being. The test is named after Alan Turing, the founder of the Turing Test and an English computer scientist, cryptanalyst, mathematician and theoretical biologist.
Turing proposed that a computer can be said to possess artificial intelligence if it can mimic human responses under specific conditions. The original Turing Test requires three terminals, each of which is physically separated from the other two. One terminal is operated by a computer, while the other two are operated by humans.
During the test, one of the humans functions as the questioner, while the second human and the computer function as respondents. The questioner interrogates the respondents within a specific subject area, using a specified format and context. After a preset length of time or number of questions, the questioner is then asked to decide which respondent was human and which was a computer.
The test is repeated many times. If the questioner makes the correct determination in half of the test runs or less, the computer is considered to have artificial intelligence because the questioner regards it as “just as human” as the human respondent.
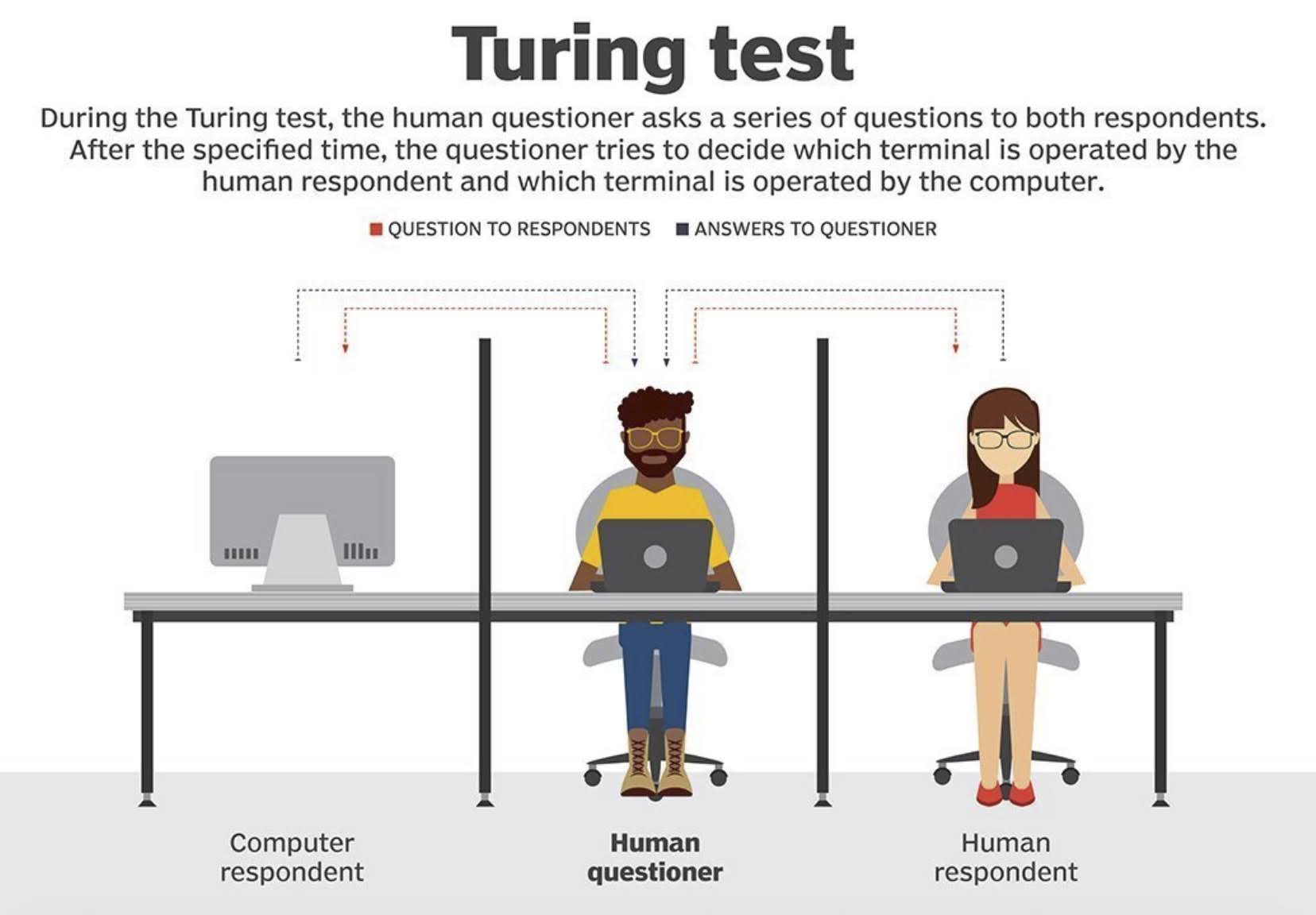
What is Azure Kubernetes Service (AKS)?
Azure Kubernetes Service is a managed container orchestration service based on the open source Kubernetes system, which is available on the Microsoft Azure public cloud. An organization can use AKS to handle critical functionality such as deploying, scaling and managing Docker containers and container-based applications.
AKS became generally available in June 2018 and is most frequently used by software developers and IT operations staff.
Kubernetes is the de-facto open source platform for container orchestration but typically requires a lot of overhead in cluster management. AKS helps manage much of the overhead involved, reducing the complexity of deployment and management tasks. AKS is designed for organizations that want to build scalable applications with Docker and Kubernetes while using the Azure architecture.
An AKS cluster can be created using the Azure command-line interface (CLI), an Azure portal or Azure PowerShell. Users can also create template-driven deployment options with Azure Resource Manager templates.
What is natural language understanding (NLU)?
Natural language understanding is a branch of artificial intelligence that uses computer software to understand input in the form of sentences using text or speech.
NLU enables human-computer interaction. It is the comprehension of human language such as English, Spanish and French, for example, that allows computers to understand commands without the formalized syntax of computer languages. NLU also enables computers to communicate back to humans in their own languages.
The main purpose of NLU is to create chat- and voice-enabled bots that can interact with the public without supervision. Many major IT companies, such as Amazon, Apple, Google and Microsoft, and startups have NLU projects underway.
How does natural language understanding (NLU) work?
NLU analyzes data to determine its meaning by using algorithms to reduce human speech into a structured ontology — a data model consisting of semantics and pragmatics definitions. Two fundamental concepts of NLU are intent and entity recognition.
Intent recognition is the process of identifying the user’s sentiment in input text and determining their objective. It is the first and most important part of NLU because it establishes the meaning of the text.
Entity recognition is a specific type of NLU that focuses on identifying the entities in a message, then extracting the most important information about those entities. There are two types of entities: named entities and numeric entities. Named entities are grouped into categories — such as people, companies and locations. Numeric entities are recognized as numbers, currencies and percentages.

Comparison between NLU, NLP, and NLG
NLU is a subset of natural language processing (NLP). NLP attempts to analyze and understand the text of a given document, and NLU makes it possible to carry out a dialog with a computer using natural language.
While both understand human language, NLU communicates with untrained individuals to learn to understand their intent. In addition to understanding words and interpret meaning, NLU is programmed to understand meaning despite common human errors, such as mispronunciations or transposed letters and words.
The other subset of NLP is natural language generation (NLG). NLG enables computers to automatically generate natural language text, mimicking the way humans naturally communicate — a departure from traditional computer-generated text.
Generally, computer-generated content lacks the fluidity, emotion and personality that makes human-generated content interesting and engaging. However, NLG can use NLP so that computers can produce humanlike text in a way that emulates a human writer. This is done by identifying the main topic of a document, and then using NLP to determine the most appropriate way to write the document in the user’s native language. Text is generated based on this decision.
For example, using NLG a computer can automatically generate a news article based on a set of data gathered about a specific event or produce a sales letter about a particular product based on a series of product attributes.
How to apply Natural language understanding (NLU)?
Here are examples of applications that are designed to understand language as humans do, rather than as a list of keywords. NLU is the basis of speech recognition software — such as Siri on iOS — that works toward achieving human-computer understanding.
- Interactive Voice Response (IVR) and message routing: IVR is used for self-service and call routing. Early iterations were strictly touchtone and did not involve AI. However, as IVR technology advanced, features such as NLP and NLU have broadened its capabilities and users can interact with the phone system via voice. The system processes the user’s voice, converts the words to text, and then parses the grammatical structure of the sentence to determine the probable intent of the caller.
- Customer support and service through intelligent personal assistants: NLU is the technology behind chatbots, which is a computer program that converses with a human in natural language via text or voice. Chatbots follow a script and can only answer questions in that script. These intelligent personal assistants can be a useful addition to customer service. For example, chatbots are used to provide answers to frequently asked questions. Accomplishing this involves layers of different processes in NLU technology, such as feature extraction and classification, entity linking and knowledge management.
- Machine translation (ML): ML is a branch of AI that enables computers to learn and change behavior based on training data. Machine learning algorithms are also used to generate natural language text from scratch. In the case of translation, a machine learning algorithm analyzes millions of pages of text — say, contracts or financial documents — to learn how to translate them into another language. The more documents it analyzes, the more accurate the translation. For example, if a user is translating data with an automatic language tool such as a dictionary, it will perform a word-for-word substitution. However, when using machine translation, it will look up the words in context, which helps return a more accurate translation.
- Data capture: Data capture is the process of gathering and recording information about an object, person or event. For example, if an e-commerce company used NLU, it could ask customers to enter their shipping and billing information verbally. The software would understand what the customer meant and enter the information automatically.
- Conversational interfaces: Many voice-activated devices — including Amazon Alexa and Google Home — allow users to speak naturally. By using NLU, conversational interfaces can understand and respond to human language by segmenting words and sentences, recognizing grammar, and using semantic knowledge to infer intent.
What is Customer Journey Map?
A customer journey map is a diagram (or several diagrams) that depicts the stages customers go through when interacting with a company, from buying products online to accessing customer service on the phone to airing grievances on social media.
To create effective visual maps that reflect customers’ journeys through these channels, journey maps must be rooted in data-driven research and must visually represent the different phases customers experience based on a variety of dimensions, including customer sentiment, goals, and touchpoints.
To be comprehensive, companies often need to create several customer journey maps based on a 360-degree view of how customers engage with the company. For example, one journey map may begin with a customer using Twitter to comment about a company, product, or brand, then using the phone to reach a customer service line, and, finally, using the company website. Another scenario may begin with online browsing, proceed to a phone inquiry, and so on.
What is Digital Divide?
The digital divide refers to the difference between people who have easy access to the latest and most modern communication and information technology and those who do not. In recent times, internet access is increasingly seen as the primary advantage that many technologies can grant in that it represents a staggering store of knowledge and resources. In this sense, the term now generally refers to those who have access to internet and those who do not.
The digital divide was once used to describe different rates of technology adoption by different groups and included old communication technology such as telephone and television.
Today, the digital divide may be shrinking as cheaper mobile devices proliferate and network coverage improves worldwide.
What is Node?
A node is a point of intersection/connection within a data communication network. In an environment where all devices are accessible through the network, these devices are all considered nodes. The individual definition of each node depends on the type of network it refers to.
For example, within the physical network of a smart home domotics system, each home appliance capable of transmitting or receiving information over the network constitutes a node. However, a passive distribution point such as a patch panel would not be considered a node.
Nodes create, receive and communicate information and store it or relay it to other nodes. For example, a scanner in a computer network creates images and sends them to a computer, while a router organizes data received from the internet and distributes it to the individual devices within the network.
The concept of nodes works on several levels, but the big-picture view defines nodes as the major centers through which internet traffic is typically routed. This usage is somewhat confusing, as these same internet nodes are also referred to as internet hubs.
What is Tech ethicist?
Tech ethicist is a corporate role that involves examining a company’s technologies to ensure that they meet ethical standards, that they do not exploit user vulnerabilities, for example, or infringe upon user rights. The term also refers to independent experts.
Although there is no standard education stream for tech ethicists yet, to fill that role an individual would need grounding in not only ethics and technology but also psychology, law and sociology, among other things. Tech ethicist David Polgar likes to compare the tasks of engineers and ethicists: Engineers see a problem and find a solution, after which the ethicist sees the solution and looks for problems.
Technology ethics is an increasingly important area of focus as the sophistication and capacities of technologies have advanced far ahead of concerns for security, privacy and the well-being of users. The humane tech movement seeks to change that focus to realign technology with humanity. As that movement develops, the demand for tech ethicists is likely to grow.
“Data breaches and privacy scandals have made it vital for organizations to prioritize tech ethics and consider the effects IoT devices and AI will have on individuals and society.” – Jessica Groopman
Related Terms: data protection officer (DPO), AI code of ethics, responsible AI, California Consumer Privacy Act, General Data Protection Regulation
What is Form Factor?
A form factor is the overall design and functionality of a computer or piece of electronic hardware. It is usually highlighted by a prominent feature, such as a QWERTY keyboard, a touch screen or the way the device opens and closes. In essence, it is the schematic template that defines the specifications about the layout of a certain device, such as its size, number of ports, power supply type and position of components.
A form factor can also serve as a standard or category that can be used to ensure that there is a level of hardware compatibility between devices of similar types, even though they may come from different manufacturers. In this regard, form factor is important, as it affects both the aesthetics and recognizability of a given device as well as its performance and usability.
The term sometimes refers to programming or software as well. In this case, it describes the size of the program, such as the amount of memory needed to run it.
Form factors are commonly associated with electronic devices and components, like cell phones and motherboards. In the terms of a motherboard, the form factor refers to the kind of hardware peripherals it can support and also somewhat defines the structure of the motherboard. It may also highlight some ad hoc standards.
For cell phones, form factor refers to the physical dimensions, overall design and shape of the phone, such as the traditional candy bar form, which differs from the flip and slide form factors. Modern phones typically have a face dominated by a touchscreen, a form factor known as the slate form factor. Another notable example are notebook computers, which are considered a form factor of their own because of their rectangular “clamshell” shape. Another form factor for portable computers is the convertible tablet, which can be used either with a physical keyboard or as a touch screen.
Because motherboards follow a certain standard or form factor, it is easy to look for a replacement; the user just has to find one that follows the same form factor. Examples of motherboard form factors include the ATX (Advanced Technology Extended) and micro-ATX form factors. Since 2007, Intel’s ATX represents the industry standard governing the design and size of nearly all modern PC motherboards.
It is important to understand that the standards are optional and may or may not be adhered to by manufacturers. That said, in some cases form factors become crucial, such as when upgrading a motherboard. The shape of the motherboard, in fact, generally dictates the size of the case, which in turn, constitutes another form factor (e.g., full tower, mid-tower, desktop, micro PC, etc.) with different specifics in terms of available size, number of ports and more.
For disk storage, form factor is nearly always used to describe the diameter of the disk platter. The various standards depend on the type of hard drives: including 5.25 inches for optical drives, 3.5 inches for PC hard drives, and 2.5 inches (or less) for notebooks.
What is Hand Coding?
Hand coding involves writing functional code or layout directions in the basic languages in which they are compiled. The alternative is to use various kinds of tools to implement coding conventions without having to hand code them in the original languages.
To understand the idea of hand coding, it is necessary to understand how computer programming evolved over the last 30 years. In the earliest years of programming, languages like Basic and Fortran were always hand coded. Users did not have elaborate programs that would allow them to code in an automated manner.
Eventually, with Windows-based computing and other advances, tech companies evolved products that could automate some kinds of hand coding for either programming or layout purposes. One of the main examples is the wide spectrum of tools that allow users to avoid hand coding HTML, the underlying language for a lot of Web source code. Actual HTML commands are syntactically complex and challenging for many people. Companies created tools that would allow users to visually lay out Web pages instead of hand coding the HTML, or in other words, writing out all of the HTML layout or actions.
Other kinds of tools helping people to avoid hand coding are sometimes called what you see is what you get (WYSIWYG) editors. The idea here is that the display mimics the eventual result, hiding the actual hand coding from the person who is doing the layout. In the coding world, some tools allow for automated coding, but hand coding is still a major part of what programmers do on a regular basis. Many professionals would not want to abstract the coding process too much, because he could get in the way of understanding and reading code as it is written. For example, MS Visual Basic includes visual forms for windows, text boxes and more, but the fundamental code is still visible in clickable windows and menu options, so that programmers still have to hand code the functionality of these devices.
What is Programming Logic?
Programming logic is a fundamental construct that’s applied to computer science in a variety of comprehensive ways.
Programming logic involves logical operations on hard data that works according to logical principles and quantifiable results.
The term programming logic has its roots in the advancement of computer science. Programming logic started only with ‘hard and fast logic’ compiled into sophisticated algorithms and expressed in programming languages like Prolog.
Basic computers developed ways to deal with numbers and logical states, applying specific operators that lead to precise results.
The important distinction here is that programming logic, and logic in general, is fundamentally set against other kinds of programming that are not built on hard logic or quantifiable states and results.
For example, modal logic by its nature is set against the theoretical quantum operations that don’t provide a specific set state that computers can apply logic to.
Programming logic in general rests on a foundation of computational logic that is shared by both humans and machines, which is what we explore as we continue to interact with new technologies. With that in mind, one could develop more specific definitions of a programming logic having to do with the basis of a piece of code.
What is Digital Asset?
A digital asset is any text or media that is formatted into a binary source and includes the right to use it; digital files that do not include this right are not considered digital assets. Digital assets are categorized into images and multimedia, called media assets, and textual content.
Digital assets are files that continue to exist as technology progresses regardless of the device where the digital asset is stored or created. Distinguishing and defining the various types of digital assets can help in digital assets management. As conventional broadcast, print and graphic assets are gradually transformed into an advanced digital form, digital assets are becoming increasingly important, leading to growth in the digital asset management industry. Big corporations like Oracle, Microsoft, Apple and many others are consistently growing their enterprise to provide third-party digital asset management through Web-based repositories.
What is Heuristic Programming?
Heuristic programming approaches the idea of artificial intelligence by solving problems using experience-based rules or protocols.
In general, the word ‘heuristic’ in computer science refers to a philosophy that is different from the quantifying, logic-driven computer processes that powered the advance of primitive computers in past decades.
Contrary to the principle of using strict algorithm-based computing, heuristics is in many key senses a shortcut to a quantified logic type of programming. Heuristic programming seeks to achieve a goal by substituting certain kinds of machine learning programs for logical algorithms.
Another way to say this is that while algorithms operate on known systems and logical principles, heuristic programming operates on a series of ‘intelligent guesses’ or informed operations that are not entirely based on hard numbers or hard data.
One example of a heuristic programming process is a program that will analyze the contents of a drive or file system. The logical program would search in a pre-programmed way, for example, alphabetically or in terms of recent data modification, where the heuristic programming system might be programmed to perform according to past searches that a user originated.
Here, the machine is learning from the user. Another good example of heuristic programming is in the use of natural language processing tools. In addition to sophisticated algorithms, many of these programs are using machine learning or heuristic programming principles, where the program analyzes past input from the user and factors it into the core processes that provide results.
What is Extreme Programming (XP)?
Extreme Programming (XP) is an intense, disciplined and agile software development methodology focusing on coding within each software development life cycle (SDLC) stage. These stages are: Continuous integration to discover and repair problems early in the development process Customer involvement and rapid feedback These XP methodology disciplines are derived from the following four key values of Kent Beck, XP’s originator: Communication: Communication between team members and customers must occur on a frequent basis and result in open project discussion without fear of reprisal. Simplicity: This involves using the simplest design, technology, algorithms and techniques to satisfy the customer’s needs for the current project iteration. Feedback: Feedback must be obtained at multiple, distinct levels, e.g., unit tests, code review and integration. Courage: Implement difficult but required decisions.
In addition to the key values, XP methodology implementation also requires the support of the three principles of incremental change, embracing change and quality work. Twelve key practices also must be followed: Some traditional methodology practitioners criticize XP as an “unreal” process causing reckless coding. Several traditional software developers find XP inflexible with low functionality and little creative potential. Additional criticisms are that XP: Has no structure. Lacks essential documentation. Has no clear deliverables, i.e., realistic estimates are difficult because the entire project requirement scope is not fully defined. (This lack of detailed requirements makes XP highly prone to scope creep.) Needs cultural change for adoption. (May work for senior developers only) Is costly, i.e., requires frequent communication/meeting at the customer’s expense, which may lead to difficult negotiations. Has possible inefficiency from frequent code changes within various iterations. Of course, as with any development methodology, all this is very subjective and dependant on personal preferences.
What is Natural Language Processing (NLP)?
Natural language processing (NLP) is a method to translate between computer and human languages. It is a method of getting a computer to understandably read a line of text without the computer being fed some sort of clue or calculation. In other words, NLP automates the translation process between computers and humans.
Traditionally, feeding statistics and models have been the method of choice for interpreting phrases. Recent advances in this area include voice recognition software, human language translation, information retrieval and artificial intelligence. There is difficulty in developing human language translation software because language is constantly changing. Natural language processing is also being developed to create human readable text and to translate between one human language and another. The ultimate goal of NLP is to build software that will analyze, understand and generate human languages naturally, enabling communication with a computer as if it were a human.
What is Asimov’s Three Laws Of Robotics?
Isaac Asimov’s Three Laws of Robotics are an invention of this author first pioneered in his 1942 story “Runaround” and then incorporated into the “Robot” series and “Foundation” series of books that Asimov generated over a period of time from the 1950s to the 1980s. Asimov’s Three Laws of Robotics are proscriptive rules governing what robots can and cannot do, according to a fairly complex logical moral code.
The Three Laws of Robotics can be found in Asimov’s 5-book “Robot” series of novels, and in some of the 38 short stories which the author wrote from 1950 to 1985. Another series, the “Foundation” series, began in the 1950s and finished in 1981.
Asimov’s Three Laws are as follows:
- A robot may not injure a human being or allow a human to come to harm.
- A robot must obey orders, unless they conflict with law number one.
- A robot must protect its own existence, as long as those actions do not conflict with either the first or second law.
In many ways, Asimov’s Three Laws of Robotics provide a kind of window into the digital age, in which robotics is now very real. Long before artificial intelligence became practical, Asimov anticipated some of its effects, and created this overall moral criteria to govern his fictional universe. In many ways, these ideas can provide guidance for the kinds of technologies likely to be generated throughout the 21st century.
What is Change Control?
Change control is a systematic approach to managing all changes made to a product or system. The purpose is to ensure that no unnecessary changes are made, all changes are documented, services are not unnecessarily disrupted and resources are used efficiently. Within information technology (IT), change control is a component of change management.
The change control process is usually conducted as a sequence of steps proceeding from the submission of a change request. Typical IT change requests include the addition of features to software applications, the installation of patches and upgrades to network equipment or systems.
Here’s an example of a six-step process for a software change request:
- Documenting the change request. The client’s change request or proposal is categorized and recorded along with informal assessments of the importance of that change and the difficulty of implementing it.
- Formal assessment. This step evaluates the justification for the change and the risks and benefits of making or not making the change. If the change request is accepted, a development team will be assigned. If the change request is rejected, that is documented and communicated to the client.
- Planning. The team responsible for the change creates a detailed plan for its design and implementation, as well as for rolling back the change should it be deemed unsuccessful.
- Designing and testing. The team designs the program for the software change and tests it. If the change is deemed successful, the team requests approval and implementation date.
- Implementation and review. The team implements the program and stakeholders review the change.
- Final assessment. If the client is satisfied with the implementation of the change, the change request is closed. If the client is not satisfied, the project is reassessed and steps may be repeated.
“Effective change control processes are critical for incorporating necessary changes, while ensuring they do not disrupt other project activities or delay progress.” – Wesley Chai
Related Terms: change request, IT procurement, change management, ITIL, IT project management
What is Spear Phishing?
Spear phishing is a variation on phishing in which hackers send emails to groups of people with specific common characteristics or other identifiers. Spear phishing emails appear to come from a trusted source but are designed to help hackers obtain trade secrets or other classified information.
The difference between spear phishing and a general phishing attempt is subtle. A regular phishing attempt appears to come from a large financial institution or social networking site. It works because, by definition, a large percentage of the population has an account with a company with huge market share.
In spear phishing, an email appears to come from an organization that is closer to the target, such as a particular company. The hacker’s goal is to gain access to trusted information. This is often as simple as looking up the name of a CEO from a corporate website and then sending what appears to be a message from the boss to email accounts on the corporate domain.
What is Soft Robotics?
Soft robotics is the subset of robotics that focuses on technologies that more closely resemble the physical characteristics of living organisms. Experts describe the soft robotics approach as a form of biomimicry in which the traditionally linear and somewhat stilted aspects of robotics are replaced by much more sophisticated models that imitate human, animal and plant life.
One of the easiest ways to describe soft robotics is to describe the traditional robot. The robot as portrayed decades before its current evolution was a set of boxes and tubes. Its surfaces were hard metal. It moved in very specific linear ways.
The soft robotics movement aims to transform that into a new type of robotics where robots look, act and feel like biological humans, animals or plants. One fundamental aspect of soft robotics is the creation of intricate, many-segmented units that can move in a more versatile way, for example, instead of a hard metal surface, a surface made up of tiny metal parts that can move like human skin. Soft robotics is being applied to many of the projects at the vanguard of the new robotics industry where robots are becoming more and more humanlike, as in the case of Sophia, a robot that received citizenship from the country of Saudi Arabia.
What is Digital experience (DX)?
Digital experience (DX), or digital user experience, is the take-away feeling an end user has after an experience in a digital environment. Traditionally, the digital user experience (UX) was the province of Web designers and Web content management.
Today, DX still refers to elements such as colors, layout, navigability and performance of a webpage — but in addition, it may also refer to elements such as how intuitive a page or mobile app is, how efficiently users can complete actions (how many clicks or swipes are required) or how well integrated an app or page is with other applications.
Accordingly, the scope of DX has broadened as the sophistication of online environments has grown and diversified beyond a webpage to encompass wearables as well as applications that incorporate virtual reality and augmented reality components. DX now has to encompass these many entities and also factor in usability from the perspective of a user having many devices and, possibly, multiple identities in his consumer and professional lives. Customer journey maps can play an important role in helping to evaluate digital user experience and understand a user’s motivation, point of entry and frustrations that impede engagement.
“As digital interactions continue to grow, so do the number of touchpoints across an organization, requiring the adoption of new channels and approaches to interacting with customers.” – Sandra Mathis
Related Terms: wearable technology, virtual reality, customer journey map, customer experience, customer experience management
What is Wearable Robot?
A wearable robot is a specific type of wearable device that is used to enhance a person’s motion and/or physical abilities.
Wearable robots are also known as bionic robots or exoskeletons.
One of the general principles of a wearable robot is that it involves physical hardware for assisting with human motion. Some models of wearable robots can help individuals to walk, which may be used for post-surgery or rehab purposes.
A particular characteristic of the wearable robot interface is that these pieces of hardware can be programmed in a variety of ways. Sensors or devices can take in verbal, behavioral or other input in order to facilitate specific types of movement. These kinds of resources represent an exciting application of new technology to medical use, where paralyzed or disabled individuals may benefit greatly from these wearable robots, which involve the junction of sophisticated new hardware, big data and wireless technologies.
What is Artificial Intelligence Robot (AIBO)?
Artificial Intelligence Robot or AIBO is a name for a Sony product developed as a robotic pet. Multiple instances of this product line are available in the United States, although they come with price tags of up to several thousand dollars. The AIBO uses an Open-R modular platform to create a life-like interface including voice recognition, machine learning and the ability to respond to stimulus.
The Sony AIBO was released in 1999, and is considered to be the most sophisticated robot ever offered to consumers. While the majority of AIBOs resembled dogs, different models were available as well. Despite the product’s popularity, it was discontinued in 2006, with all support ending in 2013. Sony cited lack of profitability as the reason for its discontinuation.
Along with the Sony AIBO products, the term “artificial intelligence robot” can be used to refer to a broad spectrum of robotic projects that generally aim to simulate human or animal life. Different types of artificial intelligence robots are being engineered that can hold conversations with humans, respond to body language, and perform various kinds of cognitive tasks. Many of these are also highly lifelike in appearance and built to actual human size. The phenomena of the artificial intelligence robot raises many questions about how we as people will interact with technologies in the future.
Question and Answer
Why is consumer ML/AI technology so “disembodied” compared to industrial mechanical/robotics projects?
The question of why robotics has not kept pace with machine learning and artificial intelligence (AI) work in consumer electronics is an interesting one, and one that sheds light on where technology is apt to go in the future.
Different analysts will give different reasons for why robotics is not more prominent in the consumer markets. One suggestion is that the internet of things is a new phenomenon that will take time to evolve, where robotics will become part of that consumer model. Another compelling argument is that robotics is simply expensive for consumers – for instance, in recent weeks, a company called UBTECH announced the market debut of the “Lynx” robot containing Amazon’s Alexa AI platform. The fact that consumers are not flocking to store aisles to purchase Lynx, combined with its retail price of $800, provides an excellent example of why a lack of robotics is a result of a general lack of consumer demand.
However, this can’t fully explain the current lack of consumer robotics products on the market. Products like Roomba, an autonomous vacuum cleaner, have been popular for years, and network connectivity along with artificial intelligence progress mean tomorrow’s robots can be smarter, more agile and more capable. Some sources suggest that there is actually due to be a real boom in consumer robotics – for instance, a Robo Global article from August of 2016 encourages investors to become involved in what writers understand to be an industry that’s headed toward rapid growth.
Another way to understand this is to contrast the consumer market with robotics in business technology. Industrial systems often use robotic installations equipped with cutting-edge artificial intelligence capabilities, or at least smart mechanical systems with machine-to-machine communication and data capture setups. One evident difference is that the main role of technology in industrial settings is to manufacture and produce products, where the main role of technology in the consumer world is to enable communications and enhance personal experience. However, there is a good case to be made that consumer robots are coming our way sooner rather than later.
Free Tool
BorgBackup is an open-source deduplicating archiver that features compression and authenticated encryption for efficient storage of your backups.
Scrapli is a fast and easy Python 3.6+ screen-scraping client for network devices. This flexible tool offers great editor support, sync/async, a pluggable transport system, the ability to add new device support, a Nornir plugin as well as options for NETCONF devices.
Dog is a distributed firewall management system for Linux that can manage hundreds of per-server firewalls, with consistent network access rules across servers in different regions across multiple providers. Features defense-in-depth, beyond gateway firewalls; constantly updated blocklists with thousands of addresses distributed across many servers; connection and/or bandwidth usage limits; and auto updates of per-server iptables rules.
ImportExcel is a PowerShell module for importing and exporting Excel spreadsheets without involving Excel. Allows you to read/write Excel files without the Excel COM-object, so you can more easily create tables, pivot tables and charts. “the ImportExcel function in Powershell (all bow before the great and mighty Doug Finke) is life-changing if you manipulate data inside Powershell. If anything deserves a shout-out, it does.”
sg3_utils is a set of Linux utilities for sending SCSI commands to devices. Works with transports like FCP, SAS, SPI as well as less-obvious devices that use SCSI, like ATAPI cd/dvd drives and SATA disks that connect through a translation layer or bridge device.
Free Carrier Lookup allows you to enter any phone number to get the carrier name and whether the number is wireless or landline. Provides the latest data so it stays current and accurate for most countries. Also offers the email-to-SMS and email-to-MMS gateway addresses for US and Canadian phone numbers.
pyWhat enables you to easily identify emails, IP addresses and more. Feed it a .pcap file or some mysterious text or hex of a file, and it will tell you what it is. The tool is recursive, so it can identify everything in text, files and more. A shout out to the tool’s author for sharing his creation.
Arkime is secure, scaleable, indexed packet capture and search tool that can improve your network security by providing greater visibility. This open-source tool stores and indexes network traffic in standard PCAP format.
Kimchi is an open-source HTML5-based KVM management tool that is designed for ease of use. This web-based virtualization management platform provides an intuitive, flexible interface that displays and provides control of all the VMs running on a system. Allows you to manage most of the basic features you need to create and control a set of guest virtual machines.
Cloud Foundry is an open-source tool for writing code in any language, with any framework, on any Kubernetes cluster. Provides a highly secure environment in which you can bypass complex configuration and routine operational tasks. Integrates with your environment and tools, including CI/CD and IDEs. Security patches are implemented quickly in response to vulnerabilities, so it stays safe for sensitive, mission-critical application development.
Octopus Deploy is an easy, centralized tool to automate your deployments and operations runbooks. Integrates with your favorite CI server and brings with it fantastic enhanced deployment/ops automation capabilities. Free for 10 deployment targets. We likes it “for .NET application deployment. Create some pipelines in Azure DevOps and send packages into Octopus for deployments. Really great for managing environments, variables, and credentials amongst other things.”
Packetbeat is a lightweight, zero-latency-overhead network packet analyzer that sends data from your hosts and containers to Logstash or Elasticsearch. This passive tool lets you keep tabs on application latency and errors, response times, SLA performance, user access patterns and trends, and more so you can understand how traffic is flowing through your network.
Openfire is a powerful instant messaging and groupchat server that combines easy setup and administration with solid security and performance. Uses the open-source extensible messaging and presence protocol (XMPP) real-time collaboration (RTC) server.
MeshCentral is a multi-platform, self-hosted, feature-packed website for remote device management. You can use the public, community server for free or install on your own server. The server and management agent run on Windows, Linux, MacOS and FreeBSD.
HESK is a basic, lightweight help desk tool with an integrated knowledgebase that helps customers quickly resolve some common issues on their own. Includes scripted responses, ticket templates, custom data fields and statuses and much more. Tickets can be prioritized and organized, and they include request details, your ongoing discussion with the customer, which staff member is assigned, notes, files, status and time spent on resolution. Staff accounts can be created with restrictions on access and functionality, and you can track who is working on what.
openDCIM is designed for simple, complete data-center asset tracking. Offers support for multiple rooms; management of space, power and cooling; basic contact management and integration into existing business directory via UserID; fault tolerance; computation of center of gravity for each cabinet; template management for devices (with ability to override per device); optional tracking of cable connections within each cabinet and for each switch device; archival functions for equipment sent to salvage/disposal; integration with intelligent power strips and UPS devices.
Otter allows you to easily run complex PowerShell and Shell scripts that provision servers and manage their configuration. The custom GUI includes templates that make it easy for users to develop complex, multi-server orchestrations regardless of programming expertise. Includes dashboards and reports that show the state of your infrastructure, permissions and installation status. Free version has no server limit and includes all features but gives all users unrestricted access.
AdminDroid is a free-for-MVPs-only reporting option that is more user-friendly than what you’ll find in the Office 365 Admin portal. It serves as a single tool to manage your entire Office 365 infrastructure, with advanced reporting capabilities such as scheduling, export, customizable reports, advanced filters and more.
Course
Python for Network Engineers is a free, 8-week course that is being offered again STARTING TODAY (Jun 1). It covers Python fundamentals but “with a network engineer’s bent.” The weekly lessons cover, in order: Why Python, the Python Interpreter Shell, and Strings; Numbers, Files, Lists, and Linters; Conditionals and Loops; Dictionaries, Exceptions, and Regular Expressions; Functions and the Python Debugger; Netmiko Basics; Jinja2 Basics, Introduction to YAML and JSON, Complex Data Structures; Libraries, Package Installation, and Virtual Environments. Uses Python3.
Neils running giveaway for Cisco CCNA Training and Exam Complete Package, including payment for Cisco CCNA exam entry (value $300), Neil Anderson CCNA Gold Bootcamp course (value $99), AlphaPrep Complete 240 Day Package practice tests (value $450), and Network Lessons Annual Membership (value $290).
Training Resource
flAWS Challenge is a fun way to learn about security issues to watch for with AWS and devops. A series of levels teach about how to avoid common mistakes as well as AWS-specific “gotchas.” Hints are provided that teach you how to discover what you need to know. If you’re in a hurry, you can just use the hints to go from one level to the next instead of playing along.
Podcast
Clear To Send is a weekly podcast on wireless engineering that covers WiFi technology, design tips, troubleshooting and tools. Features informative interviews with wireless engineers, tech news on the topic, and product information. batwing20 thinks you’ll like it… “if you are into wireless.”
The History of Networking features fascinating discussions about the creation of all the technologies that make the modern Internet possible. It’s an opportunity to hear stories about world-changing technologies and the organizations involved from the very people who created them.
Heavy Networking is a weekly podcast from Packet Pushers that takes an “unabashedly nerdy” deep dive into data networking tech. Features hour-long interviews with industry experts and real-life network engineers from the tech community, standards bodies, academia, vendors and more.
The Hedge is a network engineering podcast that covers technology and other topics of relevance to a network engineer, from the smallest networks up to the entirety of the internet.
Cheatsheet
Regexp Cheatsheet is a helpful blog post on Basic Regular Expressions (BRE) and Extended Regular Expressions (ERE) syntax supported by GNU grep, sed, and awk. It covers the differences between these somewhat complex tools — for example, awk doesn’t support backreferences within the regexp definition (i.e., the search portion). Kindly shared by its author, ASIC_SP.
Vim Cheatsheet is a nicely organized, printable collection of key, useful Vim commands. A dark version is also available here.
{kind=link}