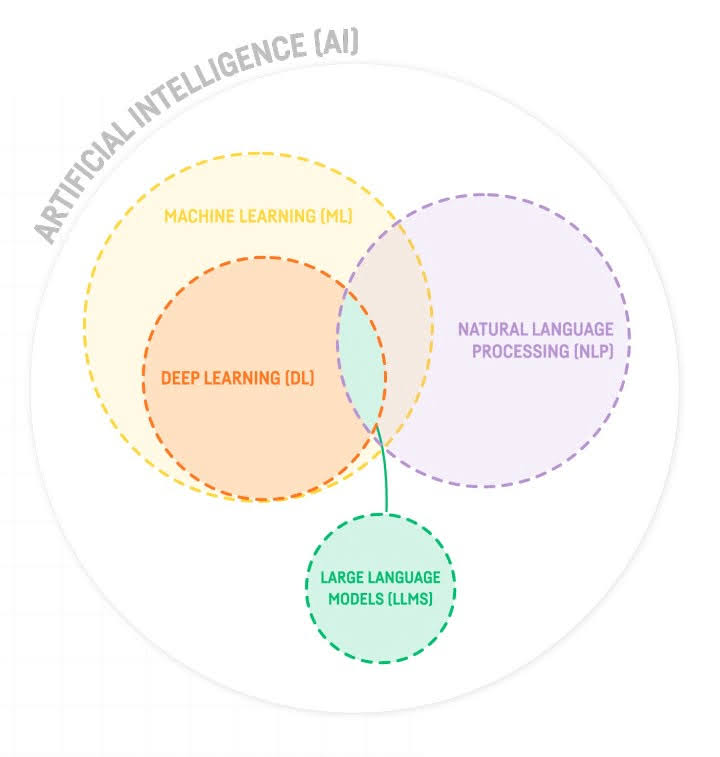
While OpenAI’s ChatGPT, Microsoft’s Bing, and Google’s Bard have received a lot of public attention in the past months, it is important to remember that they are specific products built on top of a class of technologies called Large Language Models (LLMs).
Check out this article to learn how to use LLMs like GPT-4 in an enterprise context — beyond the simple web interface provided by products like ChatGPT.

Table of Contents
- What Are ChatGPT, Bing, & Bard?
- What Is a Large Language Model (LLM)?
- What Makes a Large Language Model… Large?
- Tradeoffs Between LLMs & Other Methods
- Identifying a Use Case for LLMs
- Risk Tolerance
- Human Review
- Text (or Code) Intensive
- Business Value
- How to Use LLMs in the Enterprise
- Advantages of Using a Model-as-a-Service via API
- Limitations to Using a Model-as-a-Service via API
- Advantages of Self Managing an Open-Source Model
- Tradeoffs to Self Managing an Open-Source Model
- Choosing an Approach
- How to Use LLMs Responsibly
What Are ChatGPT, Bing, & Bard?
While OpenAI’s ChatGPT, Microsoft’s Bing, and Google’s Bard have received a lot of public attention in the past months, it is important to remember that they are specific products built on top of a class of technologies called Large Language Models (LLMs).
The most accessible way of using these products requires typing or pasting text into their respective input boxes and reading or copying their responses. Only some of these products offer programmatic interfaces, meaning they cannot be “plugged into” other enterprise data systems or processes. This enterprise-level use of this technology will be the focus of this document.
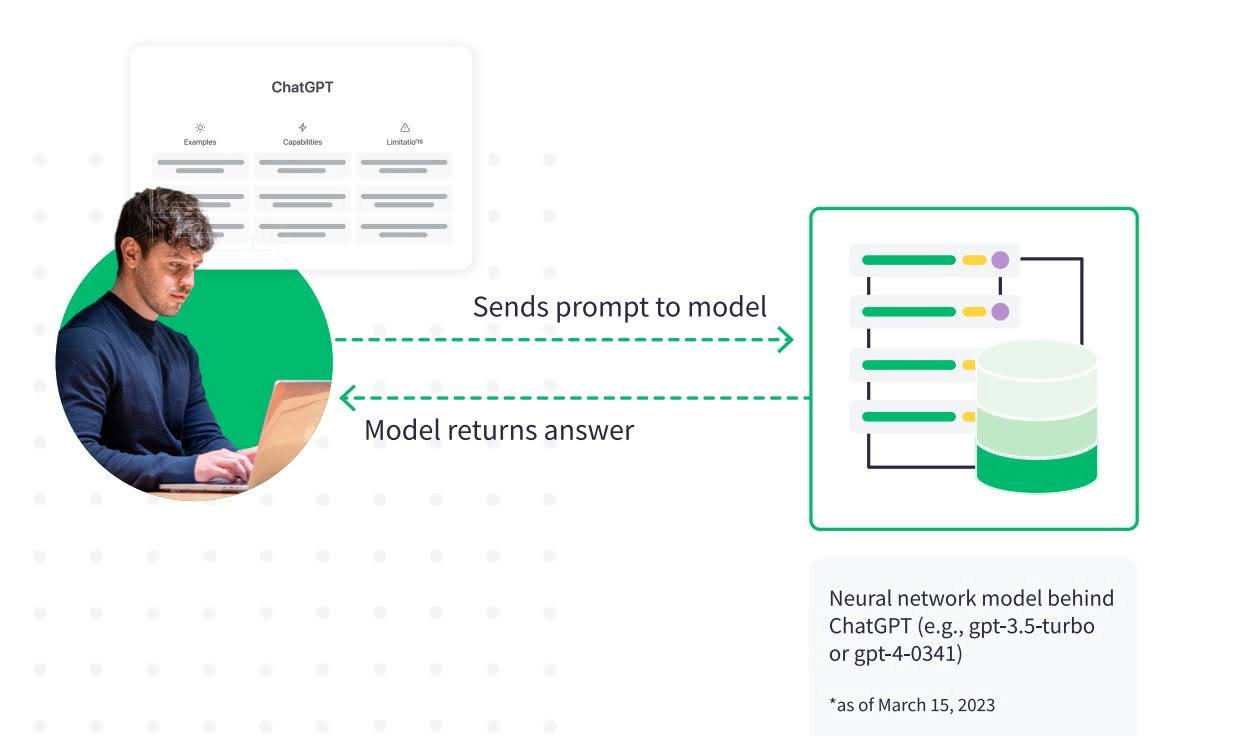
What Is a Large Language Model (LLM)?
An LLM is a neural network model architecture based on a specific component called a transformer. Transformer technologies were originally developed by Google in 2017 and have been the subject of intense research and development since then. LLMs work by reviewing enormous volumes of text, identifying the ways that words relate to one another, and building a model that allows them to reproduce similar text.
Importantly, when asked a question, they are not “looking up” a response. Rather, they are producing a string of words by predicting which word would best follow the previous, taking into account the broader context of the words before it. In essence, they are providing a “common sense” response to a question.
While the most powerful LLMs have shown their ability to produce largely accurate responses on an astonishingly wide range of tasks, the factual accuracy of those responses cannot be guaranteed.
What Makes a Large Language Model… Large?
A neural network is made up of a large number of “neurons,” which are simple mathematical formulas that pass the results of their calculations to one or more neurons in the system. The connections between these neurons are given “weights” that define the strength of the signal between the neurons. These weights are also sometimes called parameters.
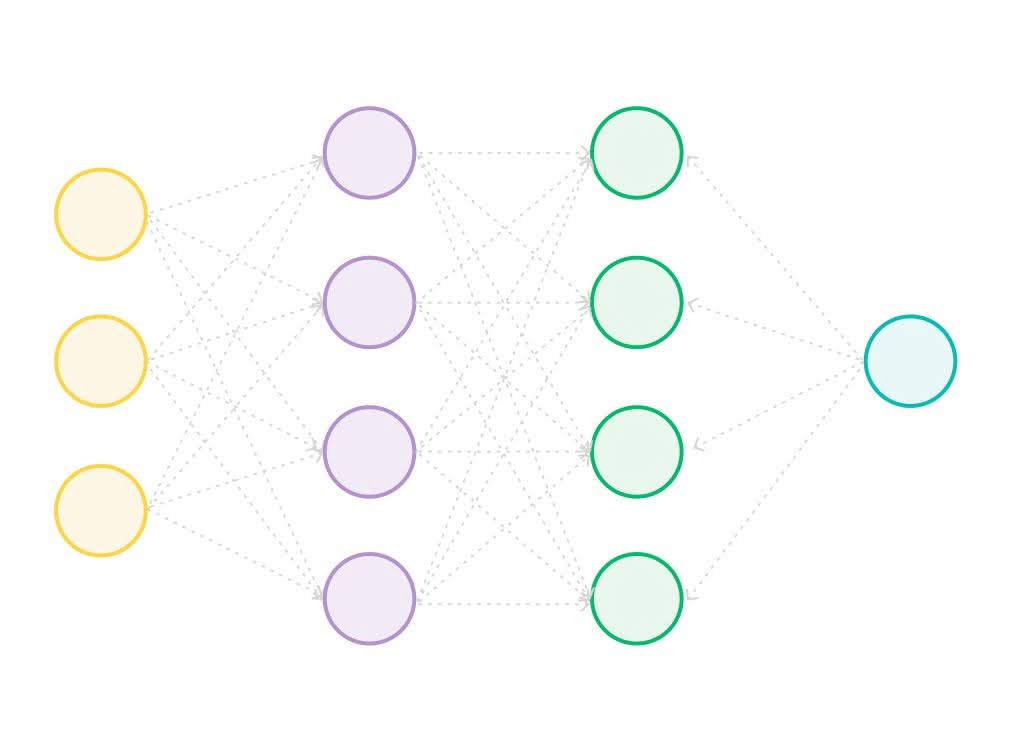
One of the models behind ChatGPT (gpt-3.5-turbo) has 175 billion parameters. GPT-4 has an unknown number of parameters.
The size of these models has important consequences for their performance, but also the cost and complexity of their use. On the one hand, larger models tend to produce more human-like text and are able to handle topics that they may not have been specifically prepared for. On the other hand, both building the model and using the model is extremely computationally intensive.
It is no accident that the largest and most highly performing models have come from giant technology companies or startups funded by such companies: The development of these models likely costs billions of dollars in cloud computing.
Tradeoffs Between LLMs & Other Methods
Using LLMs can be computationally intensive. In the case of a model with 175 billion weights, for each “token” (that’s a word or a piece of a word) that it outputs, it needs to run 175 billion calculations… each and every time. Why make such a large model then? Especially when a smaller language model is very good at the task for which it is designed?
The largest models are like a smartphone: They are convenient in that they pack a lot of functionality into a single product. This means that you can use the same model for a variety of tasks. It can translate, it can summarize, it can generate text based on a few inputs. Like a smartphone, it’s the one solution that you need to handle a vast array of tasks, though this flexibility comes at a price.
If all you need is a stopwatch, you can find a far less expensive option than a smartphone. Similarly, if you need a solution to a specific task, you may be better off selecting a small, task-specific model instead.
Identifying a Use Case for LLMs
If you’re interested in testing the usefulness of an LLM inside your organization, seek an application that balances the following:
Risk Tolerance
If this is the first time you’re using this technology, choose a domain where there is a certain tolerance for risk. The application should not be one that is critical to the organization’s operations and should, instead, seek to provide a convenience or efficiency gain to its teams.
Human Review
A law firm has been quoted as saying that they are comfortable using this technology to create a first draft of a contract, in the same way they would be comfortable delegating such a task to a junior associate. This is because any such document will go through many rounds of review thereafter, minimizing the risk that any error could slip through.
Text (or Code) Intensive
It’s important to lean on the strengths of these models and set them to work on text-intensive or code-intensive tasks — in particular those that are “unbounded,” such as generating sentences or paragraphs of text. This is in contrast to “bounded” tasks, such as sentiment analysis, where existing, purpose-built tools will provide excellent results at lower cost and complexity.
Business Value
As always, and perhaps especially when there is a lot of excitement around a new technology, it is important to come back to basics and ask whether the application is actually valuable to the business. LLMs can do many things, whether those things are valuable or not is a separate question.
How to Use LLMs in the Enterprise
Using an LLM in the enterprise, beyond the simple web interface provided by products like ChatGPT, can be done in one of two ways:
- Making an API call to a model provided as a service, such as the GPT-3 models provided by OpenAI, including the gpt-3.5-turbo or gpt-4-0314 models that powers ChatGPT. Generally, these services are provided by specialized companies like OpenAI, or large cloud computing companies like Amazon Web Services (AWS), Google Cloud Platform (GCP), and Microsoft Azure.
- Downloading and running an opensource model in an environment that you manage. Platforms like Hugging Face aggregate a wide range of such models
Each approach has advantages and drawbacks, which we’ll explore in the following sections. And remember, both options allow you to choose from smaller and larger models, with tradeoffs in terms of the breadth of their potential applications, the sophistication of the language generated, and the cost and complexity of using the model.
Advantages of Using a Model-as-a-Service via API
Some companies (such as OpenAI, AWS, and GCP) provide public APIs that can be called programmatically. This means setting up a small software program, or a script, that will connect to the API and send a properly formatted request.
The API will submit the request to the model, which will then provide the response back to the API, which will in turn send it back to the original requester.
There are several advantages to this approach:
- Low barrier to entry: Calling an API is a simple task that can be done by a junior developer in a matter of minutes.
- More sophisticated models: The models behind the API are often the largest and most sophisticated versions available. This means that they can provide more sophisticated and accurate responses on a wider range of topics than smaller, simpler models.
- Fast responses: Generally, these models can provide relatively quick responses (on the order of seconds) allowing for real-time use.

Limitations to Using a Model-as-a-Service via API
The use of public models via API, while convenient and powerful, has limitations that may make it inappropriate for certain enterprise applications:
- Data residency and privacy: By nature, public APIs require that the content of the query be sent to the servers of the API service. In some cases, the content of the query may be retained and used for further development of the model. Enterprises should be careful to check if this architecture respects their data residency and privacy obligations for a given use case.
- Potentially higher cost: Most of the public APIs are paid services, whereby the user is charged based on the number of queries and the quantity of text submitted. The companies providing these services usually provide tools to estimate the cost of their use. They also often provided smaller and cheaper models which may be appropriate for a narrower task.
- Dependency: The provider of an API can choose to stop the service at any time, though such a decision is typically rare for a popular (and moneymaking) service. Smaller companies providing such services may be at risk of insolvency. Enterprises should weigh the risk of building a dependency on such a service and ensure that they are comfortable with it.
Advantages of Self Managing an Open-Source Model
Given the drawbacks of using a public model via API, it may be appropriate for a company to set up and run an open-source model themselves. Such a model can be run on on-premises servers that an enterprise owns or in a cloud environment that the enterprise manages.
Advantages of this approach include:
- Wide range of choice: There are many open-source models available, each of which presents its own strengths and weaknesses. Companies can choose the model that best suits their needs. That said, doing so requires some familiarity with the technology and how to interpret those tradeoffs
- Potentially lower cost: In some cases, running a smaller model that is more limited in its application may allow for the desired performance for a specific use case at much lower cost than using a very large model provided as a service.
- Independence: By running and maintaining open-source models themselves, organizations are not dependent on a third-party API service.
Tradeoffs to Self Managing an Open-Source Model
While there are many advantages to using an open-source model, it may not be the appropriate choice for every organization or every use case for the following reasons:
- Complexity: Setting up and maintaining a LLM requires a certain degree of data science and engineering expertise — beyond that required for simpler machine learning models. Organizations should evaluate if they have sufficient expertise, and if those experts have the necessary time to set up and maintain the model in the long run
- Narrower performance: The very large models provided via public APIs are astonishing in the breadth of topics that they can cover. Models provided by the open-source community are generally smaller and more focused in their application, though this may change as ever-larger models are built by the open source community
Choosing an Approach
Given the tradeoffs between the different approaches, how can an organization choose the one that is right for them?
In fact, there is no single approach that will be appropriate enterprise wide. The best strategy for most organizations will be to equip themselves with the means to choose the best model and architecture for a given application or use case.
In certain cases, the balance may tip toward using the model-as-a-service APIs, in others, the use of an open-source model may be more appropriate. In some cases, a very large model may be required — in others, a smaller model may suffice.
The companies that are most successful in using LLMs will be those that equip themselves with the ability to choose and apply the right approach and the right model for a given application, especially given the rapid pace of innovation in this space.
How to Use LLMs Responsibly
Using LLMs responsibly requires similar steps and considerations as the use of other machine learning and AI technologies:
- Understand how the model is built. All machine learning and neural networks, including those used in LLMs, are influenced by the data that they are trained on. This can introduce biases that need to be corrected for.
- Understand how the model will impact the end user. LLMs in particular present the risk that an end user may believe that they are interacting with a human when, in fact, they are not. Dataiku recommends that organizations disclose to end users where and how these technologies are being used. Organizations should also provide guidance to end users on how to interact with any information derived from the model and provide caveats for the overall quality and factual accuracy of the information. With this information, the end user is well-equipped to decide for themselves how best to interpret the information.