Every single details that you need to know about ChatGPT
This article explain the fundamentals of ChatGPT and generative AI in a step-by-step fashion to assist with workings or leverage ChatGPT to its fullest potential.
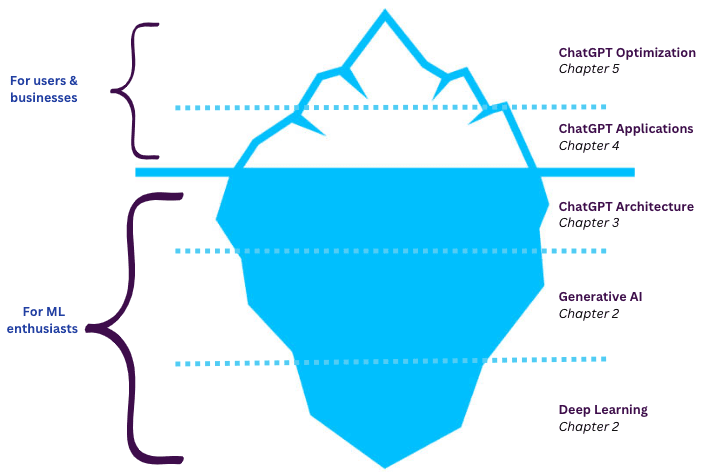
How to read this guide?
This guide has been developed with the purpose of providing knowledge to everyone interested in learning more about ChatGPT. If you are reading this guide, it is likely that you are either someone:
- Who is not familiar with Machine Learning (ML), yet has heard about ChatGPT and would like to comprehend how it works
- Who has some knowledge of ML, but isnʼt well versed with deep learning (or generative models) and would like to work with a roadmap to start learning about architecture details.
- Who is enthusiastic about the concept of ChatGPT and wishes to utilize it in their business applications or personal life, but is not eager to discover the specifics of its construction
If you fall into the first group, it is highly advised that you first become familiar with the fundamentals of Machine Learning, in which case the resources in this guide might not be adequate. If you are in the second or third group, look at the illustration above to position yourself and identify where you fit in and make a decision on which chapter to start from.
The chapters in this resource provide a brief overview of the topics, followed by a comprehensive list of courses, videos, articles, and blogs. For those who are short on time and only want a general understanding, it is suggested to read the articles and blogs. However, for a more in-depth knowledge, one of the courses from the list, suited to your learning style, should be taken before moving on to the next chapter. All of the listed resources are available for free.
Hope that this guide provides a clear path for learning about ChatGPT.
Deep Learning Basics
Neural Networks
Deep learning is the branch of machine learning where neural networks are used to analyze large datasets and make decisions based on the input. Some basic deep learning terminology you should know are:
Neural networks: A neural network is a computing system made up of interconnected layers of artificial neurons that are used to store and process information. Neural networks are used to identify patterns, make predictions, and classify data.
Backpropagation: Backpropagation is the process of training a neural network by adjusting the weights of the connections between neurons to minimize the overall error.
Activation functions: Activation functions are used to activate neurons in a neural network, and can be used to control the output of a neuron. Examples of activation functions include sigmoid, ReLU, and tanh.
Gradient descent: Gradient descent is an optimization algorithm used to train neural networks. It adjusts the weights of the neural network in order to minimize the error.
Convolutional Neural Networks: A convolutional neural network (CNN) is a type of neural network that is used to analyze and classify images. CNNs are typically made up of convolutional and pooling layers.
Recurrent Neural Networks: Recurrent neural networks (RNNs) are a type of neural network that can process sequential data. RNNs are used to analyze time-series data such as audio and text.
Generative Models
ChatGPT belongs to a class of deep learning models called generative models, so are all the recent open-sourced models like MidJourney, Stability AI, Dall-E etc. Some background in generative AI can help understand the fundamental design of these models.
Deep learning models (or machine learning models in general) can be divided into two types – generative and discriminative.
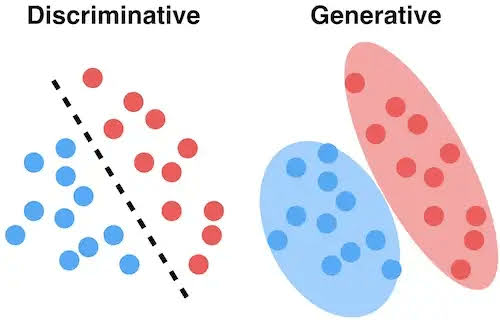
Generative models are a type of machine learning algorithms that are used to generate new content, such as images, text, audio, and video. They are used to teach computers to understand the underlying structure of data, and then generate new data based on this understanding. Generative models use a variety of techniques, from probabilistic models to neural networks, to create new data from existing data. Generative models can be used to create new art, write new stories, produce video game characters, and much more.
Discriminative models are supervised learning algorithms used for classification tasks. They produce a function that assigns a label to an input based on its features. Discriminative models learn the boundary between the classes of data, as opposed to generative models which learn the probability distribution of the data. Commonly used discriminative models include logistic regression, support vector machines (SVMs), and decision trees.
Transformers and Large Language Models
ChatGPT is a generative model, but what it essentially generates is text which is the basis or the script of a language. A language model is a probabilistic model that is used to predict the likelihood of the occurrence of a word given the preceding words in a sentence or phrase. It is used to estimate the probability of a new sentence that is generated by a computer program. Language models are used in natural language processing (NLP) to estimate the likelihood of a sentence or phrase being spoken or written by a human being. They are also used to generate text and speech in computer-generated applications such as machine translation and text-to-speech applications.

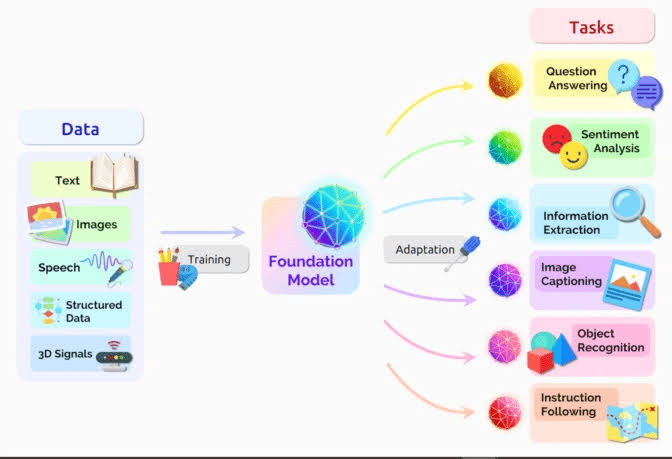
Language models are generally trained using the self-supervised learning paradigm. Self-supervised learning is a type of machine learning which allows models to teach themselves by using part of the input data to learn the other part. It’s also sometimes referred to as predictive or pretext learning. One architecture for building large language models is the transformer architecture. Large language models such as Google’s BERT, OpenAI’s GPT-3 (ChatGPTʼs base model), and MicrosoȦ’s XLNet are all based on Transformers. (Transformers or foundational models in the below diagram) are a type of neural network architecture that allow information to be passed between different components of the network, allowing for a better understanding of language and the ability to generate more sophisticated and accurate results.
ChatGPT: Introduction and Architecture
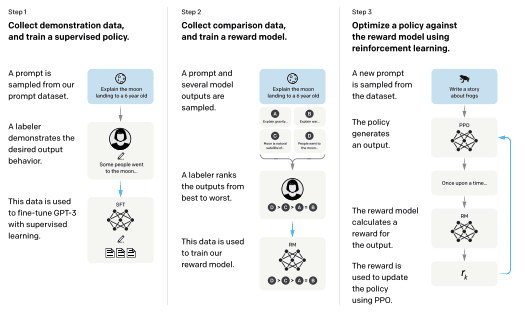
ChatGPT is the latest groundbreaking language model from OpenAI that is designed to excel in interactive conversations and generate text with greater precision, detail, and coherence. The creators have used a mix of Supervised Learning and Reinforcement Learning, particularly RLHF (Reinforcement Learning from Human Feedback), to fine-tune the model and ensure that it produces accurate and unbiased results. This technology represents the next generation in OpenAI’s line of Large Language Models and promises to revolutionize the way we interact and communicate with AI.
OpenAI states that ChatGPT was trained using similar methods as InstructGPT, but with slight variations in the data collection process. As of now, specific and detailed information about ChatGPT has not been released to the public. The below diagram explains the architecture used in InstructGPT:
ChatGPT: Applications
OpenAI’s ChatGPT model has a wide range of potential applications, which fall under the below categories:
Conversational AI: ChatGPT can be used to build conversational AI systems, such as chatbots, that can respond to user queries in a natural and human-like manner.
Text Generation: ChatGPT can be used to generate new text based on a prompt, such as generating news articles, creative writing, or generating responses in a chatbot.
Question Answering: ChatGPT can be fine-tuned for question-answering tasks, where it can answer questions based on the provided context.
Text Summarization: ChatGPT can be used to automatically summarize long documents or articles into a shorter, more concise form.
Text Classification: ChatGPT can be used for text classification tasks, such as sentiment analysis or spam detection.
Dialogue Management: ChatGPT can be used in dialogue systems to generate appropriate responses in a conversation.
Since its creation, people have been exploring the potential of ChatGPT and creating browser extensions and application prototypes to extend its capabilities.
ChatGPT Optimization for Personal & Business Use Cases
Optimizing ChatGPT’s performance can be improved by understanding how it was trained and constructed. This is beneficial for both personal and business applications, however, there are additional constraints in business use cases. Two key ways to optimize ChatGPT are through:
- Prompt engineering to provide optimal generation directions
- Getting a deeper understanding of compliance, privacy and ethical concerns while using large language models like ChatGPT
Both of these methods are discussed in further detail with accompanying resources for deeper understanding.
Prompt Engineering
Prompt engineering for ChatGPT involves carefully craȦing the input prompts used to initiate the conversation with the model. This includes selecting the right words, phrasing, and context to guide the model in generating a specific response. By carefully designing the input prompts, it is possible to steer the model towards a particular type of response and improve the overall quality of its output.
The goal of prompt engineering is to get the best response from the model by providing it with the right context and information.
By using prompt engineering, one can improve the overall quality of the model’s output and make it more useful and effective for specific use cases.
Compliance, Privacy and Ethics
There are several concerns when using GPT-based models like ChatGPT especially in customer facing production and business use cases, including:
Bias: Language models like ChatGPT have been shown to have biases that are inherent in the data they were trained on.
Misinformation: ChatGPT was trained on a diverse range of internet text, which includes inaccuracies and falsehoods, so there is a risk of spreading misinformation through its outputs.
Privacy and Security: If the input data to ChatGPT contains sensitive information, there is a risk of privacy and security breaches.
Lack of Context Awareness: ChatGPT does not have a complete understanding of context and can generate outputs that are inconsistent or irrelevant in a given context.
Cost: Generating responses from a language model like ChatGPT can be computationally expensive, which can make it cost-prohibitive for some production use cases.
Quality Control: ChatGPT outputs may need to be reviewed and filtered for content that is inappropriate, malicious, or offensive.
Adversarial examples: GPT models can be vulnerable to adversarial examples, which are intentionally constructed inputs designed to trick the model into making incorrect predictions.
Explainability and transparency: GPT models are oȦen viewed as black boxes, making it difficult to understand how they arrive at their predictions and to debug and improve them.
Performance: GPT models can be resource-intensive to run in real-time, requiring large amounts of computational resources, memory, and power.