The latest AWS Certified Solutions Architect – Associate SAA-C03 certification actual real practice exam question and answer (Q&A) dumps are available free, which are helpful for you to pass the AWS Certified Solutions Architect – Associate SAA-C03 exam and earn AWS Certified Solutions Architect – Associate SAA-C03 certification.
Table of Contents
- Question 861
- Exam Question
- Correct Answer
- Explanation
- Reference
- Question 862
- Exam Question
- Correct Answer
- Explanation
- Question 863
- Exam Question
- Correct Answer
- Explanation
- Reference
- Question 864
- Exam Question
- Correct Answer
- Explanation
- Question 865
- Exam Question
- Correct Answer
- Explanation
- Reference
- Question 866
- Exam Question
- Correct Answer
- Explanation
- Reference
- Question 867
- Exam Question
- Correct Answer
- Explanation
- Reference
- Question 868
- Exam Question
- Correct Answer
- Explanation
- Question 869
- Exam Question
- Correct Answer
- Explanation
- Reference
- Question 870
- Exam Question
- Correct Answer
- Explanation
- Reference
Question 861
Exam Question
A trucking company is deploying an application that will track the GPS coordinates of all the company’s trucks. The company needs a solution that will generate real-time statistics based on metadata lookups with high read throughput and microsecond latency. The database must be fault tolerant and must minimize operational overhead and development effort.
Which combination of steps should a solutions architect take to meet these requirements? (Choose two.)
A. Use Amazon DynamoDB as the database.
B. Use Amazon Aurora MySQL as the database.
C. Use Amazon RDS for MySQL as the database
D. Use Amazon ElastiCache as the caching layer.
E. Use Amazon DynamoDB Accelerator (DAX) as the caching layer.
Correct Answer
A. Use Amazon DynamoDB as the database.
E. Use Amazon DynamoDB Accelerator (DAX) as the caching layer.
Explanation
To meet the requirements of generating real-time statistics based on metadata lookups with high read throughput and microsecond latency, while ensuring fault tolerance and minimizing operational overhead and development effort, the following steps should be taken:
A. Use Amazon DynamoDB as the database: Amazon DynamoDB is a fully managed NoSQL database service that offers fast and predictable performance with low latency. It can handle high read throughput and provides microsecond response times. DynamoDB is designed for fault tolerance and automatically replicates data across multiple availability zones to ensure high availability.
E. Use Amazon DynamoDB Accelerator (DAX) as the caching layer: Amazon DynamoDB Accelerator (DAX) is a fully managed, in-memory caching service for DynamoDB. By using DAX, you can improve the response times of DynamoDB queries by caching frequently accessed data in memory, reducing the need to read from the database. DAX is seamlessly integrated with DynamoDB and provides microsecond latency for read-intensive workloads.
By combining Amazon DynamoDB as the database and using Amazon DynamoDB Accelerator (DAX) as the caching layer, the trucking company can achieve high read throughput, microsecond latency, fault tolerance, and minimize operational overhead and development effort. DynamoDB handles the storage and retrieval of GPS coordinates, while DAX enhances performance by caching frequently accessed metadata for faster lookups.
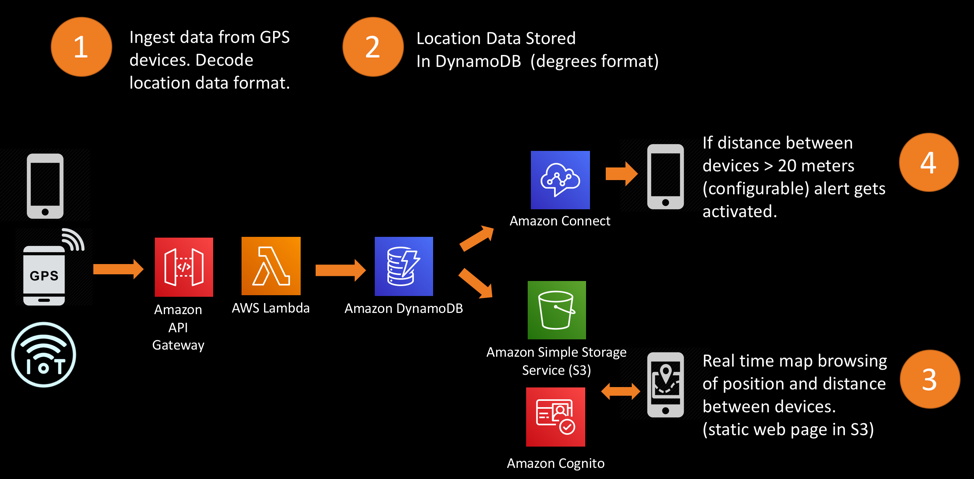
Reference
- AWS Public Sector Blog > Creating a serverless GPS monitoring and alerting solution
- Products > Database > Amazon Aurora > Amazon Aurora Customers
Question 862
Exam Question
A company’s security team requests that network traffic be captured in VPC Flow Logs. The logs will be frequently accessed for 90 days and then accessed intermittently.
What should a solutions architect do to meet these requirements when configuring the logs?
A. Use Amazon CloudWatch as the target. Set the CloudWatch log group with an expiration of 90 days.
B. Use Amazon Kinesis as the target. Configure the Kinesis stream to always retain the logs for 90 days.
C. Use AWS CloudTrail as the target. Configure CloudTrail to save to an Amazon S3 bucket, and enable S3 Intelligent-Tiering.
D. Use Amazon S3 as the target. Enable an S3 Lifecycle policy to transition the logs to S3 Standard-Infrequent Access (S3 Standard-IA) after 90 days.
Correct Answer
D. Use Amazon S3 as the target. Enable an S3 Lifecycle policy to transition the logs to S3 Standard-Infrequent Access (S3 Standard-IA) after 90 days.
Explanation
To meet the requirements of capturing network traffic in VPC Flow Logs and accessing the logs frequently for 90 days, then intermittently, the following approach should be taken:
D. Use Amazon S3 as the target. Enable an S3 Lifecycle policy to transition the logs to S3 Standard-Infrequent Access (S3 Standard-IA) after 90 days.
By using Amazon S3 as the target for VPC Flow Logs, you can configure an S3 Lifecycle policy to automatically transition the logs to S3 Standard-IA storage class after 90 days. This allows you to optimize costs by moving the logs to a lower-cost storage class while still retaining accessibility.
Option A is incorrect because using Amazon CloudWatch as the target with an expiration of 90 days would result in the logs being deleted after that period, which does not fulfill the requirement of accessing the logs intermittently.
Option B is incorrect because using Amazon Kinesis as the target and configuring the Kinesis stream to always retain the logs for 90 days does not consider the requirement of intermittent access to the logs after the initial 90-day period.
Option C is incorrect because using AWS CloudTrail as the target and enabling S3 Intelligent-Tiering does not address the capturing of network traffic in VPC Flow Logs. CloudTrail is used for auditing API calls and does not capture network flow information.
Therefore, option D is the most appropriate solution as it allows the company to capture network traffic in VPC Flow Logs, retain the logs in S3, and transition them to a lower-cost storage class (S3 Standard-IA) after 90 days to optimize costs while still allowing intermittent access to the logs.
Question 863
Exam Question
A company has an application that collects data from loT sensors on automobiles. The data is streamed and stored in Amazon S3 through Amazon Kinesis Data Firehose. The data produces trillions of S3 objects each year. Each morning, the company uses the data from the previous 30 days to retrain a suite of machine learning (ML) models. Four times each year, the company uses the data from the previous 12 months to perform analysis and train other ML models. The data must be available with minimal delay for up to 1 year. After 1 year, the data must be retained for archival purposes.
Which storage solution meets these requirements MOST cost-effectively?
A. Use the S3 Intelligent-Tiering storage class. Create an S3 Lifecycle policy to transition objects to S3 Glacier Deep Archive after 1 year.
B. Use the S3 Intelligent-Tiering storage class. Configure S3 Intelligent-Tiering to automatically move objects to S3 Glacier Deep Archive after 1 year.
C. Use the S3 Standard-Infrequent Access (S3 Standard-IA) storage class. Create an S3 Lifecycle policy to transition objects to S3 Glacier Deep Archive after 1 year.
D. Use the S3 Standard storage class. Create an S3 Lifecycle policy to transition objects to S3 Standard-Infrequent Access (S3 Standard-IA) after 30 days, and then to S3 Glacier Deep Archive after 1 year.
Correct Answer
B. Use the S3 Intelligent-Tiering storage class. Configure S3 Intelligent-Tiering to automatically move objects to S3 Glacier Deep Archive after 1 year.
Explanation
The storage solution that meets the requirements most cost-effectively is:
B. Use the S3 Intelligent-Tiering storage class. Configure S3 Intelligent-Tiering to automatically move objects to S3 Glacier Deep Archive after 1 year.
With the S3 Intelligent-Tiering storage class, objects are automatically moved between two access tiers: frequent access and infrequent access, based on their access patterns. This allows you to optimize costs by storing data in the most cost-effective tier based on its usage. By configuring S3 Intelligent-Tiering to transition objects to S3 Glacier Deep Archive after 1 year, you ensure long-term archival storage while taking advantage of the cost efficiency of the storage class.
Option A is incorrect because using S3 Intelligent-Tiering with an S3 Lifecycle policy to transition objects to S3 Glacier Deep Archive after 1 year would not provide the benefits of automatic tiering based on access patterns.
Option C is incorrect because using the S3 Standard-Infrequent Access (S3 Standard-IA) storage class with an S3 Lifecycle policy to transition objects to S3 Glacier Deep Archive after 1 year would not provide the cost optimization benefits of S3 Intelligent-Tiering.
Option D is incorrect because using the S3 Standard storage class with an S3 Lifecycle policy to transition objects to S3 Standard-Infrequent Access (S3 Standard-IA) after 30 days, and then to S3 Glacier Deep Archive after 1 year, would not take advantage of the automatic tiering capability of S3 Intelligent-Tiering.
Therefore, option B is the most suitable and cost-effective solution for this scenario.

Reference
AWS News Blog > S3 Intelligent-Tiering Adds Archive Access Tiers
Question 864
Exam Question
A company is designing a new application that runs in a VPC on Amazon EC2 instances. The application stores data in Amazon S3 and uses Amazon DynamoDB as its database. For compliance reasons, the company prohibits all traffic between the EC2 instances and other AWS services from passing over the public internet.
What can a solutions architect do to meet this requirement?
A. Configure gateway VPC endpoints to Amazon S3 and DynamoDB.
B. Configure interface VPC endpoints to Amazon S3 and DynamoDB.
C. Configure a gateway VPC endpoint to Amazon S3. Configure an interface VPC endpoint to DynamoDB.
D. Configure a gateway VPC endpoint to DynamoDB. Configure an interface VPC endpoint to Amazon S3.
Correct Answer
B. Configure interface VPC endpoints to Amazon S3 and DynamoDB.
Explanation
To meet the requirement of prohibiting all traffic between the EC2 instances and other AWS services from passing over the public internet, a solutions architect can take the following step:
B. Configure interface VPC endpoints to Amazon S3 and DynamoDB.
Interface VPC endpoints are used to privately access AWS services using private IP addresses within the VPC. By configuring interface VPC endpoints to both Amazon S3 and DynamoDB, the EC2 instances can securely access these services without the need for internet access.
Option A is incorrect because it suggests using gateway VPC endpoints to Amazon S3 and DynamoDB. Gateway VPC endpoints are used for traffic between a VPC and AWS services over AWS’s private network, but they are only available for Amazon S3, not DynamoDB.
Option C is incorrect because it suggests using a mix of gateway and interface VPC endpoints. Since the compliance requirement is to prohibit all traffic between the EC2 instances and other AWS services from passing over the public internet, it is recommended to use interface VPC endpoints for both Amazon S3 and DynamoDB.
Option D is incorrect because it suggests using a gateway VPC endpoint to DynamoDB. Gateway VPC endpoints are not available for DynamoDB, so it wouldn’t meet the requirement.
Therefore, option B is the correct choice as it allows the EC2 instances to securely access Amazon S3 and DynamoDB without internet connectivity.
Question 865
Exam Question
A company is running a photo hosting service in the us-east-1 Region. The service enables users across multiple countries to upload and view photos. Some photos are heavily viewed for months, and others are viewed for less than a week. The application allows uploads of up to 20 MB for each photo. The service uses the photo metadata to determine which photos to display to each user.
Which solution provides the appropriate user access MOST cost-effectively?
A. Store the photos in Amazon DynamoDB. Turn on DynamoDB Accelerator (DAX) to cache frequently viewed items.
B. Store the photos in the Amazon S3 Intelligent-Tiering storage class. Store the photo metadata and its S3 location in DynamoDB.
C. Store the photos in the Amazon S3 Standard storage class. Set up an S3 Lifecycle policy to move photos older than 30 days to the S3 Standard-Infrequent Access (S3 Standard-IA) storage class. Use the object tags to keep track of metadata.
D. Store the photos in the Amazon S3 Glacier storage class. Set up an S3 Lifecycle policy to move photos older than 30 days to the S3 Glacier Deep Archive storage class. Store the photo metadata and its S3 location in Amazon Elasticsearch Service (Amazon ES).
Correct Answer
B. Store the photos in the Amazon S3 Intelligent-Tiering storage class. Store the photo metadata and its S3 location in DynamoDB.
Explanation
To provide the appropriate user access most cost-effectively for the photo hosting service, the following solution can be implemented:
B. Store the photos in the Amazon S3 Intelligent-Tiering storage class. Store the photo metadata and its S3 location in DynamoDB.
By storing the photos in the Amazon S3 Intelligent-Tiering storage class, the service benefits from automatic cost optimization based on usage patterns. The S3 Intelligent-Tiering storage class automatically moves objects between two access tiers: frequent access and infrequent access. Since some photos are heavily viewed for months while others are viewed for less than a week, this tiering strategy helps optimize costs.
The photo metadata and its corresponding S3 location can be stored in DynamoDB, which provides low-latency, scalable, and managed NoSQL database capabilities. DynamoDB allows efficient querying and retrieval of metadata based on user requirements, enabling the service to determine which photos to display to each user.
Option A is not the most cost-effective solution as it suggests storing the photos in Amazon DynamoDB itself, which is primarily designed for key-value storage and can be more expensive compared to using a scalable and cost-effective storage service like Amazon S3 for storing the actual photo objects.
Option C is not the most cost-effective solution either. While it suggests using the S3 Standard-IA storage class and setting up an S3 Lifecycle policy to move photos older than 30 days, it does not provide the same automatic cost optimization based on usage patterns as the S3 Intelligent-Tiering storage class.
Option D is not the most cost-effective solution either. Storing the photos in the Amazon S3 Glacier storage class and using Amazon S3 Glacier Deep Archive for long-term archival can result in lower storage costs but higher retrieval costs. Additionally, using Amazon Elasticsearch Service (Amazon ES) for storing the photo metadata adds unnecessary complexity and cost, considering that DynamoDB can efficiently handle the metadata storage and retrieval requirements.
Therefore, option B is the most appropriate and cost-effective solution for this scenario, combining the benefits of Amazon S3 Intelligent-Tiering for photo storage and DynamoDB for metadata storage.
These storage classes differ as follows:
- S3 Glacier Instant Retrieval – Use for archiving data that is rarely accessed and requires milliseconds retrieval. Data stored in the S3 Glacier Instant Retrieval storage class offers a cost savings compared to the S3 Standard-IA storage class, with the same latency and throughput performance as the S3 Standard-IA storage class. S3 Glacier Instant Retrieval has higher data access costs than S3 Standard-IA. For pricing information, see Amazon S3 pricing.
- S3 Glacier Flexible Retrieval – Use for archives where portions of the data might need to be retrieved in minutes. Data stored in the S3 Glacier Flexible Retrieval storage class has a minimum storage duration period of 90 days and can be accessed in as little as 1-5 minutes by using an expedited retrieval. The retrieval time is flexible, and you can request free bulk retrievals in up to 5-12 hours. If you delete, overwrite, or transition the object to a different storage class before the 90-day minimum, you are charged for 90 days. Amazon S3 supports restore requests at a rate of up to 1,000 transactions per second, per AWS account for S3 Glacier Flexible Retrieval. For pricing information, see Amazon S3 pricing.
- S3 Glacier Deep Archive – Use for archiving data that rarely needs to be accessed. Data stored in the S3 Glacier Deep Archive storage class has a minimum storage duration period of 180 days and a default retrieval time of 12 hours. If you delete, overwrite, or transition the object to a different storage class before the 180-day minimum, you are charged for 180 days. Amazon S3 supports restore requests at a rate of up to 1,000 transactions per second, per AWS account for S3 Glacier Deep Archive. For pricing information, see Amazon S3 pricing. S3 Glacier Deep Archive is the lowest-cost storage option in AWS. Storage costs for S3 Glacier Deep Archive are less expensive than using the S3 Glacier Flexible Retrieval storage class. You can reduce S3 Glacier Deep Archive retrieval costs by using bulk retrieval, which returns data within 48 hours.
Reference
AWS > Documentation > Amazon Simple Storage Service (S3) > User Guide > Using Amazon S3 storage classes
Question 866
Exam Question
A company wants to run its critical applications in containers to meet requirements for scalability and availability. The company prefers to focus on maintenance of the critical applications. The company does not want to be responsible for provisioning and managing the underlying infrastructure that runs the containerized workload.
What should a solutions architect do to meet these requirements?
A. Use Amazon EC2 instances, and install Docker on the instances.
B. Use Amazon Elastic Container Service (Amazon ECS) on Amazon EC2 worker nodes.
C. Use Amazon Elastic Container Service (Amazon ECS) on AWS Fargate.
D. Use Amazon EC2 instances from an Amazon Elastic Container Service (Amazon ECS)-optimized Amazon Machine Image (AMI).
Correct Answer
C. Use Amazon Elastic Container Service (Amazon ECS) on AWS Fargate.
Explanation
To meet the requirements of running critical applications in containers while minimizing the responsibility for provisioning and managing the underlying infrastructure, the following solution can be implemented:
C. Use Amazon Elastic Container Service (Amazon ECS) on AWS Fargate.
By using Amazon ECS on AWS Fargate, the company can focus solely on the maintenance of the critical applications without the need to manage the underlying infrastructure. AWS Fargate is a serverless compute engine for containers that allows running containers without the need to provision or manage EC2 instances. It abstracts away the underlying infrastructure, automatically scaling and managing the compute resources required for running containers. This allows the company to focus on their applications and not worry about infrastructure provisioning, patching, and scaling.
Option A suggests using Amazon EC2 instances and manually installing Docker. While this approach provides more control over the infrastructure, it also requires the company to manage and maintain the EC2 instances, including operating system updates, security patches, and scaling, which goes against the requirement of minimizing infrastructure management.
Option B suggests using Amazon ECS on Amazon EC2 worker nodes. While Amazon ECS provides container management capabilities, using EC2 worker nodes still requires managing and maintaining the EC2 instances themselves, which adds operational overhead and goes against the requirement of minimizing infrastructure management.
Option D suggests using Amazon EC2 instances from an Amazon ECS-optimized AMI. While this provides a more streamlined setup for running Amazon ECS, it still requires managing and maintaining the EC2 instances, including scaling and patching.
Therefore, option C, using Amazon ECS on AWS Fargate, is the most appropriate solution as it allows the company to focus on the critical applications while AWS manages the underlying infrastructure for running containers.
Reference
Question 867
Exam Question
A company serves its website by using an Auto Scaling group of Amazon EC2 instances in a single AWS Region. The website does not require a database. The company is expanding, and the company’s engineering team deploys the website to a second Region. The company wants to distribute traffic across both Regions to accommodate growth and for disaster recovery purposes. The solution should not serve traffic from a Region in which the website is unhealthy.
Which policy or resource should the company use to meet these requirements?
A. An Amazon Route 53 simple routing policy
B. An Amazon Route 53 multivalue answer routing policy
C. An Application Load Balancer in one Region with a target group that specifies the EC2 instance IDs from both Regions
D. An Application Load Balancer in one Region with a target group that specifies the IP addresses of the EC2 instances from both Regions
Correct Answer
A. An Amazon Route 53 simple routing policy
Explanation
To distribute traffic across multiple AWS Regions for a website, while ensuring that unhealthy Regions are not used, the following policy or resource can be used:
A. An Amazon Route 53 simple routing policy
By using an Amazon Route 53 simple routing policy, the company can configure DNS routing to distribute traffic across multiple AWS Regions. Route 53 can monitor the health of the website in each Region and only route traffic to healthy Regions. If a Region becomes unhealthy, Route 53 automatically stops routing traffic to that Region. This provides both load balancing and disaster recovery capabilities.
Option B, an Amazon Route 53 multivalue answer routing policy, allows multiple healthy records to be returned in response to DNS queries, but it does not perform health checks on the Regions. It does not ensure that traffic is only served from healthy Regions.
Option C suggests using an Application Load Balancer (ALB) in one Region with a target group that specifies the EC2 instance IDs from both Regions. While ALB can distribute traffic across EC2 instances, it does not handle traffic routing across Regions.
Option D suggests using an ALB in one Region with a target group that specifies the IP addresses of the EC2 instances from both Regions. Similar to option C, ALB alone cannot handle traffic routing across Regions.
Therefore, option A, an Amazon Route 53 simple routing policy, is the most appropriate policy to distribute traffic across multiple Regions while ensuring that only healthy Regions are used.
Reference
What is the difference between a multivalue answer routing policy and a simple routing policy?
Question 868
Exam Question
A company is using a centralized AWS account to store log data in various Amazon S3 buckets. A solutions architect needs to ensure that the data is encrypted at rest before the data is uploaded to the S3 buckets. The data also must be encrypted in transit.
Which solution meets these requirements?
A. Use client-side encryption to encrypt the data that is being uploaded to the S3 buckets.
B. Use server-side encryption to encrypt the data that is being uploaded to the S3 buckets.
C. Create bucket policies that require the use of server-side encryption with S3 managed encryption keys (SSE-S3) for S3 uploads.
D. Enable the security option to encrypt the S3 buckets through the use of a default AWS Key Management Service (AWS KMS) key.
Correct Answer
B. Use server-side encryption to encrypt the data that is being uploaded to the S3 buckets.
Explanation
To meet the requirement of encrypting data at rest before uploading to the Amazon S3 buckets and encrypting data in transit, the most appropriate solution is:
B. Use server-side encryption to encrypt the data that is being uploaded to the S3 buckets.
With server-side encryption, the data is encrypted by AWS S3 service itself when it is uploaded to the S3 buckets. There are different options for server-side encryption in S3, including:
- Server-Side Encryption with Amazon S3 Managed Keys (SSE-S3): AWS S3 handles the encryption using its own keys.
- Server-Side Encryption with AWS Key Management Service (SSE-KMS): AWS S3 uses AWS KMS to manage the encryption keys.
- Server-Side Encryption with Customer-Provided Keys (SSE-C): You provide your own encryption keys, and AWS S3 uses them to encrypt the data.
By enabling server-side encryption, the data will be encrypted at rest in the S3 buckets.
To ensure data is encrypted in transit, it is recommended to use SSL/TLS for secure communication between clients and S3. This ensures that data is encrypted while being transferred over the network.
Option A, client-side encryption, involves encrypting the data on the client-side before uploading to S3. While this approach provides an additional layer of encryption, it requires managing the encryption process on the client side and can introduce complexity.
Option C, creating bucket policies to require server-side encryption with SSE-S3, helps enforce encryption for S3 uploads but does not cover the requirement of encrypting data in transit.
Option D, enabling the security option to encrypt the S3 buckets through the use of a default AWS Key Management Service (AWS KMS) key, only addresses the encryption at rest requirement and does not cover encryption in transit.
Therefore, option B is the correct choice as it covers both requirements of encrypting data at rest and in transit.
Question 869
Exam Question
A company observes an increase in Amazon EC2 costs in its most recent bill. The billing team notices unwanted vertical scaling of instance types for a couple of EC2 instances. A solutions architect needs to create a graph comparing the last 2 months of EC2 costs and perform an in-depth analysis to identify the root cause of the vertical scaling.
How should the solutions architect generate the information with the LEAST operational overhead?
A. Use AWS Budgets to create a budget report and compare EC2 costs based on instance types.
B. Use Cost Explorer’s granular filtering feature to perform an in-depth analysis of EC2 costs based on instance types.
C. Use graphs from the AWS Billing and Cost Management dashboard to compare EC2 costs based on instance types for the last 2 months.
D. Use AWS Cost and Usage Reports to create a report and send it to an Amazon S3 bucket. Use Amazon QuickSight with Amazon S3 as a source to generate an interactive graph based on instance types.
Correct Answer
B. Use Cost Explorer’s granular filtering feature to perform an in-depth analysis of EC2 costs based on instance types.
Explanation
To generate the information with the least operational overhead and perform an in-depth analysis of EC2 costs based on instance types, the most appropriate solution is:
B. Use Cost Explorer’s granular filtering feature to perform an in-depth analysis of EC2 costs based on instance types.
AWS Cost Explorer is a comprehensive cost management tool that provides various features for analyzing and visualizing cost and usage data. It offers granular filtering capabilities that allow you to drill down into specific cost dimensions, such as instance types in this case.
By using Cost Explorer, you can apply filters to focus on EC2 costs and segment them based on instance types. This allows you to compare the EC2 costs of different instance types over the last 2 months and identify any anomalies or patterns related to vertical scaling.
Option A, using AWS Budgets to create a budget report, provides high-level cost information but does not offer granular filtering or detailed analysis based on instance types.
Option C, using graphs from the AWS Billing and Cost Management dashboard, provides basic cost information but may not offer the level of detail required for an in-depth analysis based on instance types.
Option D, using AWS Cost and Usage Reports with Amazon QuickSight, offers flexibility in generating customized reports and graphs, but it introduces additional setup and configuration overhead compared to the other options.
Therefore, option B is the most suitable choice as it allows for efficient and focused analysis of EC2 costs based on instance types, minimizing operational overhead.
Reference
AWS Billing User Guide Version 2.0
Question 870
Exam Question
A company’s database is hosted on an Amazon Aurora MySQL DB cluster in the us-east-1 Region. The database is 4 TB in size. The company needs to expand its disaster recovery strategy to the us-west-2 Region. The company must have the ability to fail over to us-west-2 with a recovery time objective (RTO) of 15 minutes.
What should a solutions architect recommend to meet these requirements?
A. Create a Multi-Region Aurora MySQL DB cluster in us-east-1 and use-west-2. Use an Amazon Route 53 health check to monitor us-east-1 and fail over to us- west-2 upon failure.
B. Take a snapshot of the DB cluster in us-east-1. Configure an Amazon EventBridge (Amazon CloudWatch Events) rule that invokes an AWS Lambda function upon receipt of resource events. Configure the Lambda function to copy the snapshot to us-west-2 and restore the snapshot in us-west-2 when failure is detected.
C. Create an AWS CloudFormation script to create another Aurora MySQL DB cluster in us-west-2 in case of failure. Configure an Amazon EventBridge (Amazon CloudWatch Events) rule that invokes an AWS Lambda function upon receipt of resource events. Configure the Lambda function to deploy the AWS CloudFormation stack in us-west-2 when failure is detected.
D. Recreate the database as an Aurora global database with the primary DB cluster in us-east-1 and a secondary DB cluster in us-west-2. Configure an Amazon EventBridge (Amazon CloudWatch Events) rule that invokes an AWS Lambda function upon receipt of resource events. Configure the Lambda function to promote the DB cluster in us-west-2 when failure is detected.
Correct Answer
D. Recreate the database as an Aurora global database with the primary DB cluster in us-east-1 and a secondary DB cluster in us-west-2. Configure an Amazon EventBridge (Amazon CloudWatch Events) rule that invokes an AWS Lambda function upon receipt of resource events. Configure the Lambda function to promote the DB cluster in us-west-2 when failure is detected.
Explanation
To meet the requirements of expanding the disaster recovery strategy to the us-west-2 Region with a recovery time objective (RTO) of 15 minutes for a 4 TB Amazon Aurora MySQL DB cluster in the us-east-1 Region, a solutions architect should recommend the following:
D. Recreate the database as an Aurora global database with the primary DB cluster in us-east-1 and a secondary DB cluster in us-west-2. Configure an Amazon EventBridge (Amazon CloudWatch Events) rule that invokes an AWS Lambda function upon receipt of resource events. Configure the Lambda function to promote the DB cluster in us-west-2 when failure is detected.
By creating an Aurora global database, you can have an active-active configuration with a primary DB cluster in the us-east-1 Region and a secondary DB cluster in the us-west-2 Region. The global database feature allows for low-latency global replication, enabling disaster recovery and failover capabilities.
To automate the failover process, you can use Amazon EventBridge (formerly CloudWatch Events) to trigger an AWS Lambda function when failure is detected. The Lambda function can then promote the secondary DB cluster in us-west-2 to become the primary cluster, achieving the RTO of 15 minutes.
Option A, using a Multi-Region Aurora MySQL DB cluster and Amazon Route 53 health checks, is not the optimal choice for meeting the given RTO requirement of 15 minutes.
Option B, taking a snapshot and using Lambda to copy and restore the snapshot in us-west-2, introduces additional complexity and potentially longer recovery times.
Option C, using AWS CloudFormation and Lambda to deploy a new DB cluster in us-west-2, requires more manual intervention and does not leverage the benefits of Aurora global databases for automatic failover.
Therefore, option D is the most suitable recommendation for achieving the desired disaster recovery strategy with a 15-minute RTO.
Reference
AWS > Documentation > AWS Backup > Developer Guide > Monitoring AWS Backup events using EventBridge