Knowledge of terms to know, lists, tips, podcasts, cheat sheets, free tools, and Featured Q&A recommended during July 2021.
CVO (Chief Visionary Officer)?
The Chief Visionary Officer is a newer C-suite title where the holder is expected to have a broad and comprehensive knowledge of all matters related to the business of the organization, as well as the vision required to steer its course into the future.
CVO is being used in corporations to differentiate the holder from other corporate executives, including the Chief Executive Officer (CEO), the Chief Financial Officer, the Chief Information Officer and the Chief Technology Officer (CTO).
The title is sometimes used to define a higher-ranking position than that held by the CEO, and sometimes used to formalize a high-level advisory position. In some cases, the CVO is added to the CEO title (for CEO/CVO status), much in the same way that people with multiple university degrees list them after their names.
The history of the Chief Visionary Officer
The first CVO was Tim Roberts, the young entrepreneurial founder of Broadband Investment Group. Roberts said he invented the title as a rank, superior to CEO, that served to recognize the visionary attributes needed to integrate a complex business with many diverse aspects.
Roberts chose the title solely to define his role in the organization. He didn’t intend the designation to proliferate across the corporate world in the way that it has.
Chief Visionary Officer job requirements
Everyone from startups to enterprises may bring on a CVO to achieve specific goals including, but not limited to:
- requiring guidance for major structural changes
- rapid growth
- a desire to innovate
While the Chief Visionary Officer job may look different for every organization, essentially, the CVO is expected to contribute to the high-level vision and goals for the organization. Therefore, they must have the same core understanding of the business that the founder and co-founder have, as well as the other executives.
They will be intimately involved in strategic planning, nurturing and fostering working relationships interdepartmentally and with external business partners, and creating accountability measures for leaders across departments.
What is RDBMS (relational database management system)?
A relational database management system (RDBMS) is a collection of programs and capabilities that enable IT teams and others to create, update, administer and otherwise interact with a relational database. RDBMSes store data in the form of tables, with most commercial relational database management systems using Structured Query Language (SQL) to access the database. However, since SQL was invented after the initial development of the relational model, it is not necessary for RDBMS use.
The RDBMS is the most popular database system among organizations across the world. It provides a dependable method of storing and retrieving large amounts of data while offering a combination of system performance and ease of implementation.
Compare between RDBMS and DBMS
In general, databases store sets of data that can be queried for use in other applications. A database management system supports the development, administration and use of database platforms.
An RDBMS is a type of database management system (DBMS) that stores data in a row-based table structure which connects related data elements. An RDBMS includes functions that maintain the security, accuracy, integrity and consistency of the data. This is different than the file storage used in a DBMS.
Other differences between database management systems and relational database management systems include:
- Number of allowed users: While a DBMS can only accept one user at a time, an RDBMS can operate with multiple users.
- Hardware and software requirements: A DBMS needs less software and hardware than an RDBMS.
- Amount of data: RDBMSes can handle any amount of data, from small to large, while a DBMS can only manage small amounts.
- Database structure: In a DBMS, data is kept in a hierarchical form, whereas an RDBMS utilizes a table where the headers are used as column names and the rows contain the corresponding values.
- ACID implementation: DBMSes do not use the atomicity, consistency, isolation and durability (ACID) model for storing data. On the other hand, RDBMSes base the structure of their data on the ACID model to ensure consistency.
- Distributed databases: While an RDBMS offers complete support for distributed databases, a DBMS will not provide support.
- Types of programs managed: While an RDBMS helps manage the relationships between its incorporated tables of data, a DBMS focuses on maintaining databases that are present within the computer network and system hard disks.
- Support of database normalization: An RDBMS can be normalized, but a DBMS cannot.
Features of relational database management systems
Elements of the relational database management system that overarch the basic relational database are so intrinsic to operations that it is hard to dissociate the two in practice.
The most basic RDBMS functions are related to create, read, update and delete operations — collectively known as CRUD. They form the foundation of a well-organized system that promotes consistent treatment of data.
The RDBMS typically provides data dictionaries and metadata collections that are useful in data handling. These programmatically support well-defined data structures and relationships. Data storage management is a common capability of the RDBMS, and this has come to be defined by data objects that range from binary large object — or blob — strings to stored procedures. Data objects like this extend the scope of basic relational database operations and can be handled in a variety of ways in different RDBMSes.
The most common means of data access for the RDBMS is SQL. Its main language components comprise data manipulation language and data definition language statements. Extensions are available for development efforts that pair SQL use with common programming languages, such as the Common Business-Oriented Language (COBOL), Java and .NET.
RDBMSes use complex algorithms that support multiple concurrent user access to the database while maintaining data integrity. Security management, which enforces policy-based access, is yet another overlay service that the RDBMS provides for the basic database as it is used in enterprise settings.
RDBMSes support the work of database administrators (DBAs) who must manage and monitor database activity. Utilities help automate data loading and database backup. RDBMSes manage log files that track system performance based on selected operational parameters. This enables measurement of database usage, capacity and performance, particularly query performance. RDBMSes provide graphical interfaces that help DBAs visualize database activity.
While not limited solely to the RDBMS, ACID compliance is an attribute of relational technology that has proved important in enterprise computing. These capabilities have particularly suited RDBMSes for handling business transactions.
As RDBMSes have matured, they have achieved increasingly higher levels of query optimization, and they have become key parts of reporting, analytics and data warehousing applications for businesses as well. RDBMSes are intrinsic to operations of a variety of enterprise applications and are at the center of most master data management systems.
How RDBMS works?
As mentioned before, an RDBMS will store data in the form of a table. Each system will have varying numbers of tables with each table possessing its own unique primary key. The primary key is then used to identify each table.
Within the table are rows and columns. The rows are known as records or horizontal entities; they contain the information for the individual entry. The columns are known as vertical entities and possess information about the specific field.
Before creating these tables, the RDBMS must check the following constraints:
- Primary keys: this identifies each row in the table. One table can only contain one primary key. The key must be unique and without null values.
- Foreign keys: this is used to link two tables. The foreign key is kept in one table and refers to the primary key associated with another table.
- Not null: this ensures that every column does not have a null value, such as an empty cell.
- Check: this confirms that each entry in a column or row satisfies a precise condition and that every column holds unique data.
- Data integrity: the integrity of the data must be confirmed before the data is created.
Assuring the integrity of data includes several specific tests, including entity, domain, referential and user-defined integrity. Entity integrity confirms that the rows are not duplicated in the table. Domain integrity makes sure that data is entered into the table based on specific conditions, such as file format or range of values. Referential integrity ensures that any row that is re-linked to a different table cannot be deleted. Finally, user-defined integrity confirms that the table will satisfy all user-defined conditions.
What are the advantages of relational database management system?
The use of an RDBMS can be beneficial to most organizations; the systematic view of raw data helps companies better understand and execute the information while enhancing the decision-making process. The use of tables to store data also improves the security of information stored in the databases. Users are able to customize access and set barriers to limit the content that is made available. This feature makes the RDBMS particularly useful to companies in which the manager decides what data is provided to employees and customers.
Furthermore, RDBMSes make it easy to add new data to the system or alter existing tables while ensuring consistency with the previously available content.
Other advantages of the RDBMS include:
- Flexibility: updating data is more efficient since the changes only need to be made in one place.
- Maintenance: database administrators can easily maintain, control and update data in the database. Backups also become easier since automation tools included in the RDBMS automate these tasks.
- Data structure: the table format used in RDBMSes is easy to understand and provides an organized and structural manner through which entries are matched by firing queries.
On the other hand, relational database management systems do not come without their disadvantages. For example, in order to implement an RDBMS, special software must be purchased. This introduces an additional cost for execution. Once the software is obtained, the setup process can be tedious since it requires millions of lines of content to be transferred into the RDBMS tables. This process may require the additional help of a programmer or a team of data entry specialists. Special attention must be paid to the data during entry to ensure sensitive information is not placed into the wrong hands.
Some other drawbacks of the RDBMS include the character limit placed on certain fields in the tables and the inability to fully understand new forms of data — such as complex numbers, designs and images.
Furthermore, while isolated databases can be created using an RDBMS, the process requires large chunks of information to be separated from each other. Connecting these large amounts of data to form the isolated database can be very complicated.
Uses of RDBMS
Relational database management systems are frequently used in disciplines such as manufacturing, human resources and banking. The system is also useful for airlines that need to store ticket service and passenger documentation information as well as universities maintaining student databases.
Some examples of specific systems that use RDBMS include IBM, Oracle, MySQL, Microsoft SQLServer and PostgreSQL.
RDBMS product history
Many vying relational database management systems arose as news spread in the early 1970s of the relational data model. This and related methods were originally theorized by IBM researcher E.F. Codd, who proposed a database schema, or logical organization, that was not directly associated with physical organization, as was common at the time.
Codd’s work was based around a concept of data normalization, which saved file space on storage disk drives at a time when such machinery could be prohibitively expensive for businesses.
File systems and database management systems preceded what could be called the RDBMS era. Such systems ran primarily on mainframe computers. While RDBMSes also ran on mainframes — IBM’s DB2 being a pointed example — much of their ascendance in the enterprise was in UNIX midrange computer deployments. The RDBMS was a linchpin in the distributed architecture of client-server computing, which connected pools of stand-alone personal computers to file and database servers.
Numerous RDBMSes arose along with the use of client-server computing. Among the competitors were Oracle, Ingres, Informix, Sybase, Unify, Progress and others. Over time, three RDBMSes came to dominate in commercial implementations. Oracle, IBM’s DB2 and Microsoft’s SQL Server, which was based on a design originally licensed from Sybase, found considerable favor throughout the client-server computing era, despite repeated challenges by competing technologies.
As the 20th century drew to an end, lower-cost, open source versions of RDBMSes began to find use, particularly in web applications.
Eventually, as distributed computing took greater hold, and as cloud architecture became more prominently employed, RDBMSes met competition in the form of NoSQL systems. Such systems were often specifically designed for massive distribution and high scalability in the cloud, sometimes forgoing SQL-style full consistency for so-called eventual consistency of data. But, even in the most diverse and complex cloud systems, the need for some guaranteed data consistency requires RDBMSes to appear in some way, shape or form. Moreover, versions of RDBMSes have been significantly restructured for cloud parallelization and replication.
What is Kubernetes?
Kubernetes is an open-source orchestration platform for working with software containers. Originally designed by Google, Kubernetes is now maintained by the Cloud Native Computing Foundation (CNCF).
Kubernetes helps microservice-based applications to be deployed automatically.
Kubernetes plays an important role in agile software development and provides DevOps teams with the ability to orchestrate virtual machine (VM) clusters. Other advantages of Kubernetes include:
- The ability to schedule containers to run on specific VMs.
- Support for distributed load-balancing.
- Orchestration for cloud-native applications.
When containers are grouped into Kubernetes pods, they can share the same compute, network and storage resources. Multiple pods can be managed through a single controller. Kubernetes application programming interfaces (APIs) are used to manage how and where containers will run.
As a dominant player in open-source containerization, Kubernetes can be mixed and matched with other technologies. Kubernetes is the Greek word for “governor” or “helmsman.” Companies of all shapes and sizes are pursuing Kubernetes as a way to modernize applications.
What is Cyberterrorism?
Cyberterrorism is any premeditated, politically motivated attack against information systems, programs and data that results in violence.
The details of cyberterrorism and the parties involved are viewed differently by various organizations. The U.S. Federal Bureau of Investigation (FBI) defines cyberterrorism as any “premeditated, politically motivated attack against information, computer systems, computer programs and data which results in violence against noncombatant targets by subnational groups or clandestine agents.”
Unlike a nuisance virus or computer attack that results in a denial of service (DoS), the FBI distinguishes a cyberterrorist attack as a type of cybercrime explicitly designed to cause physical harm. However, there is no current consensus between various governments and the information security community on what qualifies as an act of cyberterrorism.
Other organizations and experts suggest that less harmful attacks can also be considered to be acts of cyberterrorism, as long as the attacks are intended to be disruptive or to further the attackers’ political stance. In some cases, the differentiation between cyberterrorism attacks and more ordinary cybercrime activity lies in the intention: The primary motivation for cyberterrorism attacks is to disrupt or harm the victims, even if the attacks do not result in physical harm or cause extreme financial harm.
In other cases, the differentiation is tied to the outcome of a cyber attack; many cybersecurity experts believe an incident should be considered cyberterrorism if it results in physical harm or loss of life, either directly or indirectly through damage or disruption to critical infrastructure. However, others believe physical harm is not a prerequisite for classifying a cyber attack as a terrorist event. The North Atlantic Treaty Organization, for example, has defined cyberterrorism as “a cyber attack using or exploiting computer or communication networks to cause sufficient destruction or disruption to generate fear or to intimidate a society into an ideological goal.”
According to the U.S. Commission on Critical Infrastructure Protection, possible cyberterrorist targets include the banking industry, military installations, power plants, air traffic control centers and water systems.
Methods used for cyberterrorism
The intention of cyberterrorist groups is to cause mass chaos, disrupt critical infrastructure, support political activism or hacktivism, and inflict physical damage or even loss of life. Cyberterrorism actors use a variety of attack methods. These include but are not limited to the following:
- Advanced persistent threat (APT) attacks use sophisticated and concentrated penetration methods to gain network access and stay there undetected for a period of time with the intention of stealing data. Typical targets for APT attacks are organizations with high-value information, such as national defense, manufacturing and the financial industry.
- Computer viruses, worms and malware target information technology (IT) control systems and can affect utilities, transportation systems, power grids, critical infrastructure and military systems, creating instability.
- DoS attacks are intended to prevent legitimate users from accessing targeted computer systems, devices or other computer network resources and can be aimed at critical infrastructure and governments.
- Hacking, or gaining unauthorized access, seeks to steal critical data from institutions, governments and businesses.
- Ransomware, a type of malware, holds data or information systems hostage until the victim pays the ransom.
- Phishing attacks attempt to collect information through a target’s email, using that information to access systems or steal the victim’s identity.
Examples of cyberterrorism
Acts of cyberterrorism can be carried out over computer servers, devices and networks visible through the public internet, as well as against secured government networks or other restricted networks. Examples of cyberterrorism include the following:
- Disruption of major websites to create public inconvenience or to stop traffic to websites containing content the hackers disagree with.
- Unauthorized access that disables or modifies signals that control military technology.
- Disruption of critical infrastructure systems to disable or disrupt cities, cause a public health crisis, endanger public safety or cause massive panic and fatalities — for example, cyberterrorists may target a water treatment plant, cause a regional power outage, or disrupt a pipeline, oil refinery or fracking operation.
- Cyberespionage carried out by governments to spy on rival nations’ intelligence communications, learn about the locations of troops or gain a tactical advantage at war.
Historical instances of cyberterrorism
Between January 2018 and February 2019, the Center for Strategic and International Studies identified 90 cyber attacks that targeted government agencies, defense and high-tech companies, as well as economic crimes with losses in excess of $1 million.
Here are several examples:
- In September 2020, prosecutors in Cologne, Germany, opened a negligent homicide investigation into to an incident where an ailing woman was turned away from a hospital that was in the grips of a ransomware attack. She died on the way to another hospital.
- In 2019 and 2020, the S. Department of Justice (DOJ) charged China’s Huawei Technologies Co. Ltd. with cybercrimes ranging from wire and bank fraud to obstruction of justice and conspiracy to steal trade secrets.
- In February 2019, state-sponsored extremists from China stole personal identification information from the employees of Airbus, a European aerospace company.
- In January 2019, it was revealed that former U.S. intelligence personnel were working with hacker groups from United Arab Emirates to help the country access the phones of activists, diplomats and foreign government officials.
- In July 2018, the DOJ indicted 12 Russian intelligence officers for carrying out large-scale cyber attacks against the Democratic Party in advance of the 2016 presidential election.
- In March 2014, hacktivists in Russia allegedly perpetrated a distributed DoS attack that disrupted the internet in Ukraine, enabling pro-Russian rebels to take control of Crimea.
Defending against cyberterrorism
The key to countering the threat of cyberterrorism is to implement extensive cybersecurity measures and vigilance.
On the corporate level, businesses must ensure that all internet of things devices are properly secured and inaccessible via public networks. To protect against ransomware and similar types of attacks, organizations must regularly back up systems; utilize firewalls, antivirus software and antimalware; and implement continuous monitoring techniques.
Companies must also develop IT security policies to protect business data. This includes limiting access to sensitive data and enforcing strict password and authentication procedures, like two-factor authentication or multifactor authentication.
On the state and national level, the National Cyber Security Alliance recommends training employees on safety protocols and how to detect a cyber attack or malicious code.
The Department of Homeland Security coordinates with other public sector agencies, as well as private sector partners, to share information on potential terrorist activity, how to protect national security and other counterterrorism measures.
On a global level, 38 countries, including the United States, participate in the Council of Europe’s Convention on Cybercrime, which seeks to harmonize international laws, improve investigation and detection capabilities, and promote international cooperation to stop cyberwarfare.
What is Biometrics?
Biometrics is the measurement and statistical analysis of people’s unique physical and behavioral characteristics. The technology is mainly used for identification and access control or for identifying individuals who are under surveillance. The basic premise of biometric authentication is that every person can be accurately identified by intrinsic physical or behavioral traits. The term biometrics is derived from the Greek words bio, meaning life, and metric, meaning to measure.
How do biometrics work?
Authentication by biometric verification is becoming increasingly common in corporate and public security systems, consumer electronics and point-of-sale applications. In addition to security, the driving force behind biometric verification has been convenience, as there are no passwords to remember or security tokens to carry. Some biometric methods, such as measuring a person’s gait, can operate with no direct contact with the person being authenticated.
Components of biometric devices include the following:
- A reader or scanning device to record the biometric factor being authenticated.
- Software to convert the scanned biometric data into a standardized digital format and to compare match points of the observed data with stored data.
- A database to securely store biometric data for comparison.
Biometric data may be held in a centralized database, although modern biometric implementations often depend instead on gathering biometric data locally and then cryptographically hashing it so that authentication or identification can be accomplished without direct access to the biometric data itself.
Types of biometrics
The two main types of biometric identifiers are either physiological characteristics or behavioral characteristics.
Physiological identifiers relate to the composition of the user being authenticated and include the following:
- facial recognition
- fingerprints
- finger geometry (the size and position of fingers)
- iris recognition
- vein recognition
- retina scanning
- voice recognition
- DNA (deoxyribonucleic acid) matching
- digital signatures
Behavioral identifiers include the unique ways in which individuals act, including recognition of typing patterns, mouse and finger movements, website and social media engagement patterns, walking gait and other gestures. Some of these behavioral identifiers can be used to provide continuous authentication instead of a single one-off authentication check. While it remains a newer method with lower reliability ratings, it has the potential to grow alongside other improvements in biometric technology.
Biometric data can be used to access information on a device like a smartphone, but there are also other ways biometrics can be used. For example, biometric information can be held on a smart card, where a recognition system will read an individual’s biometric information, while comparing that against the biometric information on the smart card.
Advantages and disadvantages of biometrics
The use of biometrics has plenty of advantages and disadvantages regarding its use, security and other related functions. Biometrics are beneficial for the following reasons:
- Hard to fake or steal, unlike passwords.
- Easy and convenient to use.
- Generally, the same over the course of a user’s life.
- Nontransferable.
- Efficient because templates take up less storage.
Disadvantages, however, include the following:
- It is costly to get a biometric system up and running.
- If the system fails to capture all of the biometric data, it can lead to failure in identifying a user.
- Databases holding biometric data can still be hacked.
- Errors such as false rejects and false accepts can still happen.
- If a user gets injured, then a biometric authentication system may not work — for example, if a user burns their hand, then a fingerprint scanner may not be able to identify them.
Examples of biometrics in use
Aside from biometrics being in many smartphones in use today, biometrics are used in many different fields. As an example, biometrics are used in the following fields and organizations:
- Law enforcement: It is used in systems for criminal IDs, such as fingerprint or palm print authentication systems.
- United States Department of Homeland Security: It is used in Border Patrol branches for numerous detection, vetting and credentialing processes — for example, with systems for electronic passports, which store fingerprint data, or in facial recognition systems.
- Healthcare: It is used in systems such as national identity cards for ID and health insurance programs, which may use fingerprints for identification.
- Airport security: This field sometimes uses biometrics such as iris recognition.
However, not all organizations and programs will opt in to using biometrics. As an example, some justice systems will not use biometrics so they can avoid any possible error that may occur.
What are security and privacy issues of biometrics?
Biometric identifiers depend on the uniqueness of the factor being considered. For example, fingerprints are generally considered to be highly unique to each person. Fingerprint recognition, especially as implemented in Apple’s Touch ID for previous iPhones, was the first widely used mass-market application of a biometric authentication factor.
Other biometric factors include retina, iris recognition, vein and voice scans. However, they have not been adopted widely so far, in some part, because there is less confidence in the uniqueness of the identifiers or because the factors are easier to spoof and use for malicious reasons, like identity theft.
Stability of the biometric factor can also be important to acceptance of the factor. Fingerprints do not change over a lifetime, while facial appearance can change drastically with age, illness or other factors.
The most significant privacy issue of using biometrics is that physical attributes, like fingerprints and retinal blood vessel patterns, are generally static and cannot be modified. This is distinct from nonbiometric factors, like passwords (something one knows) and tokens (something one has), which can be replaced if they are breached or otherwise compromised. A demonstration of this difficulty was the over 20 million individuals whose fingerprints were compromised in the 2014 U.S. Office of Personnel Management data breach.
The increasing ubiquity of high-quality cameras, microphones and fingerprint readers in many of today’s mobile devices means biometrics will continue to become a more common method for authenticating users, particularly as Fast ID Online has specified new standards for authentication with biometrics that support two-factor authentication with biometric factors.
While the quality of biometric readers continues to improve, they can still produce false negatives, when an authorized user is not recognized or authenticated, and false positives, when an unauthorized user is recognized and authenticated.
Are biometrics secure?
While high-quality cameras and other sensors help enable the use of biometrics, they can also enable attackers. Because people do not shield their faces, ears, hands, voice or gait, attacks are possible simply by capturing biometric data from people without their consent or knowledge.
An early attack on fingerprint biometric authentication was called the gummy bear hack, and it dates back to 2002 when Japanese researchers, using a gelatin-based confection, showed that an attacker could lift a latent fingerprint from a glossy surface. The capacitance of gelatin is similar to that of a human finger, so fingerprint scanners designed to detect capacitance would be fooled by the gelatin transfer.
Determined attackers can also defeat other biometric factors. In 2015, Jan Krissler, also known as Starbug, a Chaos Computer Club biometric researcher, demonstrated a method for extracting enough data from a high-resolution photograph to defeat iris scanning authentication. In 2017, Krissler reported defeating the iris scanner authentication scheme used by the Samsung Galaxy S8 smartphone. Krissler had previously recreated a user’s thumbprint from a high-resolution image to demonstrate that Apple’s Touch ID fingerprinting authentication scheme was also vulnerable.
After Apple released iPhone X, it took researchers just two weeks to bypass Apple’s Face ID facial recognition using a 3D-printed mask; Face ID can also be defeated by individuals related to the authenticated user, including children or siblings.
What is Risk analysis?
Risk analysis is the process of identifying and analyzing potential issues that could negatively impact key business initiatives or projects. This process is done in order to help organizations avoid or mitigate those risks.
Performing a risk analysis includes considering the possibility of adverse events caused by either natural processes, like severe storms, earthquakes or floods, or adverse events caused by malicious or inadvertent human activities. An important part of risk analysis is identifying the potential for harm from these events, as well as the likelihood that they will occur.
Why is risk analysis important?
Enterprises and other organizations use risk analysis to:
- Anticipate and reduce the effect of harmful results from adverse events.
- Evaluate whether the potential risks of a project are balanced by its benefits to aid in the decision process when evaluating whether to move forward with the project.
- Plan responses for technology or equipment failure or loss from adverse events, both natural and human-caused.
- Identify the impact of and prepare for changes in the enterprise environment, including the likelihood of new competitors entering the market or changes to government regulatory policy.
What are the benefits of risk analysis?
Organizations must understand the risks associated with the use of their information systems to effectively and efficiently protect their information assets.
Risk analysis can help an organization improve its security in a number of ways. Depending on the type and extent of the risk analysis, organizations can use the results to help:
- Identify, rate and compare the overall impact of risks to the organization, in terms of both financial and organizational impacts.
- Identify gaps in security and determine the next steps to eliminate the weaknesses and strengthen security.
- Enhance communication and decision-making processes as they relate to information security.
- Improve security policies and procedures and develop cost-effective methods for implementing these information security policies and procedures.
- Put security controls in place to mitigate the most important risks.
- Increase employee awareness about security measures and risks by highlighting best practices during the risk analysis process.
- Understand the financial impacts of potential security risks.
Done well, risk analysis is an important tool for managing costs associated with risks, as well as for aiding an organization’s decision-making process.
Steps in risk analysis process
The risk analysis process usually follows these basic steps:
- Conduct a risk assessment survey: This first step, getting input from management and department heads, is critical to the risk assessment process. The risk assessment survey is a way to begin documenting specific risks or threats within each department.
- Identify the risks: The reason for performing risk assessment is to evaluate an IT system or other aspect of the organization and then ask: What are the risks to the software, hardware, data and IT employees? What are the possible adverse events that could occur, such as human error, fire, flooding or earthquakes? What is the potential that the integrity of the system will be compromised or that it won’t be available?
- Analyze the risks: Once the risks are identified, the risk analysis process should determine the likelihood that each risk will occur, as well as the consequences linked to each risk and how they might affect the objectives of a project.
- Develop a risk management plan: Based on an analysis of which assets are valuable and which threats will probably affect those assets negatively, the risk analysis should produce control recommendations that can be used to mitigate, transfer, accept or avoid the risk.
- Implement the risk management plan: The ultimate goal of risk assessment is to implement measures to remove or reduce the risks. Starting with the highest-priority risk, resolve or at least mitigate each risk so it’s no longer a threat.
- Monitor the risks: The ongoing process of identifying, treating and managing risks should be an important part of any risk analysis process.
The focus of the analysis, as well as the format of the results, will vary depending on the type of risk analysis being carried out.
Qualitative vs. quantitative risk analysis
The two main approaches to risk analysis are qualitative and quantitative. Qualitative risk analysis typically means assessing the likelihood that a risk will occur based on subjective qualities and the impact it could have on an organization using predefined ranking scales. The impact of risks is often categorized into three levels: low, medium or high. The probability that a risk will occur can also be expressed the same way or categorized as the likelihood it will occur, ranging from 0% to 100%.
Quantitative risk analysis, on the other hand, attempts to assign a specific financial amount to adverse events, representing the potential cost to an organization if that event actually occurs, as well as the likelihood that the event will occur in a given year. In other words, if the anticipated cost of a significant cyberattack is $10 million and the likelihood of the attack occurring during the current year is 10%, the cost of that risk would be $1 million for the current year.
A qualitative risk analysis produces subjective results because it gathers data from participants in the risk analysis process based on their perceptions of the probability of a risk and the risk’s likely consequences. Categorizing risks in this way helps organizations and/or project teams decide which risks can be considered low priority and which have to be actively managed to reduce the effect on the enterprise or the project.
A quantitative risk analysis, in contrast, examines the overall risk of a project and generally is conducted after a qualitative risk analysis. The quantitative risk analysis numerically analyzes the probability of each risk and its consequences.
The goal of a quantitative risk analysis is to associate a specific financial amount to each risk that has been identified, representing the potential cost to an organization if that risk actually occurs. So, an organization that has done a quantitative risk analysis and is then hit with a data breach should be able to easily determine the financial impact of the incident on its operations.
A quantitative risk analysis provides an organization with more objective information and data than the qualitative analysis process, thus aiding in its value to the decision-making process.
What is Social Media Analytics?
Social media analytics is the process of collecting and analyzing audience data shared on social networks to improve an organization’s strategic business decisions.
Social media can benefit businesses by enabling marketers to spot trends in consumer behavior that are relevant to a business’s industry and can influence the success of marketing efforts.
Another important example of how social media analytics supports marketing campaigns is by providing the data to quantify the return on investment (ROI) of a campaign based on the traffic gained from various social media channels.
Furthermore, marketers can analyze performance of different social platforms — such as Facebook, LinkedIn and Twitter — and of specific social media posts to determine which messaging and topics resonate best with a target audience.
What are the use cases of social media analytics?
Social media analysis platforms can track and analyze a range of data and interactions used in a variety of social media marketing use cases.
Measure the ROI of social media marketing efforts
The main goal for any social media post, like, retweet or share is ROI.
To determine social media ROI, marketers must first determine an initial benchmark and then have a way to measure key performance indicators (KPIs) against that benchmark over time. When efforts aren’t working well, analysis of those metrics will reveal tweaks marketers can make to improve the performance of the campaign and overall ROI.
In fact, a recent study from Hootsuite, a vendor offering a social media management platform, found that 85% of organizations that began measuring social media data within their analytics tools were able to accurately show ROI for those efforts.
To begin tracking social media campaign performance, a tracking pixel or Google Analytics UTM parameter can be added to any links used in social media posts or ads. That will show any conversions that came from social media marketing and can help with planning retargeting campaigns for visitors who didn’t convert.
Improve strategic decision-making
Social media analytics can improve a marketing team’s ability to understand what social media strategies are working and which ones aren’t as effective.
However, the analytical results can also provide insight that can be useful for making business decisions about other important aspects of the business not necessarily directly related to the marketing campaigns.
For example, with social listening tools, audience and competition can be analyzed by extracting useful insight from social media data being posted on various social media networks like LinkedIn and Facebook. It can also provide demographic information about the audience that will enable enhanced marketing efforts targeting that sector and more effectively create brand awareness.
By using real-time data, emerging trends may be detected that can give a business a jump on the competition by posting social media content sooner.
Track the efficiency of marketing teams
Most organizations strive to streamline workflows and enable team members to be more productive. A lesser known, but still important, feature of social media analytics is its ability to improve efficiency with your marketing team.
In addition to the KPIs for your social media content, you can also measure aspects like response time and customer sentiment.
Showing the chief marketing officer areas where workflows can be automated and resources can be redirected to strategic activities that directly impact revenue are key to obtaining marketing budget and approvals for future campaigns.
What metrics should be tracked with social media analytics?
There are six general types of social media metrics that should be tracked.
Performance metrics
Measuring the performance of social media marketing efforts is critical to understanding where strategic efforts are working and where improvement is needed.
Key performance metrics to track include the following:
- interactions across platforms and over time to determine if the posted content is properly engaging the audience;
- whether the number of followers is increasing over time to verify consistent progress across platforms; and
- click-through rate for link clicks on posts to see if they’re properly driving traffic from social media channels.
Audience analytics
It’s important to clearly understand and define the target audience, as it is the most important element of a social media strategy. Understanding the audience will help create a favorable customer experience with content targeted at what customers want and what they’re looking for.
In the past, audience data was difficult to measure as it was scattered across multiple social media platforms. But with analytics tools, marketers can analyze data across platforms to better understand audience demographics, interests and behaviors. AI-enabled tools can even help predict customer behavior. They can also study how an audience changes over time.
The better targeted the content is, the less advertising will cost and the cost-per-click of ads can be optimized.
Competitor analytics
To obtain a full understanding of performance metrics, it’s necessary to look at the metrics through a competitive lens. In other words, how do they stack up to competitors’ performance?
With social media analytics tools, social media performance can be compared to competitors’ performance with a head-to-head analysis to gauge relative effectiveness and to determine what can be improved.
Most modern tools that include AI capabilities can benchmark competitor performance by industry to determine a good starting point for social media efforts.
Paid social analytics
Ad spending is serious business. If targeting and content isn’t right, it can end up an expensive proposition for unsuccessful content. More advanced analytics tools can often predict which content is most likely to perform well and be a less risky investment for a marketing budget.
For best results, an all-in-one platform is the preferred choice to track performance across all social media accounts such as Twitter analytics, paid Facebook posts or LinkedIn ads. Important metrics to track include the following:
- Total number of active ads
- Total ad spend
- Total clicks
- Click-through rate
- Cost per click
- Cost per engagement
- Cost per action
- Cost per purchase
These metrics will indicate exactly where each dollar spent is going and how much return is being generated for social media efforts. They can also be compared against competitor spending to ensure that spending is at an appropriate level and to reveal strategic opportunities where an increased share of voice may be attainable.
Influencer analytics
To gain a leg up on competition in a competitive space, many social media marketers will collaborate with social influencers as part of their marketing campaigns. To make the most of partnerships, it’s necessary to measure key metrics to ensure that the influencer marketing is achieving desired goals.
Social media analytics can provide insights into the right metrics to ensure that influencer campaigns are successful. Some influencer metrics that should be tracked include the following:
- total interactions per 1,000 followers to understand if they’re properly generating engagement;
- audience size and most frequently used hashtags, to help determine the maximum reach of your campaign;
- the number of posts influencers create on a regular basis, to help determine how active they are and how powerful engagement can be; and
- past collaborations, which can be a great indicator of the potential for success with an influencer.
Sentiment analysis
Sentiment analysis is an important metric to measure as it can indicate whether a campaign is gaining favorability with an audience or losing it. And for customer service oriented businesses, sentiment analysis can reveal potential customer care issues.
To ensure that a campaign is in sync with the target audience and maintains a strong rate of growth, interactions and engagement rate should be tracked over time. A decline could indicate that a change of course is needed.
Gathering and analyzing customer sentiment can help avoid guesswork in developing a marketing strategy and deciding which content will resonate best with the audience. This type of analysis can also indicate the type of content that’s likely to have a positive impact on customer sentiment If your social media analytics tool detects a spike in negative sentiment, action should be taken immediately to address and correct it before it becomes a PR nightmare.
Social media analytics tools
While many businesses use some sort of social media management tool, most of these baseline scheduling tools don’t go far enough to provide the in-depth metrics and data points that social media analytics tools can deliver.
Not only can this deeper level of insight go a long way to inform a successful campaign, it can also be shared with stakeholders to show high-level ROI across disparate social media channels.
An effective analytics tool will have an intuitive, easy-to-use interface that enables transparency in a campaign; it should also streamline the social media marketing processes and workflows.
Examples of social media analytics tools include Sprout Social, Google Analytics, Hootsuite and Buffer Analyze.
What is Nonfungible token (NFT)?
A nonfungible token (NFT) is a type of cryptographic asset that is unique and used to create and authenticate ownership of digital assets. These include cartoons, music, film and video clips, JPEGs, postcards, sports trading cards, and virtual real estate or pets. NFTs provide a secure record that is stamped with unique identifying code stored on blockchain.
In contrast to stocks, bonds and other traditional investments, NFTs are considered an alternative investment that is not fungible, or replaceable, with a similar item. Demand for NFTs, which are like rare collectibles, picked up steam in 2020 and increased dramatically in 2021. This drove up the price of digital artworks, with celebrities, content creators, auction houses and others participating in the market.
How do NFTs work?
The one-of-a-kind qualities of NFTs make them “nonfungible.” This contrasts with “fungible” assets, such as Bitcoin and other cryptocurrencies, dollar bills, gold bars or stock, that are worth a specific amount and are interchangeable. Although one dollar bill can be exchanged for another dollar bill, or one bitcoin can easily be swapped for another, that is not the case with NFTs.
NFTs are also nondivisible. The basic unit of the NFT is the token, which cannot be divided into smaller denominations, as a dollar might be divided into 10 dimes. However, NFTs may be divisible in the future.
Additionally, NFTs are immutable. NFTs cannot be altered once they have been encoded using blockchain technology. The originality and legitimacy of the item is validated through the blockchain in which it is stored.
Blockchain technology establishes ownership of the NFT. Blockchain acts as a decentralized ledger, enabling NFTs to be authenticated publicly to provide a digital signature to prove who owns it and that it is an original work. An NFT buyer would not own a piece of art to hang on a wall but rather a digital image of that artwork and digital certificate of authentication.
The NFT buyer does not own the copyright or trademark of the item. Although there may also be numerous versions it on the internet, NFT buyers have an original in the virtual world.
Furthermore, royalties can be programmed into the token, enabling artists to collect a portion of sales in the future. Other possible technical features include fractional ownership, in which individual investors own a percentage of the NFT and its benefits.
Why are NFTs important?
The surge in popularity of NFTs is a result of their “improved ease of onboarding, speculative nature as both a collectible and investment and grassroots communities developed around the products,” explained Justin Herzig, co-founder of Own the Moment, which provides content, tools and analytics on NFTs.
NFTs enable individuals to buy and sell digital assets in new ways. They help artists and other content creators display their skills digitally and provide the ability to securely value, buy and exchange digital art using a digital ledger. Using NFTs, new and previously decentralized actors can develop innovative value exchanges to build new market structures.
NFTs are a significant form of alternative investment that appeals to buyers’ “personal interests and passions,” explained Herzig, pointing to figures from Preqin projecting a $14 trillion alternative investment industry by 2023. With NFTs, retail investors will be able to have a more personal connection to an interest while investing in areas of financial and utility value.
The NFT buyer hopes the value of the token will increase with time, similar to all investments. Just like their fungible cousins, NFTs are subject to shifts in supply and demand.
According to the NFT Yearly Report 2020, published by NFT market analysis firm Nonfungible.com, the total value of NFT transactions is estimated to have surged from to $62.9 million in 2019 to $250.8 million in 2020. In the first quarter of 2021, more than $2 billion was invested in NFTs, compared with $93 million in the fourth quarter of 2020.
What are uses and examples of NFTs?
An early use of NFTs was a game launched in 2017 called CryptoKitties, in which users could trade and sell virtual kittens. In 2021, NFTs that sparked attention included Twitter CEO Jack Dorsey’s first-ever tweet and work by Beeple, the professional name used by artist Mike Winkelmann, who sold his piece “Everydays: The First 5000 Days” for $69 million.
NFTs are currently being used to sell a range of virtual collectibles, including the following:
- NBA virtual trading cards
- Digital sneakers from Nike
- Trading cards featuring personal memorabilia from actor William Shatner
- A full studio album by rock band Kings of Leon
- The original “nyan cat” meme
- Collectible virtual characters called CryptoPunks
- A variety of GIFs and images commissioned by Taco Bell, with proceeds going towards the restaurant chain’s charity organization
- Virtual real estate in Decentraland, a 3D virtual reality platform
Today, the primary owners and collectors of NFTs are enthusiasts with a strong interest in a domain or project. However, NFTs are expected to become mainstream and attract retail investors eventually as the products and technology improve.
How are NFTs created?
NFTs are created using smart contracts. Smart contract code is incorporated into the token when it is created or minted. Stored on blockchain, the smart contract determines the NFT’s qualities, such as ownership and transferability.
The smart contract is autonomous, containing the terms and conditions of an agreement directly within the lines of code. Each NFT is linked to a single token that is stored in a smart contract, which runs on top of the distributed ledger to provide proof of ownership and verifiable originality. Even though there are other copies of the same content, only one person can own the particular token that authenticates ownership of the NFT.
Smart contracts are a crucial feature of blockchain technology. While most NFTs reside on the Ethereum blockchain, some are based on other blockchain technologies, such as TRON and NEO. Blockchain also helps ensure that NFTs remain secure.
While NFTs gain popularity, market participants and observers are becoming increasingly aware of the impact that NFTs will have on the environment. The use of blockchain generates greenhouse gases, which have a significant effect on the world’s carbon footprint.
How are NFTs bought and sold?
As demand for NFTs grows, new marketplaces continue to surface. Popular marketplaces for creators to sell NFTs include:
- OpenSea
- Rarible
- Myth Market
- BakerySwap
- SuperRare
- Foundation
- AtomicMarket
- KnownOrigin
- Enjin Marketplace
- Portion
The typical process to buy or sell an NFT as follows:
- Set up a digital wallet and purchase cryptocurrency, such as ether, using an app, such as Coinbase, Robinhood or MetaMask.
- Connect the digital wallet to an NFT marketplace
- Mint or list the NFT for sale, or start bidding on or purchasing pieces of content.
Users can auction bids or purchase outright, depending on the seller and marketplace.
The future of NFTs
As with all market assets, principles of supply and demand apply to the NFT marketplace. Buyers should be cautious, as they should be with any type of investment, and keep their eyes open as the market evolves.
“An NFT is only as valuable as what others are willing to pay for it,” Herzig said. “NFTs that can build a deep connection with collectors and investors have shown an increased likelihood of having long-term staying power.”
Collectors and investors can understand the current value for NFTs better by viewing previous and similar sales on established marketplaces. The long-term viability of NFTs will depend on the distinction of their utility value, not just theoretical. Like with other collectables, this will happen once owners view NFTs as uniquely valuable experiences or features. NFT communities will develop and grow, helping to maintain prices and markets and strengthen the trust in their long-term survival.
What is Natural language generation (NLG)?
Natural language generation (NLG) is the use of artificial intelligence (AI) programming to produce written or spoken narratives from a data set. NLG is related to human-to-machine and machine-to-human interaction, including computational linguistics, natural language processing (NLP) and natural language understanding (NLU).
Research about NLG often focuses on building computer programs that provide data points with context. Sophisticated NLG software can mine large quantities of numerical data, identify patterns and share that information in a way that is easy for humans to understand. The speed of NLG software is especially useful for producing news and other time-sensitive stories on the internet. At its best, NLG output can be published verbatim as web content.
How NLG works?
NLG is a multi-stage process, with each step further refining the data being used to produce content with natural-sounding language. The six stages of NLG are as follows:
- Content analysis: Data is filtered to determine what should be included in the content produced at the end of the process. This stage includes identifying the main topics in the source document and the relationships between them.
- Data understanding: The data is interpreted, patterns are identified and it’s put into context. Machine learning is often used at this stage.
- Document structuring: A document plan is created and a narrative structure chosen based on the type of data being interpreted.Sentence aggregation. Relevant sentences or parts of sentences are combined in ways that accurately summarize the topic.
- Grammatical structuring: Grammatical rules are applied to generate natural-sounding text. The program deduces the syntactical structure of the sentence. It then uses this information to rewrite the sentence in a grammatically correct manner.
- Language presentation: The final output is generated based on a template or format the user or programmer has selected.
How is NLG used?
Natural language generation is being used in an array of ways. Some of the many uses include the following:
- generating the responses of chatbots and voice assistants such as Google’s Alexa and Apple’s Siri;
- converting financial reports and other types of business data into easily understood content for employees and customers;
- automating lead nurturing email, messaging and chat responses;
- personalizing responses to customer emails and messages;
- generating and personalizing scripts used by customer service representatives;
- aggregating and summarizing news reports;
- reporting on the status of internet of things devices; and
- creating product descriptions for e-commerce webpages and customer messaging.
What’s different between NLG, NLU, and NLP?
NLP is an umbrella term that refers to the use of computers to understand human language in both written and verbal forms. NLP is built on a framework of rules and components, and it converts unstructured data into a structured data format.
NLP encompasses both NLG and NLU, which have the following distinct, but related capabilities:
- NLU refers to the ability of a computer to use syntactic and semantic analysis to determine the meaning of text or speech.
- NLG enables computing devices to generate text and speech from data input.
Chatbots and “suggested text” features in email clients, such as Gmail’s Smart Compose, are examples of applications that use both NLU and NLG. Natural language understanding lets a computer understand the meaning of the user’s input, and natural language generation provides the text or speech response in a way the user can understand.
NLG is connected to both NLU and information retrieval. It is also related to text summarization, speech generation and machine translation. Much of the basic research in NLG also overlaps with computational linguistics and the areas concerned with human-to-machine and machine-to-human interaction.
NLG models and methodologies
NLG relies on machine learning algorithms and other approaches to create machine-generated text in response to user inputs. Some of the methodologies used include the following:
Markov chain: The Markov model is a mathematical method used in statistics and machine learning to model and analyze systems that are able to make random choices, such as language generation. Markov chains start with an initial state and then randomly generate subsequent states based on the prior one. The model learns about the current state and the previous state and then calculates the probability of moving to the next state based on the previous two. In a machine learning context, the algorithm creates phrases and sentences by choosing words that are statistically likely to appear together.
Recurrent neural network (RNN): These AI systems are used to process sequential data in different ways. RNNs can be used to transfer information from one system to another, such as translating sentences written in one language to another. RNNs are also used to identify patterns in data which can help in identifying images. An RNN can be trained to recognize different objects in an image or to identify the various parts of speech in a sentence.
Long short-term memory (LSTM): This type of RNN is used in deep learning where a system needs to learn from experience. LSTM networks are commonly used in NLP tasks because they can learn the context required for processing sequences of data. To learn long-term dependencies, LSTM networks use a gating mechanism to limit the number of previous steps that can affect the current step.
Transformer: This neural network architecture is able to learn long-range dependencies in language and can create sentences from the meanings of words. Transformer is related to AI. It was developed by OpenAI, a nonprofit AI research company in San Francisco. Transformer includes two encoders: one for processing inputs of any length and another to output the generated sentences.
The three main Transformer models are as follows:
- Generative Pre-trained Transformer (GPT) is a type of NLG technology used with business intelligence (BI) software. When GPT is implemented with a BI system, it uses NLG technology or machine learning algorithms to write reports, presentations and other content. The system generates content based on information it is fed, which could be a combination of data, metadata and procedural rules.
- Bidirectional Encoder Representations from Transformers (BERT) is the successor to the Transformer system that Google originally created for its speech recognition service. BERT is a language model that learns human language by learning the syntactic information, which is the relationships between words, and the semantic information, which is the meaning of the words.
- XLNet is an artificial neural network that is trained on a set of data. It identifies patterns that it uses to make a logical conclusion. An NLP engine can extract information from a simple natural language query. XLNet aims to teach itself to be able to read and interpret text and use this knowledge to write new text. XLNet has two parts: an encoder and a decoder. The encoder uses the syntactic rules of language to convert sentences into vector-based representation; the decoder uses these rules to convert the vector-based representation back into a meaningful sentence.
What is Hacktivism?
Hacktivism is the act of misusing a computer system or network for a socially or politically motivated reason. Individuals who perform hacktivism are known as hacktivists.
Hacktivism is meant to call the public’s attention to something the hacktivist believes is an important issue or cause, such as freedom of information, human rights or a religious point of view. Hacktivists express their support of a social cause or opposition to an organization by displaying messages or images on the website of the organization they believe is doing something wrong or whose message or activities they oppose.
Hacktivists are typically individuals, but there are hacktivist groups as well that operate in coordinated efforts. Anonymous and Lulz Security, also known as LulzSec, are examples. Most hacktivists work anonymously.
What motivates hacktivists?
Hacktivists usually have altruistic or ideological motives, such as social justice or free speech. Their goal is to disrupt services and bring attention to a political or social cause. For example, hacktivists might leave a visible message on the homepage of a website that gets a lot of traffic or embodies a point of view that the individual or group opposes. Hacktivists often use denial-of-service or distributed DoS (DDoS) attacks where they overwhelm a website and disrupt traffic.
Hacktivists want others to notice their work to inspire action or change. They often focus on social change but also target government, business and other groups that they don’t agree with for their attacks. Sending a message and eliciting change trump profit motives for hacktivists.
What is the difference between a hacker and a hacktivist?
Hackers and hacktivists generally use the same tools and techniques to achieve their goals. Unlike hacktivists, hackers are not defined solely by social causes. The answer to the question, “Is hacktivism good or bad?” is a point of debate. The legality of hacktivist acts is less contentious.
DoS and DDoS attacks are federal crimes in the United States under the Computer Fraud and Abuse Act. Those types of attacks are illegal in many other places as well, including the European Union, United Kingdom and Australia. Website defacement, where attackers access a website and change its contents, is considered cyber vandalism and is a crime. Corporate data theft is also illegal.
Opponents of hacktivism argue that these acts cause damage in a forum where there is already ample opportunity for nondisruptive free speech. Others insist that such acts are the equivalent of peaceful protest and, therefore, are protected as a form of free speech. Hacktivists often consider their activities a form of civil disobedience, meaning they are willfully breaking a law to further their protest.
Types of hacktivism
Hacktivists use a variety of techniques to get their message across. Their tactics include the following:
- Anonymous blogging: Activists, whistleblowers and journalists use this tactic. It protects the blogger, while providing a platform for them to speak out about an issue, such as human rights violations or oppressive government regimes.
- DoS and DDoS attacks: Hacktivists use these attacks to prevent users from accessing targeted computer systems, devices or networks. DoS and DDoS attacks flood systems with traffic, overwhelm resources and make them difficult to access.
- Doxing: This involves the gathering of information — through hacking or social engineering — about a person or organization and making it public. The information is typically sensitive and is sometimes used in extortion schemes.
- Geobombing: This technique enables internet users to add a geotag to YouTube videos to display the location of the video on Google Earth and Google Maps. Hacktivists use geobombing to display the location of videos posted by political prisoners and human rights activists.
- Leaking information: This is a popular activist tactic. Typically, an insider source will access sensitive or classified information — which implicates an individual, organization or government agency in an activity that reflects negatively on them — and make it public. WikiLeaks is known for publishing leaked data.
- RECAP: This software lets users search for free copies of documents that are otherwise only accessible by paying a fee to the United States federal court database known as Public Access to Court Electronic Records (PACER). RECAP is PACER spelled backwards.
- Website defacement: Hacktivists change a website’s code or software so visitors see errors or messages expressing the attacker’s point of view. The message may be threatening or embarrassing, or the attack may disable a key function of the site or software to get the hacktivist’s message across.
- Website mirroring: Here, hacktivists replicate a legitimate website’s content but with a slightly different URL. This technique is often used to get around censorship that blocks a site. If a website has been censored, the hacktivist will duplicate the content and attach it to a different URL on a mirror site so the content is still accessible.
Examples of hacktivist groups
Many hacktivist groups keep a low profile. The following are among the more well-known organizations.
Cult of the Dead Cow
This group, also known as cDc Communications, was founded in 1984 as a hacking collective and media organization. Its original stated goal was “global domination through media saturation,” but it eventually evolved a more political focus on human rights and the free flow of information. In the mid to late 1990s, the group focused on combating human rights abuses in China. During this initiative, a member of the group who went by the name Omega coined the term hacktivism when communicating with Chinese hacktivists via a group email.
CDc spun off two other hacktivist groups: Ninja Strike Force, founded in 1996, and Hacktivismo, formed in 1999. Hacktivismo focused on creating anti-censorship technology. It took a unique stand against using DoS attacks, saying it viewed disabling websites as counter to the principle of free speech online. Hacktivismo also published a code of conduct for civil disobedience online, entitled the “Hacktivismo Declaration,” in which it said it would challenge state-sponsored censorship of the internet. CDc and Hacktivismo are credited with putting a positive spin on the term hacker.
Anonymous
This decentralized, international group has become one of the most well-known hacktivist groups because of several high-profile attacks. Anonymous first appeared in 2003 on the 4chan forums and came into the spotlight in 2008 when it attacked the Church of Scientology. The group has adopted the Guy Fawkes mask from the graphic novel by Alan Moore and film V for Vendetta as its symbol. The group often uses the tagline: “We are Anonymous. We are Legion. We do not forgive. We do not forget. Expect us.”
Anonymous’ members do not identify themselves. Nevertheless, several individuals associated with the group have been arrested for illegal activities. The group is known to use controversial techniques, such as doxing, and it has declared war on politicians, including Donald Trump and Hillary Clinton, and has supported the Occupy Wall Street movement.
WikiLeaks
Julian Assange launched the WikiLeaks website in 2006 to host leaked documents, describing itself as an independent, nonprofit online media organization. The first notable documents published on the site were the nearly 80,000 documents about the U.S. war in Afghanistan leaked in 2010, followed by nearly 400,000 documents about the war in Iraq. WikiLeaks is also known for revealing over 20,000 emails and 8,000 email attachments from the Democratic National Committee that were sent during the 2016 U.S. presidential campaign.
LulzSec
Five members of Anonymous started LulzSec in 2011 and use handles but not any other identifying information. The most significant LulzSec attack was when it took down the Federal Bureau of Investigation’s website in 2011. The attack precipitated the arrest of several members.
Syrian Electronic Army
This group of Syrian hacktivists also surfaced in 2011 and claims to support Syrian president Bashar al-Assad. The group was hosted on Syria’s national public networks and aims to defend the Syrian government’s reputation and to attack computer systems deemed a threat to Syria. The group gained attention in April 2013 when it performed several DDoS and defacement attacks against U.S. government agencies and companies, including a fake tweet about an explosion at the White House that injured the president.
Longstanding, influential hacktivist groups, like Anonymous and WikiLeaks, continue to make themselves heard. Investigative journalist Nicky Hager described the impact of WikiLeaks publishing the Iraq War Logs and a video of a U.S. helicopter firing on civilians.
What is Hacking as a service (HaaS)?
Hacking as a service (HaaS) is the commercialization of hacking skills, in which the hacker serves as a contractor. HaaS makes advanced code-breaking skills available to anyone with a web browser and a credit card. In addition to exploits, HaaS can also be contracted for ethical hacking purposes, such as penetration testing.
While there have been grey markets for HaaS for a long time, there are now purpose-driven websites to hire for the skill. One such site, Hackers List, offers a money back guarantee, formalized reviews, complaint processes and a list of hackers with specified skills. Additionally, there are HaaS tools and platforms like Alienspy that simplify hacking to let a person with no skills carry out an attack themselves.
Some of the services offered in HaaS include:
- Gaining access to the social networking accounts of another person.
- DoS (denial of service) and DDoS (distributed denial of service) attacks on websites
- Telephone DoS.
- Telephone number hijacking and call blocking.
- Network infrastructure attacks to bring down communications.
- Command and control (C&C) of a own huge botnet army (for around $20K).
It should be noted that hiring HaaS to perform illegal act is in itself illegal since inducement to commit a crime is itself a crime under United States law.
What is Geotagging?
Geotagging is the process of adding metadata that contains geographical information about a location to a digital map. The data usually consists of latitude and longitude coordinates, but may also include a timestamp, as well as links to additional information. Geotag metadata can be added manually or programmatically.
In Google Maps and similar GPS services, geotagging may also be referred to as dropping a pin. Pins can be tagged with contextual information to share information about a specific physical location. Popular types of contextual info include photos, videos, website URLs and QR codes.

The red icon above is called a pin and its use on a digital map indicates that a location that has been geotagged. End users can view a pin’s additional metadata by hovering their finger or mouse over the icon.
Location identification has become a fundamental feature of many social media sites and can be a useful tool when added to business applications and medicolegal applications. For example, some social networking sites and services give out the location of their users, which allows users to know exactly where their friends are as they are logged on to that website (or check in to the service). Since devices and tracking are now ubiquitous, that social media tracking becomes a more powerful and valuable tool for users.
Contrast that with the ways that geo-tagging first developed, as mainly a way to tag digital assets like photos with metadata. Using the principle of geospatial contextual information, users were able to read labeling data from an archive, but not typically use insights in real time. That came later, as geo-tagging kept developing into what it represents today.
How Does Geotagging Work?
Methodologies for geotagging very quite a bit. Some of them work with geospatial location and “toponym” information only in an archival context, where others stream content continually, or aggregate content for machine learning models.
Regardless of how they are set up and what they do, geotagging systems all represent the same fundamental idea: that digital tracking of location provides value-added services in a given application context.
What are the advantages and disadvantages of Geotags?
Security professionals urge everyday users to beware adding too much locational data to their profiles or other means of input, because criminals could use that data to conduct cyberattacks or track their whereabouts physically.
On the other hand, geotagging has also been a great boon to law enforcement in general – from nationwide license plate tracking databases to forensic digital work, law enforcement uses all of that geotagging to better understand suspected criminal activity and fine-tune the ability of the legal system to produce accurate results.
What is Object-oriented programming (OOP)?
Object-oriented programming (OOP) is a computer programming model that organizes software design around data, or objects, rather than functions and logic. An object can be defined as a data field that has unique attributes and behavior.
OOP focuses on the objects that developers want to manipulate rather than the logic required to manipulate them. This approach to programming is well-suited for programs that are large, complex and actively updated or maintained. This includes programs for manufacturing and design, as well as mobile applications; for example, OOP can be used for manufacturing system simulation software.
The organization of an object-oriented program also makes the method beneficial to collaborative development, where projects are divided into groups. Additional benefits of OOP include code reusability, scalability and efficiency.
The first step in OOP is to collect all of the objects a programmer wants to manipulate and identify how they relate to each other — an exercise known as data modeling.
Examples of an object can range from physical entities, such as a human being who is described by properties like name and address, to small computer programs, such as widgets.
Once an object is known, it is labeled with a class of objects that defines the kind of data it contains and any logic sequences that can manipulate it. Each distinct logic sequence is known as a method. Objects can communicate with well-defined interfaces called messages.
What is the structure of object-oriented programming?
The structure, or building blocks, of object-oriented programming include the following:
- Classes are user-defined data types that act as the blueprint for individual objects, attributes and methods.
- Objects are instances of a class created with specifically defined data. Objects can correspond to real-world objects or an abstract entity. When class is defined initially, the description is the only object that is defined.
- Methods are functions that are defined inside a class that describe the behaviors of an object. Each method contained in class definitions starts with a reference to an instance object. Additionally, the subroutines contained in an object are called instance methods. Programmers use methods for reusability or keeping functionality encapsulated inside one object at a time.
- Attributes are defined in the class template and represent the state of an object. Objects will have data stored in the attributes field. Class attributes belong to the class itself.
What are the main principles of OOP?
Object-oriented programming is based on the following principles:
- Encapsulation: This principle states that all important information is contained inside an object and only select information is exposed. The implementation and state of each object are privately held inside a defined class. Other objects do not have access to this class or the authority to make changes. They are only able to call a list of public functions or methods. This characteristic of data hiding provides greater program security and avoids unintended data corruption.
- Abstraction: Objects only reveal internal mechanisms that are relevant for the use of other objects, hiding any unnecessary implementation code. The derived class can have its functionality extended. This concept can help developers more easily make additional changes or additions over time.
- Inheritance: Classes can reuse code from other classes. Relationships and subclasses between objects can be assigned, enabling developers to reuse common logic while still maintaining a unique hierarchy. This property of OOP forces a more thorough data analysis, reduces development time and ensures a higher level of accuracy.
- Polymorphism: Objects are designed to share behaviors and they can take on more than one form. The program will determine which meaning or usage is necessary for each execution of that object from a parent class, reducing the need to duplicate code. A child class is then created, which extends the functionality of the parent class. Polymorphism allows different types of objects to pass through the same interface.
What are examples of object-oriented programming languages?
While Simula is credited as being the first object-oriented programming language, many other programming languages are used with OOP today. But some programming languages pair with OOP better than others. For example, programming languages considered pure OOP languages treat everything as objects. Other programming languages are designed primarily for OOP, but with some procedural processes included.
For example, popular pure OOP languages include:
- Ruby
- Scala
- JADE
- Emerald
Programming languages designed primarily for OOP include:
- Java
- Python
- C++
Other programming languages that pair with OOP include:
- Visual Basic .NET
- PHP
- JavaScript
What are the benefits of OOP?
Benefits of OOP include:
- Modularity: Encapsulation enables objects to be self-contained, making troubleshooting and collaborative development easier.
- Reusability: Code can be reused through inheritance, meaning a team does not have to write the same code multiple times.
- Productivity: Programmers can construct new programs quicker through the use of multiple libraries and reusable code.
- Easily upgradable and scalable: Programmers can implement system functionalities independently.
- Interface descriptions: Descriptions of external systems are simple, due to message passing techniques that are used for objects communication.
- Security: Using encapsulation and abstraction, complex code is hidden, software maintenance is easier and internet protocols are protected.
- Flexibility: Polymorphism enables a single function to adapt to the class it is placed in. Different objects can also pass through the same interface.
Criticism of OOP
The object-oriented programming model has been criticized by developers for multiple reasons. The largest concern is that OOP overemphasizes the data component of software development and does not focus enough on computation or algorithms. Additionally, OOP code may be more complicated to write and take longer to compile.
Alternative methods to OOP include:
- Functional programming: This includes languages such as Erlang and Scala, which are used for telecommunications and fault tolerant systems.
- Structured or modular programming: This includes languages such as PHP and C#.
- Imperative programming: This alternative to OOP focuses on function rather than models and includes C++ and Java.
- Declarative programming: This programming method involves statements on what the task or desired outcome is but not how to achieve it. Languages include Prolog and Lisp.
- Logical programming: This method, which is based mostly in formal logic and uses languages such as Prolog, contains a set of sentences that express facts or rules about a problem domain. It focuses on tasks that can benefit from rule-based logical queries.
Most advanced programming languages enable developers to combine models, because they can be used for different programming methods. For example, JavaScript can be used for OOP and functional programming.
What is Computer Forensics (Cyber Forensics)?
Computer forensics is the application of investigation and analysis techniques to gather and preserve evidence from a particular computing device in a way that is suitable for presentation in a court of law. The goal of computer forensics is to perform a structured investigation and maintain a documented chain of evidence to find out exactly what happened on a computing device and who was responsible for it.
Computer forensics — which is sometimes referred to as computer forensic science — essentially is data recovery with legal compliance guidelines to make the information admissible in legal proceedings. The terms digital forensics and cyber forensics are often used as synonyms for computer forensics.
Digital forensics starts with the collection of information in a way that maintains its integrity. Investigators then analyze the data or system to determine if it was changed, how it was changed and who made the changes. The use of computer forensics isn’t always tied to a crime. The forensic process is also used as part of data recovery processes to gather data from a crashed server, failed drive, reformatted operating system (OS) or other situation where a system has unexpectedly stopped working.
Why is computer forensics important?
In the civil and criminal justice system, computer forensics helps ensure the integrity of digital evidence presented in court cases. As computers and other data-collecting devices are used more frequently in every aspect of life, digital evidence — and the forensic process used to collect, preserve and investigate it — has become more important in solving crimes and other legal issues.
The average person never sees much of the information modern devices collect. For instance, the computers in cars continually collect information on when a driver brakes, shifts and changes speed without the driver being aware. However, this information can prove critical in solving a legal matter or a crime, and computer forensics often plays a role in identifying and preserving that information.
Digital evidence isn’t just useful in solving digital-world crimes, such as data theft, network breaches and illicit online transactions. It’s also used to solve physical-world crimes, such as burglary, assault, hit-and-run accidents and murder.
Businesses often use a multilayered data management, data governance and network security strategy to keep proprietary information secure. Having data that’s well managed and safe can help streamline the forensic process should that data ever come under investigation.
Businesses also use computer forensics to track information related to a system or network compromise, which can be used to identify and prosecute cyber attackers. Businesses can also use digital forensic experts and processes to help them with data recovery in the event of a system or network failure caused by a natural or other disaster.
As the world becomes more reliant on digital technology for the core functions of life, cybercrime is rising. As such, computer forensic specialists no longer have a monopoly on the field.
Six foundations of strong infosec:
- Recongnize that information security is not just the CIO’s job.
- Treat-and protect-data and information as business assets.
- Protect important data on removable media and mobile devices
- Know where your organization’s important digital assets are located.
- Recognize that not every dat breach occurs because of an external attack. Employees can also cause data breaches intentionally or inadvertently.
- Reliaze that meeting legislative and regulatory standards is just the starting point for an infosec strategy.
Types of computer forensics
There are various types of computer forensic examinations. Each deals with a specific aspect of information technology. Some of the main types include the following:
- Database forensics: The examination of information contained in databases, both data and related metadata.
- Email forensics: The recovery and analysis of emails and other information contained in email platforms, such as schedules and contacts.
- Malware forensics: Sifting through code to identify possible malicious programs and analyzing their payload. Such programs may include Trojan horses, ransomware or various viruses.
- Memory forensics: Collecting information stored in a computer’s random access memory (RAM) and cache.
- Mobile forensics: The examination of mobile devices to retrieve and analyze the information they contain, including contacts, incoming and outgoing text messages, pictures and video files.
- Network forensics: Looking for evidence by monitoring network traffic, using tools such as a firewall or intrusion detection system.
How does computer forensics work?
Forensic investigators typically follow standard procedures, which vary depending on the context of the forensic investigation, the device being investigated or the information investigators are looking for. In general, these procedures include the following three steps:
- Data collection: Electronically stored information must be collected in a way that maintains its integrity. This often involves physically isolating the device under investigation to ensure it cannot be accidentally contaminated or tampered with. Examiners make a digital copy, also called a forensic image, of the device’s storage media, and then they lock the original device in a safe or other secure facility to maintain its pristine condition. The investigation is conducted on the digital copy. In other cases, publicly available information may be used for forensic purposes, such as Facebook posts or public Venmo charges for purchasing illegal products or services displayed on the Vicemo website.
- Analysis: Investigators analyze digital copies of storage media in a sterile environment to gather the information for a case. Various tools are used to assist in this process, including Basis Technology’s Autopsy for hard drive investigations and the Wireshark network protocol analyzer. A mouse jiggler is useful when examining a computer to keep it from falling asleep and losing volatile memory data that is lost when the computer goes to sleep or loses power.
- Presentation: The forensic investigators present their findings in a legal proceeding, where a judge or jury uses them to help determine the result of a lawsuit. In a data recovery situation, forensic investigators present what they were able to recover from a compromised system.
Often, multiple tools are used in computer forensic investigations to validate the results they produce.
Techniques forensic investigators use
Investigators use a variety of techniques and proprietary forensic applications to examine the copy they’ve made of a compromised device. They search hidden folders and unallocated disk space for copies of deleted, encrypted or damaged files. Any evidence found on the digital copy is carefully documented in a finding report and verified with the original device in preparation for legal proceedings that involve discovery, depositions or actual litigation.
Computer forensic investigations use a combination of techniques and expert knowledge. Some common techniques include the following:
- Reverse steganography: Steganography is a common tactic used to hide data inside any type of digital file, message or data stream. Computer forensic experts reverse a steganography attempt by analyzing the data hashing that the file in question contains. If a cybercriminal hides important information inside an image or other digital file, it may look the same before and after to the untrained eye, but the underlying hash or string of data that represents the image will change.
- Stochastic forensics: Here, investigators analyze and reconstruct digital activity without the use of digital artifacts. Artifacts are unintended alterations of data that occur from digital processes. Artifacts include clues related to a digital crime, such as changes to file attributes during data theft. Stochastic forensics is frequently used in data breach investigations where the attacker is thought to be an insider, who might not leave behind digital artifacts.
- Cross-drive analysis: This technique correlates and cross-references information found on multiple computer drives to search for, analyze and preserve information relevant to an investigation. Events that raise suspicion are compared with information on other drives to look for similarities and provide context. This is also known as anomaly detection.
- Live analysis: With this technique, a computer is analyzed from within the OS while the computer or device is running, using system tools on the computer. The analysis looks at volatile data, which is often stored in cache or RAM. Many tools used to extract volatile data require the computer in to be in a forensic lab to maintain the legitimacy of a chain of evidence.
- Deleted file recovery: This technique involves searching a computer system and memory for fragments of files that were partially deleted in one place but leave traces elsewhere on the machine. This is sometimes known as file carving or data carving.
How is computer forensics used as evidence?
Computer forensics has been used as evidence by law enforcement agencies and in criminal and civil law since the 1980s. Some notable cases include the following:
- Apple trade secret theft: An engineer named Xiaolang Zhang at Apple’s autonomous car division announced his retirement and said he would be moving back to China to take care of his elderly mother. He told his manager he planned to work at an electronic car manufacturer in China, raising suspicion. According to a Federal Bureau of Investigation (FBI) affidavit, Apple’s security team reviewed Zhang’s activity on the company network and found, in the days prior to his resignation, he downloaded trade secrets from confidential company databases to which he had access. He was indicted by the FBI in 2018.
- Enron: In one of the most commonly cited accounting fraud scandals, Enron, a U.S. energy, commodities and services company, falsely reported billions of dollars in revenue before going bankrupt in 2001, causing financial harm to many employees and other people who had invested in the company. Computer forensic analysts examined terabytes of data to understand the complex fraud scheme. The scandal was a significant factor in the passing of the Sarbanes-Oxley Act of 2002, which set new accounting compliance requirements for public companies. The company declared bankruptcy in 2001.
- Google trade secret theft: Anthony Scott Levandowski, a former executive of both Uber and Google, was charged with 33 counts of trade secret theft in 2019. From 2009 to 2016, Levandowski worked in Google’s self-driving car program, where he downloaded thousands of files related to the program from a password-protected corporate server. He departed from Google and created Otto, a self-driving truck company, which Uber bought in 2016, according to The New York Times. Levandowski plead guilty to one count of trade secrets theft and was sentenced to 18 months in prison and $851,499 in fines and restitution. Levandowski received a presidential pardon in January 2021.
- Larry Thomas: Thomas shot and killed Rito Llamas-Juarez in 2016 Thomas was later convicted with the help of hundreds of Facebook posts he made under the fake name of Slaughtaboi Larro. One of the posts included a picture of him wearing a bracelet that was found at the crime scene.
- Michael Jackson: Investigators used metadata and medical documents from Michael Jackson’s doctor’s iPhone that showed the doctor, Conrad Murray, prescribed lethal amounts of medication to Jackson, who died in 2009.
- Mikayla Munn: Munn drowned her newborn baby in the bathtub of her Manchester University dorm room in 2016. Investigators found Google searches on her computer containing the phrase “at home abortion,” which were used to convict her.
Computer forensics careers and certifications
Computer forensics has become its own area of scientific expertise, with accompanying coursework and certification. The average annual salary for an entry-level computer forensic analyst is about $65,000, according to Salary.com. Some examples of cyber forensic career paths include the following:
- Forensic engineer: These professionals deal with the collection stage of the computer forensic process, gathering data and preparing it for analysis. They help determine how a device failed.
- Forensic accountant: This position deals with crimes involving money laundering and other transactions made to cover up illegal activity.
- Cybersecurity analyst: This position deals with analyzing data once it has been collected and drawing insights that can later be used to improve an organization’s cybersecurity strategy.
A bachelor’s degree — and, sometimes, a master’s degree — in computer science, cybersecurity or a related field are required of computer forensic professionals. There are several certifications available in this field, including the following:
- CyberSecurity Institute’s CyberSecurity Forensic Analyst: This credential is designed for security professionals with at least two years of experience. Testing scenarios are based on actual cases.
- International Association of Computer Investigative Specialists’ Certified Forensic Computer Examiner: This program focuses primarily on validating the skills necessary to ensure business follows established computer forensic guidelines.
- EC-Council’s Computer Hacking Forensic Investigator: This certification assesses an applicant’s ability to identify intruders and collect evidence that can be used in court. It covers search and seizure of information systems, working with digital proof and other cyber forensics skills.
- International Society of Forensic Computer Examiners’ (ISFCE) Certified Computer Examiner: This forensic examiner program requires training at an authorized bootcamp training center, and applicants must sign the ISFCE Code of Ethics and Professional Responsibility.
“While the work of all information security professionals is important, those working in the field of cybersecurity forensics play an especially pivotal role in the attribution of cyberattacks and the apprehension of perpetrators.” – Ed Tittel
Related Terms: Trojan horse, intrusion detection system, steganography, forensic image, cybercrime
Why are companies paying so much for AI professionals?
Professionals involved in working on artificial intelligence (AI) technologies have been making a lot of money for a while. The reasons for the current explosion in the salaries of these tech-savvy employees have to do with some trends and developments that have been happening for at least a decade, and some others that are more recent.
One of the biggest reasons for large AI salaries is simply the equation around supply and demand. Since the talent pool is relatively small, it has created what some call a “pay-to-play hiring environment.” Although recent reports show AI salaries in line with some other kinds of technology positions, experts suggest that may not be the real picture, because companies have to pay a premium to get good people on board for specialized AI projects.
There’s also the general need for digital transformation which is driving AI demand. Even before the remote and virtual boom of the pandemic, digital sea changes were pushing up the salaries of people who could boast skills and experience related to digitizing and distributing workflows or services. However, with the new demand for remote work models in recent years, that demand for digitized environments has only increased in a big way.
Another factor pointed out by some experts in the industry is that the transparency of remote systems shows AI professionals how highly they are valued, and leads to more universal salary increases. That’s one reason why recent surveys have found increases in AI salaries in every region of the country, and in various types of industries where people are applying AI solutions.
Finally, there’s the evident reality that AI work requires specific specializations and skills. This is the opposite of unskilled labor that is freely transmittable to different pools of people. The unique nature of an AI professional who can effectively move the ball forward is another pillar of the purchasing power and labor value that these individuals have in the market.
Some of the skills and experience needed are significantly abstract to the point that it can be difficult to really value what an individual offers. The idea of the “10x programmer” or rare unicorn IT wizard is relevant here. What’s less debatable is that an individual with significant coding skills, knowledge of machine learning algorithms and the mathematical background to handle progress in this field is worth significant amounts of money compared to any other kind of skilled labor in a modern economy.
What is Flash Storage?
Flash storage describes any type of long-term storage repository supported by flash memory. Flash storage may also be referred to as solid state storage.
Unlike traditional hard disk drive storage, flash storage has no mechanical parts which makes it a good choice for storage in mobile technology. Flash storage comes in a variety of formats and prices, ranging from inexpensive consumer-grade USB drives to enterprise-level all flash arrays.
Flash storage makes use of flash memory, which stores data in an array of memory cells. The cells can range from traditional single cell to multi-level cells.
Compared to hard drives, flash storage drives provides many advantages, including faster read and write times. Flash memory’s quick access to stored data and fast processing capabilities makes it more business-friendly than traditional storage options.
Because Flash can handle large workloads more efficiently than traditional mechanical storage, it’s a good choice for working with complex data sets and multi-step, distributed operations in the cloud. When compared to hard drive use, flash storage does not require as much power and does not generate as much heat, which can result in reduced energy costs.
Although flash storage for enterprise use has come down in price in recent years, it is still more more expensive than traditional hard drive storage. Another limitation to consider is that flash memory has a limited number of write/erase cycles (PE cycles) before wearing out, so depending on its use, a flash drive’s lifespan may not be as long as a mechanical hard drive.
What is Recurrent Neural Networks (RNN)?
A recurrent neural network is a type of artificial neural network commonly used in speech recognition and natural language processing. Recurrent neural networks recognize data’s sequential characteristics and use patterns to predict the next likely scenario.
RNNs are used in deep learning and in the development of models that simulate neuron activity in the human brain. They are especially powerful in use cases where context is critical to predicting an outcome, and are also distinct from other types of artificial neural networks because they use feedback loops to process a sequence of data that informs the final output. These feedback loops allow information to persist. This effect often is described as memory.
RNN use cases tend to be connected to language models in which knowing the next letter in a word or the next word in a sentence is predicated on the data that comes before it. A compelling experiment involves an RNN trained with the works of Shakespeare to produce Shakespeare-like prose successfully. Writing by RNNs is a form of computational creativity. This simulation of human creativity is made possible by the AI’s understanding of grammar and semantics learned from its training set.
The deep learning process:
- Understand problems and whether deep learning is a good fit.
- Identifies relevant data sets and prepares them for analysis.
- Choosees the type of deep learning algorithm to use.
- Trains algorithm on large amount of labeled data.
- Tests the model’s performance against unlabeled data.
How recurrent neural networks learn?
Artificial neural networks are created with interconnected data processing components that are loosely designed to function like the human brain. They are composed of layers of artificial neurons — network nodes — that have the ability to process input and forward output to other nodes in the network. The nodes are connected by edges or weights that influence a signal’s strength and the network’s ultimate output.
In some cases, artificial neural networks process information in a single direction from input to output. These “feed-forward” neural networks include convolutional neural networks that underpin image recognition systems. RNNs, on the other hand, can be layered to process information in two directions.
Like feed-forward neural networks, RNNs can process data from initial input to final output. Unlike feed-forward neural networks, RNNs use feedback loops, such as backpropagation through time, throughout the computational process to loop information back into the network. This connects inputs and is what enables RNNs to process sequential and temporal data.
A truncated backpropagation through time neural network is an RNN in which the number of time steps in the input sequence is limited by a truncation of the input sequence. This is useful for recurrent neural networks that are used as sequence-to-sequence models, where the number of steps in the input sequence (or the number of time steps in the input sequence) is greater than the number of steps in the output sequence.
Bidirectional recurrent neural networks (BRNNs)
Bidirectional recurrent neural networks (BRNNs) are another type of RNN that simultaneously learn the forward and backward directions of information flow. This is different from standard RNNs, which only learn information in one direction. The process of both directions being learned simultaneously is known as bidirectional information flow.
In a typical artificial neural network, the forward projections are used to predict the future, and the backward projections are used to evaluate the past. They are not used together, however, as in a BRNN.
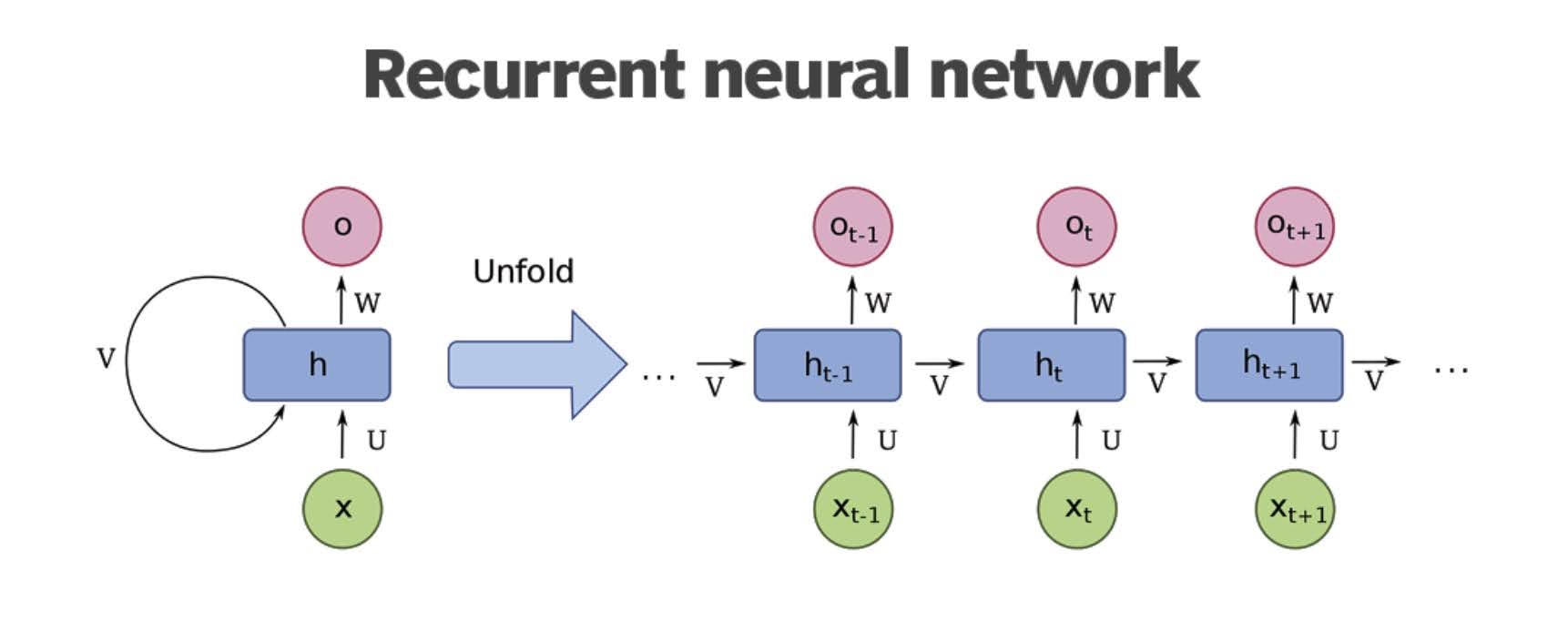
RNN challenges and how to solve them?
The most common issues with RNNS are gradient vanishing and exploding problems. The gradients refer to the errors made as the neural network trains. If the gradients start to explode, the neural network will become unstable and unable to learn from training data.
Long short-term memory units
One drawback to standard RNNs is the vanishing gradient problem, in which the performance of the neural network suffers because it can’t be trained properly. This happens with deeply layered neural networks, which are used to process complex data.
Standard RNNs that use a gradient-based learning method degrade as they grow bigger and more complex. Tuning the parameters effectively at the earliest layers becomes too time-consuming and computationally expensive.
One solution to the problem is called long short-term memory (LSTM) networks, which computer scientists Sepp Hochreiter and Jurgen Schmidhuber invented in 1997. RNNs built with LSTM units categorize data into short-term and long-term memory cells. Doing so enables RNNs to figure out which data is important and should be remembered and looped back into the network. It also enables RNNs to figure out what data can be forgotten.
Gated recurrent units (GRUs)
Gated recurrent units (GRUs) are a form of recurrent neural network unit that can be used to model sequential data. While LSTM networks can also be used to model sequential data, they are weaker than standard feed-forward networks. By using an LSTM and a GRU together, networks can take advantage of the strengths of both units — the ability to learn long-term associations for the LSTM and the ability to learn from short-term patterns for the GRU.
Multilayer perceptrons (MLPs) and convolutional neural networks
The other two types of classes of artificial neural networks include multilayer perceptrons (MLPs) and convolutional neural networks.
MLPs consist of several neurons arranged in layers and are often used for classification and regression. A perceptron is an algorithm that can learn to perform a binary classification task. A single perceptron cannot modify its own structure, so they are often stacked together in layers, where one layer learns to recognize smaller and more specific features of the data set.
The neurons in different layers are connected to each other. For example, the output of the first neuron is connected to the input of the second neuron, which acts as a filter. MLPs are used to supervise learning and for applications such as optical character recognition, speech recognition and machine translation.
Convolutional neural networks, also known as CNNs, are a family of neural networks used in computer vision. The term “convolutional” refers to the convolution — the process of combining the result of a function with the process of computing/calculating it — of the input image with the filters in the network. The idea is to extract properties or features from the image. These properties can then be used for applications such as object recognition or detection.
| Convolutional neural network (CNN) | Recurrent neural network (RNN) | |
|---|---|---|
| Architecture | Feed-forward neural networks using filters and pooling | Recurring network that feeds the results back into the network |
| Input/Output | The size of the input and the resulting output is fixed (i.e., receives images of fixed size and outputs them to the appropriate category along with the confidence level of its prediction) | The size of the input and the resulting output may vary (i.e., receives the different text and output translations – the resulting sentences can have more or fewer words) |
| Ideal usage scenario | Spatial data (such as images) | Temporal/sequential data (such as text or video) |
| Use cases | Image recognition and classification, face detection, medical analysis, drug discovery, and image analysis | Text translation, natural language processing, language translation, entity extraction, conversational intelligence, sentiment analysis, speech analysis |
CNNs are created through a process of training, which is the key difference between CNNs and other neural network types. A CNN is made up of multiple layers of neurons, and each layer of neurons is responsible for one specific task. The first layer of neurons might be responsible for identifying general features of an image, such as its contents (e.g., a dog). The next layer of neurons might identify more specific features (e.g., the dog’s breed).
What is Software as a Service (SaaS)?
Software as a service (SaaS) is a software distribution model that delivers application programs over the Internet. End users can access SaaS cloud apps with a web browser. The SaaS provider is responsible for hosting and maintaining the application throughout its lifecycle.
Advantages to using the SaaS delivery model include:
- Clients can easily access the software from multiple computing devices.
- Updates and patches can be applied automatically without client assistance.
- Application access, as well as storage to support application use, can be sold on a subscription basis.
SaaS is also known as hosted software or on-demand software.
SaaS is a natural evolution of software. The old model of physically installing software on data center servers and end user’s computing devices was the only realistic solution for many years.
In recent years, a number of developments have allowed SaaS to become mainstream. One factor is bandwidth; the internet is simply faster than it was a decade ago and access is more widely available. Another major factor has been the growing acceptance of cloud computing for business use.
Today, SaaS is used in a number of core business areas, including customer relationship experience management, human resource (HR) management and document management. There are literally thousands of SaaS vendors, but Salesforce.com is perhaps the best known example, as it was one of the independent software vendors to significantly disrupt a traditional software vertical by changing the delivery model.
What is RAID 10 (RAID 1+0)?
RAID 10, also known as RAID 1+0, is a RAID configuration that combines disk mirroring and disk striping to protect data. It requires a minimum of four disks and stripes data across mirrored pairs. As long as one disk in each mirrored pair is functional, data can be retrieved. If two disks in the same mirrored pair fail, all data will be lost because there is no parity in the striped sets.
RAID, which stands for redundant array of independent disks, comes in several different configurations. A RAID 1 configuration copies data from one drive to another, mirroring and duplicating data to provide improved fault tolerance and data protection. Data is fully protected as the mirror copy is available if the originating drive is disabled or unavailable. Because it makes a full duplicate of the data, RAID 1 requires twice as much storage capacity as the original data.
RAID 0 doesn’t provide any data protection; its sole purpose is to enhance drive access performance. It does that by spreading the data out across two or more drives. That way multiple read/write heads on the drives can write or access portions of data simultaneously, thus speeding up overall processing.
RAID 10 provides data redundancy and improves performance. It is the a good option for I/O-intensive applications — including email, web servers, databases and operations that require high disk performance. It’s also good for organizations that require little to no downtime.
The high performance of RAID 10, and its ability to speed up both write and read activities, makes it suited to frequently used, mission-critical database servers. However, the four-disk minimum requirement makes RAID 10 a costly choice for smaller computing environments. That 100% storage capacity overhead may be overkill for small businesses and consumer use.
How it differs from other forms of RAID?
The two-number format of RAID 10/1+0 is known as a nested RAID configuration because it combines two RAID levels to enhance performance. Other nested RAID levels are:
- 01/0+1
- 03/0+3
- 50/5+0
- 60/6+0
- 100/10+0
While RAID 1+0 is similar to RAID 0+1, the reversed order of the numbers indicates the two RAID levels are layered in the opposite order. RAID 1+0 mirrors two drives together and then creates a striped set with the pair. RAID 0+1 creates two stripe sets and then mirrors them. While both RAID levels use the same number of drives, they are not synonymous.
| Level | Description |
|---|---|
| RAID 01 (RAID 0 + RAID 1) | Same capacity as RAID 1 RAID 0 mirrored Can replicate and share data between disks Requires a minimum of four disks |
| RAID 03 (RAID 0 + RAID 3) | Similar to RAID 01 Uses striping with dedicated parity instead of mirroring Sometimes called RAID 53 Requires a minimum of six disks |
| RAID 10 (RAID 1 + RAID 0) | RAID 1 striped Generally implemented by RAID controllers Improves write performance Requires a minimum of four disks |
| RAID 50 (RAID 5 + RAID 0) | Block-level striping of RAID 0 with distributed parity of RAID 5 Provides better fault tolerance Improves write performance of RAID 5 Requires a minimum of six disks |
| RAID 60 (RAID 6 + RAID 0) | Block-level striping of RAID 0 with distributed double parity of RAID 6 RAID 0 striped across RAID 6 elements Requires a minimum of eight disks |
| RAID 100 (RAID 10 + RAID 0) | Striped of RAID 10s Generally implemented with software RAID 0 Also called plaid RAID because it is striped two ways Requires a minimum of six disks |
What are the advantages of Disk mirroring’s data protection?
Mirroring is the simplest way to ensure data protection. It creates a full, intact copy of all active data. When an original drive or set of drives fails, the user simply switches to the mirrored devices to regain full access to the data. The switch to the mirrored drives is nearly instantaneous, so any disruptions to normal operations will be limited.
Other RAID levels use a parity-based scheme to protect the data. With parity, a failed drive is rebuilt using the data from the surviving drives in the set along with the parity information. If there is a lot of data on the drive array supporting parity RAID, the rebuild can take hours — or even days. During the rebuild process, data in the RAID system will not be available.
According to manufacturer specifications and independent benchmarks, RAID 10 provides lower latency and superior throughput compared with all other RAID levels, except for RAID 0.
The 100% storage capacity overhead that disk mirroring requires means if 20 TB is installed in a RAID 10 environment, only 10 TB of disk space is available for live data, with the other 10 TB reserved for the mirror copy. This drive capacity penalty is much higher than RAID levels that don’t use mirroring.
Because of this capacity penalty, levels such as RAID 5, 50 (5+0) and 6 may be considered as alternatives. However, when rebuilding with RAID 10, only the surviving mirror of all the drives is read, while non-mirroring levels require all remaining drives to be read. The heavier lifting required by RAID 5, 50 and 6 could therefore result in a higher risk of failure and data loss.
RAID 6 stripes data and calculates parity two times, storing these results in different areas of the disk. This can help protect against two simultaneous disk failures, but the compute power needed to make two parity calculations for every write operation slows RAID 6 significantly.
JBOD, or just a bunch of disks, may also be considered as an alternative to RAID 10. JBOD does not use striping or parity, but it can treat multiple disks as one entity and combine their capacity. While JBOD can be less expensive than RAID, it has few other advantages. The lack of redundancy with a JBOD arrangement uses all available drive capacity but puts data at higher risk of corruption.
Generally, read/write operations on RAID arrays are faster, and data streams can be divided and stored concurrently. JBOD data can only be stored on one disk at a time.
Advanced data mirroring
Disk mirroring duplicates data to multiple hard drives connected to a single controller. It is a form of backup used in some RAID arrays and can be hardware- or software-based.
Unlike RAID 0 and RAID 1, RAID 1+0 combines striping and mirroring to create redundancy. As long as an array has an even number of hard disk drives, these two actions can be used together. While mirroring can reduce the amount of available capacity in a RAID 1+0 array, it creates another layer of protection against data loss.
With data mirroring, RAID 10 arrays can maintain multiple copies of data, allowing for a quicker recovery in the event of a failure. By striping mirrored data, RAID 10 combines the speed boost of striping with the added redundancy of mirroring.
Comparing between Hardware RAID and software RAID
RAID 10, like all other RAID levels, can be deployed using hardware or software. Hardware RAID requires a RAID controller inside a motherboard slot that connects the drives. Software RAID uses a utility application to manage the RAID configuration.
Hardware RAID often costs more than a software option, but it can have superior performance. This approach can sometimes replace disks without shutting down the server, a practice known as hot swapping. With hardware RAID, higher write throughput speeds are supported, as well as faster recovery of lost data. Because of this, hardware RAID is the preferred option when dealing with essential servers.
Software RAID is less expensive and less complex to deploy. Most operating systems include software RAID support. However, while hardware RAID is likely to provide a battery backup in case of power failure, software RAID does not. Small businesses prefer software RAID because it offers higher performance in standard RAID levels. Software RAID does not offer nested levels like RAID 10.
RAID 10 with SSD
While RAID was created for hard disk drives, there are some RAID levels — such as RAID 5, 6 and 10 — that can be used on solid-state drives (SSDs). For example, RAID 10’s method of striping mirrored sets can be beneficial in a flash system. However, the majority of traditional RAID levels are not optimized for flash environments.
Write-heavy RAID levels like 5 and 6 may cause latency and performance problems when used with SSDs. Because each write on a flash drive requires an erase and erase cycles are limited on SSDs, the additional writes created by RAID 5 and 6 can seriously affect flash performance.
The higher cost of requiring 100% drive capacity overhead applies when using solid-state storage versus magnetic media, and it is exacerbated given the higher cost of solid-state storage. Already more expensive than other forms of RAID, the cost of using SSDs with RAID 10 may deter consumers. However, the cost of flash has been declining, so a RAID 10 scheme using solid-state storage may become a more attractive option over time.
What are the advantages of RAID 10?
The advantages of RAID 10 include the following:
- Cost-effective: RAID 10 is an economical and technically simple approach to data protection paired with a boost in performance.
- Full redundancy: Data is fully redundant in a RAID 10 environment.
- Fast recovery: Because it does not rely on parity to rebuild any data elements lost during a drive failure or disk fails, recovering data in a RAID 10 array is fast, resulting in little downtime.
- Performance boost for some applications: RAID 10’s basic data striping is an effective way to improve performance for applications that don’t require large amounts of data.
What are the drawbacks of RAID 10?
Some of the disadvantages of RAID 10 include these:
- Large capacity penalty: Because RAID 10 requires 100% capacity overhead, it is not an ideal RAID implementation for large amounts of data. The capacity penalty for other forms of RAID — notably those that are parity based — is much smaller.
- Limited scalability: RAID 10 is an effective alternative for smaller applications, but it doesn’t scale well.
- Time-consuming recovery: If a disk array has to switch over to the mirror drives, a new mirror must be created as soon as possible to ensure continuous data protection. Copying all the original data to a new drive or set of drives can be time-consuming and may hinder ongoing operations that rely on the data.
Considerations for using RAID 10
While RAID 10 writes to two disks at once, it should not be considered a replacement for traditional data backup. If the operating system is corrupted, the data on both disks is at risk of corruption. Given that possibility, RAID should not be considered the last line of defense against data loss. RAID 10 can protect against single drive (or drive set) failures, but a secure data backup plan should also be in place.
The faster rebuild times and features like hot swapping disks make RAID 10 an appealing option. However, its reduced capacity will likely make it a feasible alternative only for smaller applications or environments.
To decide whether to use RAID 10, consider the following four questions:
- What is my budget?
- How much storage capacity do I need?
- What are my read/write performance requirements?
- How much rebuild and recovery time can I afford?
What is Ransomware?
Ransomware is a type of malware programming that infects, locks or takes control of a system. The attacker then requests a financial payment to undo the malicious action.
Ransomware attackers typically encrypt files and demand digital currency in exchange for the correct decryption key. The attacker may threaten to leak exfiltrated data to the public or post it for sale on the dark web if the ransom is not paid.
Ransomware is distributed through malicious email attachments, infected downloads and compromised websites. The attacker will typically demand payment in a specific cryptocurrency, such as Bitcoin, to avoid detection through conventional follow-the-money tracing methods used by law enforcement.
Ransomware may also be referred to as a crypto-virus, crypto-Trojan or crypto-worm.
Ransomware attacks can severely impact businesses and leave hospitals and municipalities without the data they need to operate and deliver mission-critical services. According to the FBI, ransomware incidents continue to rise in 2021, but their financial impact is still dwarfed by cyberattacks that focus on business email compromise (BEC) and email account attacks.
Ransomware as a Service
A ransomware variant from the DarkSide cybercrime group is one of more than 100 ransomware variants that the FBI is currently investigating. DarkSide has been in the news for offering ransomware as a service (RaaS) partnerships to non-technical criminal affiliates who are willing to share a percentage of the paid ransom with the developers.
How to prevent Ransomware?
To prevent the negative consequences of a ransomware attack, the Cybersecurity and Infrastructure Security Agency (CISA) recommends the following best practices:
- Maintain offline, encrypted backups of data and continually test recovery point objectives.
- Regularly patch and update all software and firmware.
- Conduct vulnerability scans on a regular basis to limit potential attack surfaces.
- Ensure computing devices are configured properly and that security features are enabled.
- Follow best practices for remote desktop and print services.
- Take advantage of intrusion detection system (IDS) that can detect command and control (C&C) signals and other malicious network activity that often occurs prior to an attack.
- Proactively create an incident response plan that includes notification procedures.
What is Commodore?
Commodore was a collection of companies that provided many of the first high-tech products to the American market as personal and home computers and devices became more sophisticated throughout the 1970s and 1980s. Founded by entrepreneur and Holocaust survivor Jack Tramiel in 1955, Commodore sold successive generations of home computers as well as video game consoles.
After pioneering the PET microcomputer in the late 1970s, Commodore continued to innovate with a series of VIC-branded computers offering color graphics, competitive RAM, and modem capabilities. The Commodore 64, named for its 64 KB of RAM, was also a best-selling computer, followed by the Commodore Amiga in 1985. A subsidiary called Commodore Business Machines also produced a line of computers specifically for commercial use.
In addition to developing computers, Commodore also developed video game systems, notably, the Commodore 64 video game console. These were also prominent Commodore-branded products. Eventually, the video game industry weakened, and Commodore lost ground to IBM and Apple in the personal and business computer markets.
What is Cisco Certified Network Associate (CCNA)?
Cisco Certified Network Associate (CCNA) is a technical certification that Cisco offers for early-career networking professionals. It covers the following topics:
- network fundamentals
- network access
- Internet Protocol (IP) connectivity
- IP services
- security fundamentals
- automation and programmability
Cisco made significant changes to its exam structure on Feb. 24, 2020, putting a focus on simplifying it and making it more flexible. It also attempted to align the exam more closely with modern industry needs. Previously, Cisco offered several CCNAs for different networking specialties. The latest update consolidated those offerings into one CCNA certification, which is now the foundational certification for all Cisco-based career paths.
The 4 levels of Cisco certifications
Cisco offers one entry-level certification type, Cisco Certified Technician, which is available in three technology tracks: Collaboration, Data Center, and Routing and Switching. It is geared toward tech support roles and is not a prerequisite for CCNA or other higher-level certifications.
There are four levels in Cisco’s certification hierarchy:
- This level is a person who has been in a field for one or two years and is part of a team but not leading one.
- Information technology (IT) professionals at this level have more experience; they may be a senior member of a team or a team leader.
- At this level, a person has been in the networking field for several years and has developed skills in a specialized area.
- This level of certification validates an even higher level of experience, focusing on end-to-end IT skills from planning and designing to operating and optimizing network systems.
Exams are given at all four levels in three different areas of expertise: Engineering, Software and CyberOps.
Prior to the 2020 changes Cisco made to its certification program, CCNA was a prerequisite to all higher-level exams, like Cisco Certified Network Professional and Cisco Certified Internetwork Expert. This is no longer the case. Now, there are no specific prerequisites, and individuals can take exams when they feel ready. Cisco does provide recommendations on the level of expertise needed to pass specific exams, however.
CCNA continues to be a foundational certification that serves as a springboard to other certifications. It is a useful certification to have, no matter what a recipient chooses to focus on in the future.
What are the benefits of being CCNA-certified?
The main benefits of passing the CCNA exam include the following:
- Knowledge: Those passing the exam show they have a base level of knowledge about how to run a network.
- Skills: A person passing the CCNA exam gets in-depth practice in a range of tasks and skills.
- Credibility: With the CCNA certification on a resume, potential employers see that a candidate has validation from Cisco and is familiar with a breadth of Cisco networking products.
- Updating skills: Taking and passing the CCNA is valuable even for seasoned IT professionals, as it keeps them up to date on developments in networking.
- Pay: Attaining a new IT certification, on average, leads to a nearly $13,000 salary increase, according to Global Knowledge’s “2020 IT Skills and Salary Report.”
- Versatility: The U.S. Bureau of Labor Statistics projected that the demand for IT professionals is increasing. This makes CCNA a valuable certification to get, as it is adaptable to various IT career paths.
What are the prerequisites for CCNA certification?
According to Cisco, there are no formal prerequisites for the CCNA exam. However, Cisco recommends that CCNA candidates have the following:
- at least one year of using Cisco networking products
- basic IP addressing knowledge
- a solid understanding of the networking fundamentals
With the 2020 changes to Cisco’s exam program, CCNA and other exams were redesigned to mirror a natural career progression of a networking professional. Candidates can take an exam when they feel they are qualified.
How do you prepare for CCNA certification?
There are several online courses, free practice tests and books certification candidates can use to prepare for the CCNA exam.
Cisco offers a preparation course. The “Implementing and Administering Cisco Solutions (CCNA) v1.0” course provides experience with the skills needed to pass the exam and has lab scenarios for students to practice using Cisco networking technology.
Cisco also offers other resources through its Learning Network, including the following:
- access to a community of experts
- practice assessments and exams
- self-study and guided group study packages
One useful resource for the new CCNA is the CCNA 200-301 Official Cert Guide. This two-volume set provides a deep dive into all things CCNA, complete with practice questions. Author Wendell Odom provided his insider perspective on the new exam in this interview and explained why he thinks Cisco “did this particular exam right.”
How do you become CCNA-certified?
CCNA candidates must pass the Cisco 200-301 CCNA exam to be certified. The exam covers networking fundamentals, including the latest technologies, software development skills and professional roles. Passing it demonstrates that the test taker knows the basics of running a network.
Cisco administers exams through the Pearson VUE service. Prospective exam candidates should follow these four steps:
- Take advantage of Cisco’s and other organizations’ test prep courses and study materials.
- Log in at the Pearson VUE website.
- Register for the Cisco 200-301 exam, picking a time and location.
- Take the exam at a Pearson VUE test center or online.
Test takers learn if they passed the exam while at the testing center. If they pass the exam, they are CCNA-certified.
What types of questions does CCNA certification ask?
CCNA exams are proctored and timed, and they consist of written questions and answers, not labs. The exams include the following types of questions:
- multiple choice, single answer
- multiple choice, multiple answer
- drag and drop
- lablets, where tasks are performed on virtual machines
Below is an example of a single-answer, multiple-choice question about security fundamentals. It is not from an actual exam but rather is part of the CCNA curriculum and is in the style of the exam questions.
Question: Which command verifies whether any IPv6 access control lists are configured on a router?
- Show IPv6 access-list
- Show IPv6 interface
- Show access-list
- Show IPv6 route
Answer: Show IPv6 access-list
What is the recertification process for CCNA certification?
Cisco certification holders must recertify every three years, either by completing continuing education requirements or retaking the exam.
Passing the “Implementing and Administrating Cisco Solutions (CCNA) v1.0” course mentioned above earns course takers 30 continuing education credits and recertifies them for CCNA.
CCNA certifications earned before the 2020 changes remain valid until their expiration date.
What is Logarithm (LN)?
A logarithm (LN) is a concept in mathematics that denotes the number of times a number has to be multiplied by itself in order to arrive at a specified value. In mathematical terms, a logarithm of a number is the exponent that is used to raise another number, the base, in order to arrive at that number.
Logarithm is the reverse of the operation of exponentiation, which is raising a number according to a power. In exponentiation, a final value is determined after raising a base value with its exponent, while in logarithm, the final value and base are already known and the exponent is the value in question.
Logarithm is denoted as “logb (x) = r” or said as “the logarithm of x with respect to base b” or “the base-b logarithm of x,” where b is the base, x is the value and r is the logarithmic value or the exponent.
So for example, if 23 = 8 is expressed in exponentiation because 2 × 2 × 2 = 8, the inverse of that, which is the logarithm of 8 with respect to 2 is equal to 3, expressed as log2 8 = 3. They essentially have the same meaning but are expressed in a different manner and order.
Logarithm is used in scientific and mathematical calculations in order to depict perceived levels of measurable quantities such as electromagnetic field strength, visible light and sound energy.
What is Cloud Backup?
Cloud backup is a type of service through which cloud computing resources and infrastructure are used to create, edit, manage and restore data, services or application backup. This is done remotely over the internet.
Cloud backup may also be called online backup or remote backup.
Cloud backup is primarily used on an individual’s or organization’s data via an offsite and remote cloud storage platform. Cloud backup works when a cloud backup provider allocates cloud storage that is accessible globally over the Internet or backup software via a purpose-built user interface or vendor API. Cloud backup storage can be used to virtually store and back up all types of data or applications. Unlike traditional backup techniques, cloud backup is highly flexible and scalable in scaling up and down on run time.
Cloud backup is a managed service where the entire infrastructure and supporting services are managed completely by the vendor. Besides data backup, cloud backup is combined with disaster recovery solutions and may also provide an exact instance of a server, desktop or entire system.
What is Cloud Security Control?
Cloud security control is a set of controls that enables cloud architecture to provide protection against any vulnerability and mitigate or reduce the effect of a malicious attack. It is a broad term that consists of the all measures, practices and guidelines that must be implemented to protect a cloud computing environment.
Cloud security control primarily helps in addressing, evaluating and implementing security in the cloud. The Cloud Security Alliance (CSA) has created a Cloud Control Matrix (CCM), which is designed to help prospective cloud buyers evaluate a cloud solution’s overall security. Although there are limitless cloud security controls, they are similar to the standard information security controls and can be categorized in different domains including:
- Deterrent Controls: Don’t protect the cloud architecture/infrastructure/environment but serve as warning to a potential perpetrator of an attack.
- Preventative Controls: Used for managing, strengthening and protecting the vulnerabilities within a cloud.
- Corrective Controls: Help reduce the after-effects of an attack.
- Detective Controls: Used to identify or detect an attack.
What is NVMe over Fabrics (NVMe-oF)?
NVMe over Fabrics, also known as NVMe-oF and non-volatile memory express over fabrics, is a protocol specification designed to connect hosts to storage across a network fabric using the NVMe protocol.
The protocol is designed to enable data transfers between a host computer and a target solid-state storage device or system over a network — accomplished through a NVMe message-based command. Data transfers can be transferred through methods such as Ethernet, Fibre Channel (FC) or InfiniBand.
NVM Express Inc. is the nonprofit organization that published version 1.0 of the NVMe specification on March 1, 2011. Later, on June 5, 2016, the same organization published version 1.0 of the NVMe-oF specification. NVMe version 1.3 was then released in May 2017. This update added features to enhance security, resource sharing and solid-state drive (SSD) endurance.
The NVM Express organization estimated that 90% of the NVMe-oF protocol is the same as the NVMe protocol, which is designed for local use over a computer’s Peripheral Component Interconnect Express (PCIe) bus.
Vendors are working on developing a mature enterprise ecosystem that supports end-to-end NVMe over Fabrics, including the server operating system, server hypervisor, network adapter cards, storage OS and storage drives. In addition, storage area network (SAN) switch vendors — not limited to Cisco Systems Inc. and Mellanox Technologies — are trying to position 32 gigabits per second (Gbps) FC as the logical fabric for NVMe flash.
Since the initial development of NVMe-oF, there have been multiple implementations of the protocol, such as NVMe-oF using remote direct memory access (RDMA), FC or Transmission Control Protocol/Internet Protocol (TCP/IP).
Uses of NVMe over Fabrics
Although it is still a relatively young technology, NVMe-oF has been widely incorporated into network architectures. Using NVMe-oF can help provide a state-of-the-art storage protocol that can take full advantage of today’s SSDs. The protocol can also help in bridging the gaps between direct-attached storage (DAS) and SANs, enabling organizations to support workloads that require high throughputs and low latencies.
Initial deployments of NVMe were DAS in servers, with NVMe flash cards replacing traditional SSDs as the storage media. This arrangement offers promising high-performance gains when compared with existing all-flash storage, but it also has its drawbacks. NVMe requires the addition of third-party software tools to optimize write endurance and data services. Bottlenecks persist in NVMe arrays at the level of the storage controller.
Other use cases for NVMe-oF include optimizing real-time analytics, as well as playing roles in artificial intelligence (AI) and machine learning.
The use of NVMe-oF is a relatively new phase in the evolution of the technology, paving the way for the arrival of rack-scale flash systems that integrate native, end-to-end data management. The pace of mainstream adoption will depend on how quickly across-the-stack development of the NVMe ecosystem occurs.
What are the benefits of NVMe over Fabrics?
Benefits of NVMe-based storage drives include the following:
- low latency
- additional parallel requests
- increased overall performance
- reduction of the length of the OS storage stacks on the server side
- improvements pertaining to storage array performance
- faster end solution with a move from Serial-Attached SCSI (SAS)/Serial Advanced Technology Attachment (SATA) drives to NVMe SSDs
- variety of implementation types for different scenarios
Technical characteristics of NVMe over Fabrics
Some technical characteristics of NVMe-oF include the following:
- high speed
- low latency over networks
- credit-based flow control
- ability to scale out up to thousands of other devices
- multipath support of the fabric to enable multiple paths between the NVMe host initiator and storage target simultaneously
- multihost support of the fabric to enable sending and receiving of commands from multiple hosts and storage subsystems simultaneously
What are the key differences between NVMe over Fabrics and NVMe?
NVMe is an alternative to the Small Computer System Interface (SCSI) standard for connecting and transferring data between a host and a peripheral target storage device or system. NVMe is designed for use with faster media, such as SSDs and post-flash memory-based technologies. The NVMe standard speeds access times by several orders of magnitude compared to the SCSI and SATA protocols developed for rotating media.
NVMe supports 64,000 queues, each with a queue depth of up to 64,000 commands. All input/output (I/O) commands, along with the subsequent responses, operate on the same processor core, parlaying multicore processors into a high level of parallelism. I/O locking is not required, since each application thread gets a dedicated queue.
NVMe-based devices transfer data using a PCIe serial expansion slot, meaning there is no need for a dedicated hardware controller to route network storage traffic. Using NVMe, a host-based PCIe SSD is able to transfer data more efficiently to a storage target or subsystem.
One of the main distinctions between NVMe and NVMe over Fabrics is the transport-mapping mechanism for sending and receiving commands or responses. NVMe-oF uses a message-based model for communication between a host and a target storage device. Local NVMe will map commands and responses to shared memory in the host over the PCIe interface protocol.
While it mirrors the performance characteristics of PCIe Gen 3, NVMe lacks a native messaging layer to direct traffic between remote hosts and NVMe SSDs in an array. NVMe-oF is the industry’s response to developing a messaging layer.
NVME over Fabrics using RDMA
NVMe-oF use of RDMA is defined by a technical subgroup of the NVM Express organization. Mappings available include RDMA over Converged Ethernet (RoCE) and Internet Wide Area RDMA Protocol (iWARP) for Ethernet and InfiniBand.
RDMA is a memory-to-memory transport mechanism between two computers. Data is sent from one memory address space to another, without invoking the OS or the processor. Lower overhead and faster access and response time to queries are the result, with latency usually in microseconds (μs).
NVMe serves as the protocol to move storage traffic across RDMA over Fabrics. The protocol provides a common language for compute servers and storage to communicate regarding the transfer of data.
NVMe over Fabrics using RDMA essentially requires implementing a new storage network that bumps up performance. The trade-off is reduced scalability compared to the FC protocol.
NVMe over Fabrics using Fibre Channel
NVMe over Fabrics using Fibre Channel (FC-NVMe) was developed by the T11 committee of the International Committee for Information Technology Standards (INCITS). FC enables the mapping of other protocols on top of it, such as NVMe, SCSI and IBM’s proprietary Fibre Connection (Ficon), to send data and commands between host and target storage devices.
FC-NVMe and Gen 6 FC can coexist in the same infrastructure, enabling data centers to avoid a forklift upgrade.
Customers use firmware to upgrade existing FC network switches, provided the host bus adapters (HBAs) support 16 Gbps or 32 Gbps FC and NVMe-oF-capable storage targets.
The FC protocol supports access to shared NVMe flash, but there is a performance hit imposed to interpret and translate encapsulated SCSI commands to NVMe commands. The Fibre Channel Industry Association (FCIA) is helping to drive standards for backward-compatible FC-NVMe implementations, enabling a single FC-NVMe adapter to support SCSI-based disks, traditional SSDs and PCIe-connected NVMe flash cards.
NVMe over Fabrics using TCP/IP
One of the newer developments regarding NVMe-oF includes the development of NVMe-oF using TCP/IP. NVMe-oF can now support TCP transport binding. NVMe over TCP makes it possible to use NVMe-oF across a standard Ethernet network. There is also no need to make configuration changes or implement any special equipment with the use of NVMe-oF TCP/IP. Because the transport binding can be used over any Ethernet network or the internet, the challenges commonly involved in implementing any additional equipment and configurations are eliminated.
TCP is a widely accepted standard for establishing and maintaining network communications when exchanging data across a network. TCP will work in conjunction with IP, as both protocols used together facilitate communications across the internet and private networks. The TCP transport binding in NVMe-oF defines how the data between a host and a non-volatile memory subsystem are encapsulated and delivered.
The TCP binding will also define how queues, capsules and data are mapped, which supports TCP communications between NVMe-oF hosts and controllers through IP networks.
NVMe-oF using TCP/IP is a good choice for organizations that wish to utilize their Ethernet infrastructure. This will also give developers the ability to migrate NVMe technology away from Internet SCSI (iSCSI). As an example, an organization that doesn’t want to deal with any potential hassles included in implementing NVMe over Fabrics using RDMA can instead take advantage of NVMe-oF using TCP/IP on a Linux kernel.
Storage industry support for NVMe and NVMe-oF
Established storage vendors and startups alike are competing for a position within the market. All-flash NVMe and NVMe-oF storage products include the following:
- DataDirect Networks (DDN) Flashscale
- Datrium DVX hybrid system
- Kaminario K2.N
- NetApp Fabric-Attached Storage (FAS) arrays, including Flash Cache with NVMe SSD connectivity
- Pure Storage FlashArray//X
- Tegile IntelliFlash (acquired by Western Digital Corp. in 2017 and then sold to DDN in 2019)
In December 2017, IBM previewed an NVMe-oF InfiniBand configuration integrating its Power9 Systems and FlashSystem V9000, a product that is geared for cognitive workloads that ingest massive quantities of data.
In 2017, Hewlett Packard Enterprise introduced its HPE Persistent Memory server-side flash storage using ProLiant Gen9 servers and NVMe-compliant Persistent Memory PCIe SSDs.
Dell EMC was one of the first storage vendors to bring an all-flash NVMe product to market. The DSSD D5 array was built with Dell PowerEdge servers and a proprietary NVMe over PCIe network mesh. The product was shelved in 2017 due to poor sales.
A handful of startups have also launched NVMe all-flash arrays:
- Apeiron Data Systems uses NVMe drives for media and houses data services in field-programmable gate arrays (FPGAs) instead of servers attached to storage arrays.
- E8 Storage (bought by Amazon in 2019) uses its software to replicate snapshots from the E8-D24 NVMe flash array to attached branded compute servers, a design that aims to reduce management overhead on the array.
- Excelero software-defined storage runs on any standard servers.
- Mangstor MX6300 NVMe-oF arrays are based on Dell EMC PowerEdge outfitted with branded NVMe PCIe cards.
- Pavilion Data Systems has a branded Pavilion Memory Array built with commodity network interface cards (NICs), PCIe switches and processors. Pavilion’s 4U appliance contains 20 storage controllers and 40 Ethernet ports, which connect to 72 NVMe SSDs using the internal PCIe switch network.
- Vexata Inc. offers its VX-100 and Vexata Active Data Fabric distributed software. The vendor’s Ethernet-connected NVMe array includes a front-end controller, a cut-through router based on FPGAs and data nodes that manage I/O schedules and metadata.
Chipmakers, network vendors prep the market
Computer hardware vendors broke new ground on NVMe over Fabrics technologies in 2017. Networking vendors are waiting for storage vendors to catch up and start selling NVMe-oF-based arrays.
FC switch rivals Brocade and Cisco each rolled out 32 Gbps Gen 6 FC gear that supports NVMe flash traffic, including FC-NVMe fabric capabilities. Also entering the fray was Cavium, refreshing the QLogic Gen 6 FC and FastLinQ Ethernet adapters for NVMe-oF.
Marvell introduced its 88SS1093 NVMe SSD controllers, featuring an advanced design that places its low-density parity check technology for triple-level cell (TLC) NAND flash devices running on top of multi-level cell (MLC) NAND.
Mellanox Technologies has developed an NVMe-oF storage reference architecture based on its BlueField system-on-a-chip (SoC) programmable processors. Similar to hyper-converged infrastructure (HCI), BlueField integrates compute, networking, security, storage and virtualization tools in a single device.
Microsemi Corp. teamed with American Megatrends (AMI) to develop an NVMe-oF reference architecture. The system incorporates Microsemi Switchtec PCIe switches in Intel Rack Scale Design (RSD) disaggregated composable infrastructure hardware running AMI’s Fabric Management Firmware.
Among drive-makers, Intel Corp. led the way with dual-ported 3D NAND-based NVMe SSDs and Intel Optane NVMe drives, which are based on 3D XPoint memory technology developed by Intel and chipmaker Micron Technology, Inc. Intel claims Optane NVMe drives are approximately eight times faster than NAND flash memory-based NVMe PCIe SSDs.
Micron rolled out its 9200 series of NVMe SSDs and also branched into selling storage, launching the Micron Accelerated Solutions NVMe reference architecture and Micron SolidScale NVMe-oF-based appliances.
Seagate Technology introduced its Nytro 5000 M.2 NVMe SSD and started sampling a 64 terabyte (TB) NVMe add-in card.
What is Continuous Integration (CI)?
Continuous integration (CI) is a software engineering practice in which frequent, isolated changes are immediately tested and reported on when they are added to a larger code base.
CI aims to provide rapid feedback so that when a defect is introduced into the code base, it is identified and corrected as soon as possible.
CI originated from within the Extreme Programming paradigm, which is a subset of the Agile methodology, but the principles can be applied to any iterative programming model. Traditional development approaches, such as the Waterfall model, can also benefit from the use of CI methods for the construction stage. Continuous integration commonly is paired with continuous delivery, wherein steps to deliver executable code to production occur rapidly and with automation, for CI/CD.
What are the common practices for CI?
According to Paul Duvall, co-author of Continuous Integration: Improving Software Quality and Reducing Risk, best practices of CI include:
- Frequent code commits;
- Developer test categorization;
- A dedicated integration build machine;
- Continuous feedback mechanisms; and
- Staging builds.
CI releases can occur at any frequency, depending on the organization that runs it and the project at hand; generally, organizations that adopt CI release more frequently than with previous software development processes. Each significant change kicks off a build. A development team incorporates CI for a number of reasons, including to receive constant feedback on the status of the software. CI detects deficiencies early in development, which makes them less disruptive, less complex and easier to resolve than later in the software development life cycle.
A development team can use automation in the CI setup to incorporate code integration and testing, which reduces time to find bugs and enables faster feedback than when these tasks are carried out manually. Automation tools help teams perform common tests as part of the CI process, such as unit, application programming interface (API) and functional tests. A unit test examines the smallest application components. An API test assesses whether or not an API can reliably perform under its expected load of requests and responses. A functional test typically evaluates larger pieces of the source code to simulate a user workflow or function. With full CI automation, scripts or integration engines manage the movement of new code through tests and build.
This automated approach is often an integral part of a CI/CD pipeline and a DevOps methodology. CD acts as an extension of CI, not an alternative. CI focuses on the build and code testing parts of the development cycle, while CD includes deployment tests and configuration automation. In CD, a development team produces and releases software to production in short cycles. Continuous deployment is a more advanced step, wherein the code releases automatically into production, live to end users.
What are the benefits of CI?
When it incorporates CI into the development process, a dev team can bring worthwhile benefits to an organization.
CI enables shorter and less disruptive code integrations, as less code is integrated at a time, at a more frequent rate than in other dev approaches, such as waterfall. Similarly, reverted changes are less disruptive, because only isolated changes go out at once.
Bug detection is easier and faster as well, because if a bug surfaces, it will most likely be in the last integrated batch of code. Both of these benefits are the result of increased code visibility, as developers constantly add to the code base.
Continuous integration also enables continual feedback on changes, which can improve a product over time.
List of CI tools
A development team uses CI software tools to automate parts of the application build and construct a document trail. The following are examples of CI pipeline automation tools commonly found in enterprise IT shops. Many additional tools exist for steps in the CI pipeline, such as Version control, testing, builds and artifact storage, and are too numerous to detail here.
Jenkins is an open source CI automation server. Jenkins can distribute tests and builds over numerous machines. Plug-ins extend Jenkins’ feature capabilities, such as those for automated unit tests and test reporting. A developer can create a project build via specific URLs, commits in a version control system, or a pre-scheduled and sequential system. Once a system is tested, Jenkins also supports the ability to deploy code with CD. CloudBees enables the use of Jenkins at enterprise scale.
The open source GitLab repository and platform supports CI/CD. GitLab can run unit and integration tests on multiple machines and can split builds to work over multiple machines to decrease project execution times. The software also supports manual deployments for CD to staging environments and to production environments. GitLab also supports integration with tools such as Atlassian Jira, GitHub and Jenkins.
JetBrains TeamCity is an integration and management server for CI/CD. TeamCity enables developers to test code before they commit changes to a code base. If a test fails, TeamCity sends a notification. TeamCity features Build Grids, which enable developers to run multiple tests and builds for different platforms and environments. TeamCity includes support for Docker, Jira and other programs.
What is Cloud Services?
Cloud services refer to any IT services that are provisioned and accessed from a cloud computing provider. This is a broad term that incorporates all delivery and service models of cloud computing and related solutions. Cloud services are delivered over the internet and accessible globally from the internet.
Cloud services provide many IT services traditionally hosted in-house, including provisioning an application/database server from the cloud, replacing in-house storage/backup with cloud storage and accessing software and applications directly from a web browser without prior installation.
There are three basic types of cloud services:
- Software as a service (SaaS)
- Infrastructure as a service (IaaS)
- Platform as a service (PaaS)
Cloud services provide great flexibility in provisioning, duplicating and scaling resources to balance the requirements of users, hosted applications and solutions. Cloud services are built, operated and managed by a cloud service provider, which works to ensure end-to-end availability, reliability and security of the cloud.
What is Oracle Public Cloud?
The Oracle Public Cloud is an application development platform solutions delivered entirely through the Internet on a subscription-based billing method from Oracle Corporation.
Oracle’s public cloud solution provides enterprise-class applications, middleware services and databases managed, hosted, patched and supported by Oracle itself. The services offered under Oracle public cloud are, Fusion CRM and HCM Cloud, Social Network Cloud, Database Cloud and Java Cloud and being hosted at Oracle’s datacenters by default, posses a scalable, flexible and secure architecture.
Oracle public cloud is a cloud enterprise as a service (Eaas) solution imparting all the three cloud service models and enterprise IT fundamentals within one single solution provided on a self-service basis.
Oracle provides its customers the flexibility to use its powerful CRM, Human Capital Management and Social Network enterprise collaboration tools for deploying their own business application processes on them or to create customized enterprise wide complex applications by using their Java and database backend platform; hosted on Oracle’s infrastructure or can easily be deployed on most public or private IaaS clouds. Oracle public cloud is different from Oracle on-demand CRM, where the former is a comprehensive suite of different applications and the latter only provides CRM on a per license billing method.
What is Oracle Database (Oracle DB)?
Oracle Database (Oracle DB) is a relational database management system (RDBMS) from Oracle Corporation. Originally developed in 1977 by Lawrence Ellison and other developers, Oracle DB is one of the most trusted and widely used relational database engines for storing, organizing and retrieving data by type while still maintaining relationships between the various types.
The system is built around a relational database framework in which data objects may be directly accessed by users (or an application front end) through structured query language (SQL). Oracle is a fully scalable relational database architecture and is often used by global enterprises which manage and process data across wide and local area networks. The Oracle database has its own network component to allow communications across networks.
Oracle DB is also known as Oracle RDBMS and, sometimes, simply as Oracle.
Databases are used to provide structure and organization to data stored electronically in a computer system. Before they were adopted, early computers stored data in flat file structures where information in each file was separated by commas (CSV files). However, as the number of fields and rows that defined the characteristics and structure of each piece of data continued increasing, it was only a matter of time before this approach would become unmanageable.
Relational models for database management represented the ideal solution to this issue by organizing data in entities and attributes that further describe them. Today, Oracle Database represents the RDBMS with the largest market share. Oracle DB rivals Microsoft’s SQL Server in the enterprise database market. There are other database offerings, but most of these command a tiny market share compared to Oracle DB and SQL Server. Fortunately, the structures of Oracle DB and SQL Server are quite similar, which is a benefit when learning database administration.
Oracle DB runs on most major platforms, including Windows, UNIX, Linux and macOS. The Oracle database is supported on multiple operating systems, including IBM AIX, HP-UX, Linux, Microsoft Windows Server, Solaris, SunOS and macOS.
Oracle started supporting open platforms such as GNU/Linux in the late 1990s. Different software versions are available, based on requirements and budget. Oracle DB editions are hierarchically broken down as follows:
- Enterprise Edition: Offers all features, including superior performance and security, and is the most robust
- Personal Edition: Nearly the same as the Enterprise Edition, except it does not include the Oracle Real Application Clusters option
- Standard Edition: Contains base functionality for users that do not require Enterprise Edition’s robust package
- Express Edition (XE): The lightweight, free and limited Windows and Linux edition
- Oracle Lite: For mobile devices
A key feature of Oracle is that its architecture is split between the logical and the physical. This structure means that for large-scale distributed computing, also known as grid computing, the data location is irrelevant and transparent to the user, allowing for a more modular physical structure that can be added to and altered without affecting the activity of the database, its data or users.
The sharing of resources in this way allows for very flexible data networks with capacity that can be adjusted up or down to suit demand, without degradation of service. It also allows for a robust system to be devised, as there is no single point at which a failure can bring down the database since the networked schema of the storage resources means that any failure would be local only.
The largest benefit of the Oracle DB is that it is more scalable than SQL, which can make it more cost-efficient in enterprise instances. This means that if an organization requires a large number of databases to store data, they can be configured dynamically and accessed quickly without any periods of downtime.
Other structural features that make Oracle popular include:
- Efficient memory caching to ensure the optimal performance of very large databases
- High-performance partitioning to divide larger data tables in multiple pieces
- The presence of several methods for hot, cold and incremental backups and recoveries, including the powerful Recovery Manager tool (RMAN)
What is Punchdown Block?
A punchdown block is a mechanism used to cross-connect sets of wires through a metal peg system in telecommunications closets or local area networks (LAN). Solid copper wires are punched into short and open-ended slots that serve as insulation displacement connectors.
A punchdown block is also known as a punch down block, cross-connect block, terminating block, connecting block, punchblock or quick-connect block.
The punchdown block mechanism facilitates quick and efficient wiring for the following reasons:
- Insulation stripping is not required.
- There are no screws to loosen and tighten.
Punchdown blocks are designed for 22-26 Average Wire Gauge (AWG) solid copper wire.
The most common punchdown block is the 66 block (or M-Block, which has 50 rows, each with four columns of electrically bonded metal peg clips. The 66 model is often used to cross connect work area outlets and patch panels. 66 model types are a 25-pair standard non-split version and a 25-pair split version.
What is DevOps as a Service?
DevOps as a Service is a delivery model for a set of tools that facilitates collaboration between an organization’s software development team and the operations team. In this delivery model, the DevOps as a Service provider provides the disparate tools that cover various aspects of the overall process and connects these tools to work together as one unit. DevOps as a Service is the opposite of an in-house best-of-breed toolchain approach, in which the DevOps team uses a disconnected collection of discrete tools.
The aim of DevOps as a Service is to ensure that every action carried out in the software delivery process can be tracked. The DevOps as a Service system helps to ensure that the organization achieves desired outcomes and successfully follows strategies such as continuous delivery (CD) and continuous integration (CI) to deliver business value. DevOps as a Service also provides feedback to the developer group when a problem is identified in the production environment.
What are the advantages of DevOps as a Service?
DevOps as a Service can appeal to organizations that lack internal DevOps expertise, or the budget to obtain or train up employees with those skills. This approach also hides the complexities of data and information flow management up and down the toolchain. Various individuals and teams involved with the DevOps process can use intuitive interfaces to call on the aspects of the tooling they require, without having to understand how the entire toolchain works. For example, using the same DevOps as a Service offering, a developer can call upon source code management tools, a tester can check application performance management tools and the IT operations team can make changes with configuration management tools. This allows the team to monitor and report on activities that occur in the toolchain.
By integrating chosen elements of DevOps tooling into a single overarching system, DevOps as a Service aims to improve collaboration, monitoring, management and reporting. An effective DevOps as a Service strategy enables a business to adopt a more flexible approach to its markets, and bring forth new products and services as the market changes. DevOps and DevOps as a Service can coexist with traditional development and deployment processes.
What are the disadvantages of DevOps as a Service?
Discussion of DevOps as a Service offerings presumes that there is agreement on a single complete toolchain for DevOps that effectively meets any organization’s needs, much less one that a provider could offer in a managed services model. Most DevOps toolchains incorporate some type of a CI/CD pipeline and monitoring capabilities, from the software development process to deployment into production, but organizations’ needs and preferences will vary.
A managed DevOps services model also may limit an organization’s options for tools and specific capabilities versus specific evaluation and selection of best-of-breed tools that are integrated in-house. Managed DevOps providers may offer fewer choices among individual tools, whether their own or from partners.
Other potential challenges with a DevOps-as-a-Service model involve tradeoffs in speed versus security, and a service provider’s ability to meet availability and reliability requirements. An organization must keep a close eye on its use of services and associated tools, to keep costs under control.
Moreover, an organization’s internal staff still must understand how the managed DevOps services and hosted tools interact and integrate with each other, as well as within the organization’s own IT infrastructure and chosen cloud platform, so they can support applications after deployment to production.
The DevOps as a Service market
DevOps as a Service providers include DevOps tools vendors, public cloud platform providers, systems integrators and even IT teams that curate a toolchain and integrate it in-house. A DevOps as a Service vendor typically offers at least one of the following:
- a complete proprietary stack created, managed and maintained by the provider;
- strategies for the user to manage the cultural change involved in blending tasks traditionally performed by siloed software application development and systems operations teams;
- a more open stack wherein the vendor creates a proprietary interoperability system, allowing for some hosted open source components; or
- an orchestration layer that uses open application programming interfaces to integrate with existing tools.
Top DevOps-as-a-Service tools and products. A wide range of providers offer some form of DevOps as a Service — major public cloud platforms, large and small managed services providers, global consultancies and DevOps-specific consulting firms.
Vendors may offer as-a-service versions of their tools that represent individual links in the DevOps toolchain, and integrate them with other tools in the DevOps toolchain. Typically, however, those vendors do not span and support an entire DevOps toolchain, especially ones that incorporate tools from multiple providers.
“By integrating chosen elements of DevOps tooling into a single overarching system, DevOps as a Service aims to improve collaboration, monitoring, management and reporting..” – Clive Longbottom
Related Terms: continuous delivery, continuous integration, open API, DevOps certification, configuration management
What is General Availability (GA)?
In the software release life cycle, general availability (GA) refers to the marketing phase when all commercialization activities pertaining to the software product have been completed and it is available for purchase. Commercialization activities encompass compliance and security tests as well as localization and worldwide availability. General availability is a part of the release phase of the software and is preceded by the release to manufacturing (RTM) phase.
General availability is also known as production release.
General availability is the phase of the software release life cycle where the software is made available for sale. The availability though, can largely vary on the basis of the form in which it is released, language and the region as well. General availability usually happens on a specific date, which has been announced in advance to customers. Any software that has made it to this stage is assumed to have gone through all of the earlier release stages, and has also passed them successfully. This means that the software product has proven to be reliable, free of critical bugs and is suitable for usage in production systems. The general availability phase is also when the software must support all its promised features and be available to developers outside the developing firm.
What is Narrow AI (Weak AI)?
Narrow AI, also known as weak AI, is an application of artificial intelligence technologies to enable a high-functioning system that replicates — and perhaps surpasses — human intelligence for a dedicated purpose.
Narrow AI is often contrasted with general artificial intelligence (AGI), sometimes called strong AI; a theoretical AI system that could be applied to any task or problem.
Examples of narrow AI
All forms of modern AI systems can be classified as narrow AI. They are as follows:
- Image and facial recognition systems: These systems, including those used by social media companies like Facebook and Google to automatically identify people in photographs, are forms of weak AI.
- Chatbots and conversational assistants: This includes popular virtual assistants Google Assistant, Siri and Alexa. Also included are simpler, customer-service chatbots, such as a bot that assists customers in returning an item to a retail store.
- Self-driving vehicles: Autonomous or semiautonomous cars, such as some Tesla models and autonomous drones, boats and factory robots, are all applications of narrow AI.
- Predictive maintenance models: These models rely on data from machines, often collected through sensors, to help predict when a machine part may fail and alert users ahead of time.
- Recommendation engines: These systems that predict content a user might like or search for next are forms of weak AI.
What are the advantages and disadvantages of narrow AI?
Advantages. Narrow AI systems can perform single tasks well, often better than humans. A weak AI system designed to identify cancer from X-ray or ultrasound images, for example, might be able to spot a cancerous mass in images faster and more accurately than a trained radiologist.
Meanwhile, a predictive maintenance platform could analyze incoming sensor data in real time, a feat virtually impossible for a person or group of people to do, to predict roughly when a piece of a machine will fail.
Disadvantages. Still, narrow AI systems can only do what they are designed to do and can only make decisions based on their training data. A retailer’s customer-service chatbot, for example, could answer questions regarding store hours, item prices or the store’s return policy. Yet, a question about why a certain product is better than a similar product would likely stump the bot, unless its creators took the time to program the bot to respond to such questions specifically.
Meanwhile, AI systems are prone to bias, and can often give incorrect results while being unable to explain them. Complex models are often trained on massive amounts of data — more data than its human creators can sort through themselves. Large amounts of data often contain biases or incorrect information, so a model trained on that data could inadvertently internalize that incorrect information as true.
The model would make skewed predictions, yet its users, unaware it was trained on biased data, wouldn’t know the predictions are off.
Comparison between Narrow AI, general AI, weak AI, and strong AI
AGI involves a system with comprehensive knowledge and cognitive capabilities such that its performance is indistinguishable from that of a human, although its speed and ability to process data is far greater. Such a system has not yet been developed, and expert opinions differ as if such as system is possible to create.
Some experts believe that an artificial general intelligence system would need to possess human qualities, such as consciousnesses, emotions and critical-thinking.
Systems built on narrow AI, or weak AI, have none of these qualities, although they can often outperform humans when pointed at a particular task. These systems aren’t meant to simulate human intelligence fully but rather to automate specific human tasks using machine learning, deep learning and natural language processing (NLP).
What is Public Cloud Storage?
Public cloud storage is a cloud storage model that enables individuals and organizations alike to store, edit and manage data. This type of storage exists on a remote cloud server and is accessible over the internet under a subscription-based utility billing method where the users pay only for the storage capacity being used.
Public cloud storage is provided by a storage service provider that hosts, manages and sources the storage infrastructure publicly to many different users.
Public cloud storage service is also known as storage as a service, utility storage and online storage.
Public cloud storage generally enables the sourcing of massive amounts of storage space on demand over the internet, and is built over storage virtualization, which logically distributes large storage arrays into a multitenant architecture shared among various users and applications.
Public cloud storage capacity is made possible through two different sourcing models:
- Web services APIs
- Thin client applications
Public cloud storage enabled through APIs is designed to be used for web applications that require access to scalable storage at run time, whereas thin client applications provide end users with a way to back up and store their local data on remote cloud storage. Amazon S3, Mezeo and Windows Azure are popular examples of public cloud storage.
What is Ethical Hacker?
An ethical hacker, also referred to as a white hat hacker, is an information security (infosec) expert who penetrates a computer system, network, application or other computing resource on behalf of its owners — and with their authorization. Organizations call on ethical hackers to uncover potential security vulnerabilities that malicious hackers could exploit.
The purpose of ethical hacking is to evaluate the security of and identify vulnerabilities in target systems, networks or system infrastructure. The process entails finding and then attempting to exploit vulnerabilities to determine whether unauthorized access or other malicious activities are possible.
What is ethical hacking?
An ethical hacker needs deep technical expertise in infosec to recognize potential attack vectors that threaten business and operational data. People employed as ethical hackers typically demonstrate applied knowledge gained through recognized industry certifications or university computer science degree programs and through practical experience working with security systems.
Ethical hackers generally find security exposures in insecure system configurations, known and unknown hardware or software vulnerabilities, and operational weaknesses in process or technical countermeasures. Potential security threats of malicious hacking include distributed denial-of-service attacks in which multiple computer systems are compromised and redirected to attack a specific target, which can include any resource on the computing network.
An ethical hacker is given wide latitude by an organization to legitimately and repeatedly attempt to breach its computing infrastructure. This involves exploiting known attack vectors to test the resiliency of an organization’s infosec posture.
Ethical hackers use many of the same methods and techniques to test IT security measures, as do their unethical counterparts, or black hat hackers. However, rather than taking advantage of vulnerabilities for personal gain, ethical hackers document threat intelligence to help organizations remediate network security through stronger infosec policies, procedures and technologies.
Any organization that has a network connected to the internet or that provides an online service should consider subjecting its operating environment to penetration testing (pen testing) conducted by ethical hackers.
What do ethical hackers do?
Ethical hackers can help organizations in a number of ways, including the following:
- Finding vulnerabilities: Ethical hackers help companies determine which of their IT security measures are effective, which need updating and which contain vulnerabilities that can be exploited. When ethical hackers finish evaluating an organization’s systems, they report back to company leaders about those vulnerable areas, which may include a lack of sufficient password encryption, insecure applications or exposed systems running unpatched software. Organizations can use the data from these tests to make informed decisions about where and how to improve their security posture to prevent cyber attacks.
- Demonstrating methods used by cybercriminals: These demonstrations show executives the hacking techniques that malicious actors could use to attack their systems and wreak havoc on their businesses. Companies that have in-depth knowledge of the methods the attackers use to break into their systems are better able to prevent those incursions.
- Helping to prepare for a cyber attack: Cyber attacks can cripple or destroy a business — especially a smaller business — but most companies are still unprepared for cyber attacks. Ethical hackers understand how threat actors operate, and they know how these bad actors will use new information and techniques to attack systems. Security professionals who work with ethical hackers are better able to prepare for future attacks because they can better react to the constantly changing nature of online threats.
What are the differences between Ethical hacking and penetration testing?
Pen testing and ethical hacking are often used as interchangeable terms, but there is some nuance that distinguishes the two roles. Many organizations will use both ethical hackers and pen testers to bolster IT security.
Ethical hackers routinely test IT systems looking for flaws and to stay abreast of ransomware or emerging computer viruses. Their work often entails pen tests as part of an overall IT security assessment.
Pen testers seeks to accomplish many of the same goals, but their work is often conducted on a defined schedule. Pen testing is also more narrowly focused on specific aspects of a network, rather than on ongoing overall security.
For example, the person performing the pen testing may have limited access only to the systems that are subject to testing and only for the duration of the testing.
How to become an ethical hacker?
There are no standard education criteria for an ethical hacker, so an organization can set its own requirements for that position. Those interested in pursuing a career as an ethical hacker should consider a bachelor’s or master’s degree in infosec, computer science or even mathematics as a strong foundation.
Individuals not planning to attend college can consider pursing an infosec career in the military. Many organizations consider a military background a plus for infosec hiring, and some organizations are required to hire individuals with security clearances.
Other technical subjects — including programming, scripting, networking and hardware engineering — can help those pursuing a career as ethical hackers by offering a fundamental understanding of the underlying technologies that form the systems they will be working on. Other pertinent technical skills include system administration and software development.
What is Private Cloud Storage?
Private cloud storage is a type of storage mechanism that stores an organization’s data at in-house storage servers by implementing cloud computing and storage technology.
Private cloud storage is similar to public cloud storage in that it provides the usability, scalability and flexibility of the storage architecture. But unlike public cloud storage, it is not publicly accessible and is owned by a single organization and its authorized external partners.
Private cloud storage is also known as internal cloud storage.
Private cloud storage works much like public cloud storage and implements storage virtualization across an organization, providing a centralized storage infrastructure that can only be accessed by the authorized nodes.
Private cloud storage operates by installing a data center, which houses a series of storage clusters that are integrated with a storage virtualization application. Administrative policies and a management console provide access to the different storage nodes and applications within the organization’s network. The applications or nodes access the private storage through file access and data retrieving protocols, while the automated storage administrator application allocates storage capacity to them on run time.
Private cloud storage has a multitenant architecture, where a single storage array can house storage space to multiple applications, nodes or departments.
List
Microsoft Mac Downloads is a one-stop shop for Mac-specific Microsoft installers. Explains, “It’s a cleanly-organized table of download links (automatically updated) for standalone installer packages of Microsoft products for macOS systems. As someone managing a 70/30 Win/Mac workstation environment this will save me quite a bit of hassle with the Apple side.”
Awesome Network Automation is a curated list of fantastic network automation resources that is a real treasure trove for anyone looking for a convenient way to find useful information on network automation. Kindly suggested by onefst250r.
Tip
A great idea for labelling cables: “Use wrap mode, but not directly on cable. Put a large diameter plastic straw over the cable first. On fiber, it gives you more space to type… also allows spinning to read it, and labels tend to stay stuck.”
Podcast
Network Collective is a network engineering podcast with industry experts, pioneers and fellow engineers from the networking community. Topics range from protocol deep-dives to career management, but with a focus on relevance and providing value to those working in the field.
The History of Networking features fascinating discussions about the creation of all the technologies that make the modern Internet possible. It’s an opportunity to hear stories about world-changing technologies and the organizations involved from the very people who created them.
The Hedge is a network engineering podcast that covers technology and other topics of relevance to a network engineer, from the smallest networks up to the entirety of the internet.
Heavy Networking is a weekly podcast from Packet Pushers that takes an “unabashedly nerdy” deep dive into data networking tech. Features hour-long interviews with industry experts and real-life network engineers from the tech community, standards bodies, academia, vendors and more.
Clear To Send is a weekly podcast on wireless engineering that covers WiFi technology, design tips, troubleshooting and tools. Features informative interviews with wireless engineers, tech news on the topic, and product information.
On-Call Nightmares Podcast features the intriguing tales of those brave souls who work on-call in technology. Host Jay Gordon interviews the “survivors” as they share some of their nightmare experiences in trying to understand and resolve the problems that got dropped in their laps.
Cheatsheet
CSP Cheatsheet is a quick reference on all the supported features and directives of Content Security Policy. Includes example policies and suggestions on how to make the best use of CSP. Can be helpful when you need to identify valid and invalid directives and values.
Tech Support Cheat Sheet is the answer for those tired of being expected to know how to use every piece of software that has ever been written, regardless of whether it is at all related to your job. This all-purpose how-to is the perfect addition to your arsenal of user training materials. Adds, “I share this with my users a lot. :)”
Vim Cheatsheet is a nicely organized, printable collection of key, useful Vim commands. A dark version is also available here.
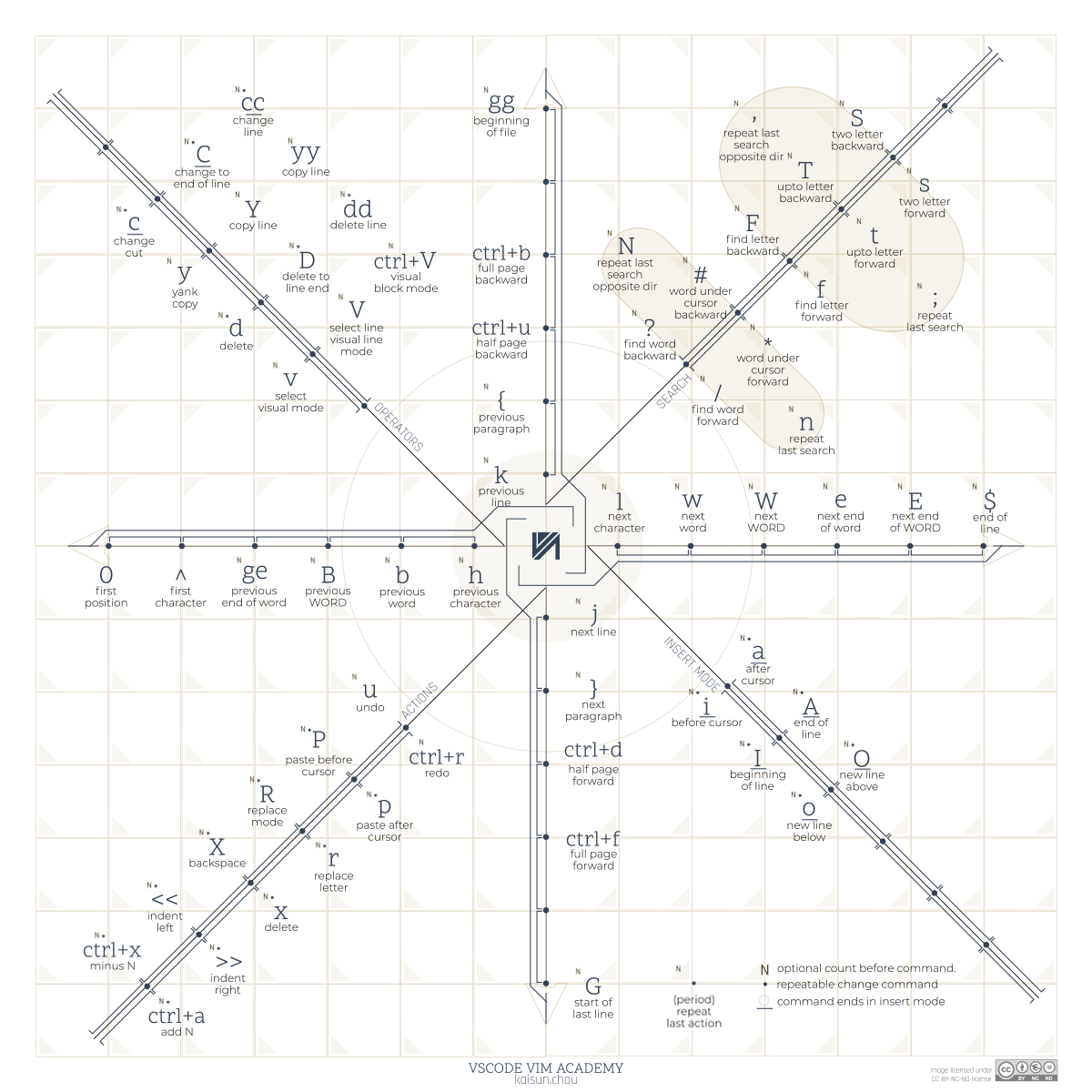{kind=link}
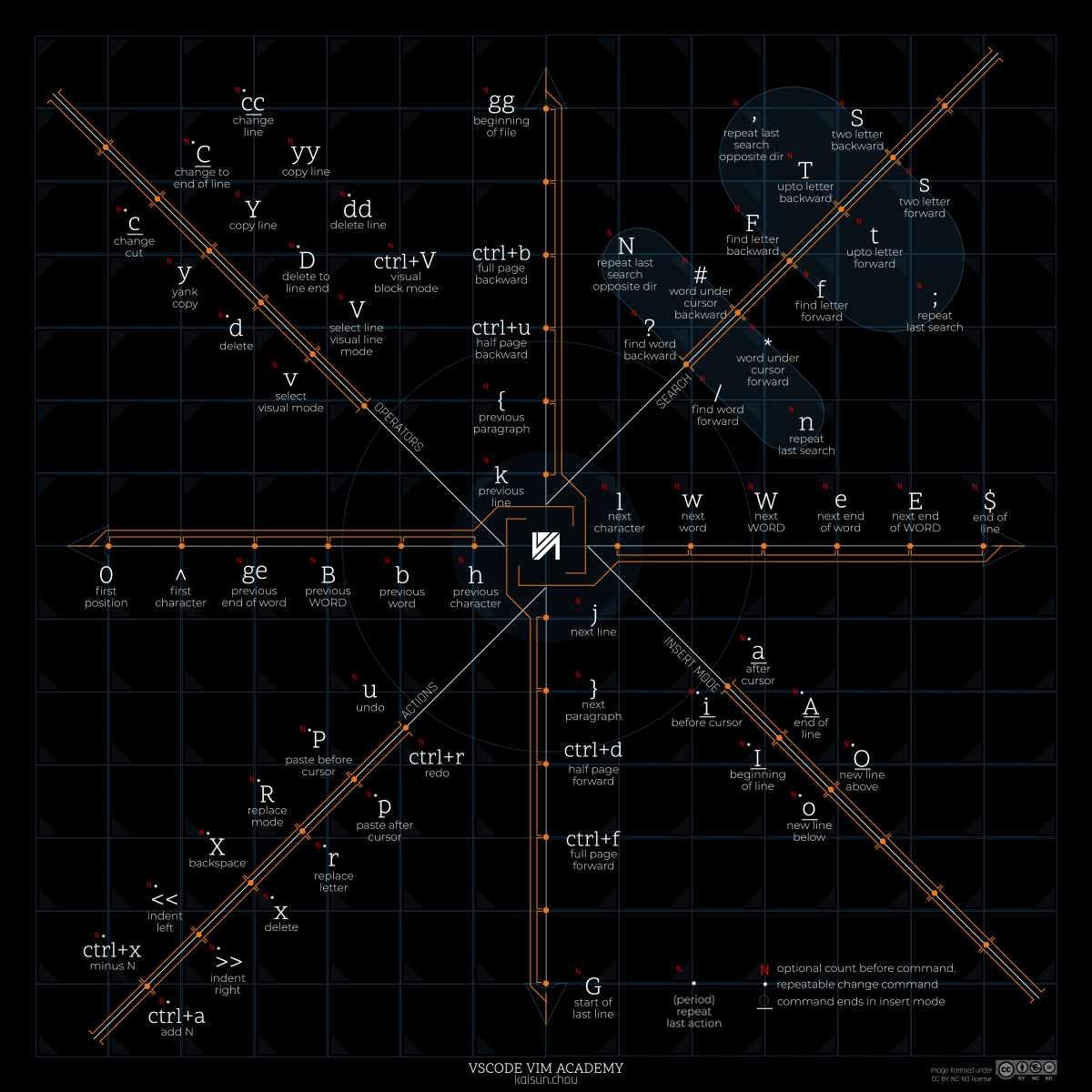{kind=link}
Regexp Cheatsheet is a helpful blog post on Basic Regular Expressions (BRE) and Extended Regular Expressions (ERE) syntax supported by GNU grep, sed and awk. It covers the differences between these somewhat complex tools — for example, awk doesn’t support backreferences within regexp definition (i.e., the search portion).
Awk Cheatsheet is a collection of one-line Awk scripts compiled into a time-saving resource by Eric Pement. Appreciates it as a quick place to look for “nearly everything I need for Awk in one cheatsheet.”
The Most Common OpenSSL Commands is a list of essential commands and their usage for those who want to leverage the incredible versatility of OpenSSL but aren’t all that comfortable dealing with certs. Explains, “You don’t need any understanding of openssl at all [for it to be useful]. You probably only need this… and a basic understanding of certs and cert formats. Also, never publish your private key.”
Sed Cheatsheet is Eric Pement’s handy reference to help facilitate Sed scripting. Appreciates this compilation of useful one-line scripts because “knowing your way around the gnu toolset has been super useful for me…. Nearly everything I need for Sed [is] in the one-liners cheat sheet.”
JavaScript Cheatsheet is a highly useful, 9-page cheatsheet full of illustrative examples. It is highly readable, easily understood and available in a printable pdf version.
Script
Meraki-CLI is a wrapper around the official Meraki Dashboard API Python SDK that makes all 400+ commands available to the user as a standard command-line tool, including -h help options, commands, switches and arguments. Supports classic Linux-style pipelining, so you can pipe the output of one instance of the program to another. Recommends it for “any network engineers out there [who] have had a need for easy Meraki scripting, but didn’t want to write code against Meraki’s REST API.”
Blog
Practical Networking offers simple, concrete explanations of complex technology in a way that ensures what you learn is immediately applicable. It is intended to bridge the gap between very-basic articles on network engineering and those that get so far into the minutiae that they are virtually impossible to follow.
PrajwalDesai.com is the place where the author—a Microsoft MVP and server technology expert—shares his knowledge and helpful technical information. You’ll find lots of posts and videos on SCCM, LYNC, Exchange and more, with detailed explanations including screenshots when appropriate to make solutions easier to deploy.
DMAC Network Automation Blog is where network engineer Daniel Macuare shares his passion for solving problems with code and improving the state of network infrastructure. You’ll find original articles, automation ideas and how-tos.
Lessons in Tech offers a series of well-written, detailed how-tos that explain assorted web, security and networking topics. Includes lots of example code and images for enhanced clarity.
Steve on Security offers high-level, practical advice and information on security for Microsoft products. It’s the work of Steve Syfuhs, a senior developer on the Azure Active Directory team at Microsoft who was previously a Microsoft Developer Security MVP for many years before joining the MS team.
Free Tool
SeaweedFS is a fast, distributed storage system for blobs, objects, files and data that stores/serves billions of files. Can transparently integrate with the cloud with both fast local access and elastic cloud storage capacity. Blob store has O(1) disk seek, local and cloud tiering. Filer supports cross-cluster active-active replication, Kubernetes, POSIX, S3 API encryption, Erasure Coding for warm storage, FUSE mount, Hadoop and WebDAV.
AutoPkgr makes it simple to install and configure AutoPkg quickly and reliably in the Mac OS. It’s the easy way to take advantage of automated macOS software packaging and distribution without the need for command-line methods. Explains, “For Mac downloads AutoPkgr is a god send, and you can make some interesting workflows and automations.”
5G-air-simulator is an open-source, system-level simulator for modeling the 5G air interface. Explains, “It is a compiled C++ code for Linux, which it’s launched via terminal, that gives out a text trace. Then through grep and awk, I extracted the KPIs I needed.”
Patch My PC Home Updater is an easy way to update or install over 300 apps on any computer. This simple tool can help keep things secure for users whose home equipment might be accessing your network by making sure they always have the latest security patches and updates installed.
ScreenToGif is an open-source tool for recording your screen, webcam feed or sketchboard drawings. The integrated editor allows you to edit recordings to adjust individual frames in assorted ways and add overlays. Exports to gif, apng, video, project, images and psd.
Remote Utilities is a secure, configurable remote desktop tool for viewing screens, sending keystrokes, controlling the mouse, transferring files and more. A free license allows you to control up to 10 remote PCs.
DNSdumpster is a domain recon and research tool that can discover hosts related to any domain. Enables you to assess your security by locating which hosts are visible to attackers.
Disk2vhd is a utility to create a VHD version of physical disks for use in Virtual PC or Hyper-V VMs. Unlike other such tools, Disk2vhd can be used on a system that’s online. “You can then mount the vhd in disk manager just like any other HDD and give it a drive letter.”
GNU Make is a tool for controlling the generation of executables and other non-source files, which can be helpful in building tools to manage and update configuration files. It enables an end user to build and install your package without really understanding what’s going on under the hood, because it automatically determines which files it needs to update (based on which source files have changed) as well as in which order to update files if they are dependent on one another.
Teleport is an open-source solution that provides unified access for SSH servers, Kubernetes clusters, web applications and databases across all environments. Features include single sign-on that allows discovery and instant access to all layers of your tech stack behind NAT across clouds, data centers or on the edge. Records all interactions in a structured audit log, so you can easily see exactly who did what.
nfdump enables you to collect and process netflow and sflow data sent from compatible devices for both historical analysis and continuous tracking of interesting traffic patterns. Optimized for speed in order to filter efficiently.
Continuous Bandwidth Tester is an internet speed stress test that can run for an unlimited period of time. Measures download/upload bandwidth, packet loss, RTT and ping—to show you the outages and drops of bandwidth affecting the stability of your internet connection. Imburr found it useful for “a client with a home user complaining they are getting kicked off an RDP server randomly… pretty sure it had something to do with their home internet. [It can] execute on their local PC over a few days to see if their internet connectivity is being lost briefly at random times [but without] a constant ping option, which might get them blocked.”
Scrapli is a fast and easy Python 3.6+ screen-scraping client for network devices. This flexible tool offers great editor support, sync/async, a pluggable transport system, the ability to add new device support, a Nornir plugin as well as options for NETCONF devices.
Dog is a distributed firewall management system for Linux that can manage hundreds of per-server firewalls, with consistent network access rules across servers in different regions across multiple providers. Features defense-in-depth, beyond gateway firewalls; constantly updated blocklists with thousands of addresses distributed across many servers; connection and/or bandwidth usage limits; and auto updates of per-server iptables rules.
ImportExcel is a PowerShell module for importing and exporting Excel spreadsheets without involving Excel. Allows you to read/write Excel files without the Excel COM-object, so you can more easily create tables, pivot tablesa and charts. Explains, “the ImportExcel function in Powershell (all bow before the great and mighty Doug Finke) is life-changing if you manipulate data inside Powershell. If anything deserves a shout-out, it does.”
sg3_utils is a set of Linux utilities for sending SCSI commands to devices. Works with transports like FCP, SAS, SPI as well as less-obvious devices that use SCSI, like ATAPI cd/dvd drives and SATA disks that connect through a translation layer or bridge device.
Apache Kafka is an open-source, distributed event streaming platform that captures data in real-time from event sources like databases, sensors, mobile devices, cloud services and software applications. Data is stored durably in the form of streams of events that can be manipulated, processed and reacted to in real-time as well as retrospectively. Event streams can be routed to different destination technologies as needed.
PeaZip is a cross-platform, open-source file archiver utility for reducing the size of large files. Simply add files for compression/decompression using the file explorer on the right, then choose an action to apply from the main toolbar or by right-clicking. A full-featured, user-friendly alternative to WinRar, WinZip and the like that allows you to open and extract over 200 archive formats.
Free Carrier Lookup allows you to enter any phone number to get the carrier name and whether the number is wireless or landline. Provides the latest data so it stays current and accurate for most countries. Also offers the email-to-SMS and email-to-MMS gateway addresses for US and Canadian phone numbers.
pyWhat enables you to easily identify emails, IP addresses and more. Feed it a .pcap file or some mysterious text or hex of a file, and it will tell you what it is. The tool is recursive, so it can identify everything in text, files and more.
Arkime is secure, scaleable, indexed packet capture and search tool that can improve your network security by providing greater visibility. This open-source tool stores and indexes network traffic in standard PCAP format.
TCP Port Scanner with Nmap is designed to detect open TCP ports and running services (including their versions) as well as conducting OS fingerprinting on a target IP address or hostname. Allows you to map your network perimeter, check firewall rules and verify which services are reachable from the Internet.
Veyon is an open-source tool for computer monitoring and classroom management on Linux and Windows. Enables you to monitor and remotely control all computers, access individual computers or take screenshots with a click, lock all computers and block input devices, and broadcast any screen to the group. Integrates with your network and directory services using the information already stored on your LDAP or ActiveDirectory server.
Cloud Foundry is an open-source tool for writing code in any language, with any framework, on any Kubernetes cluster. Provides a highly secure environment in which you can bypass complex configuration and routine operational tasks. Integrates with your environment and tools, including CI/CD and IDEs. Security patches are implemented quickly in response to vulnerabilities, so it stays secure for sensitive, mission-critical application development.
Octopus Deploy is an easy, centralized tool to automate your deployments and operations runbooks. Integrates with your favorite CI server and brings with it fantastic enhanced deployment/ops automation capabilities. Free for 10 deployment targets. Create some pipelines in Azure DevOps and send packages into Octopus for deployments. Really great for managing environments, variables and credentials amongst other things.”
Packetbeat is a lightweight, zero-latency-overhead network packet analyzer that sends data from your hosts and containers to Logstash or Elasticsearch. This passive tool lets you keep tabs on application latency and errors, response times, SLA performance as well as user access patterns and trends so you can understand how traffic is flowing through your network.
Sumatra PDF is a powerful multi-format reader for Windows. Supports PDF, EPUB, MOBI, FB2, CHM, XPS and DjVu files via a simple user interface with a top focus on speed.
Dehydrated is an easier way to sign certificates with an ACME-server. It can sign a list of domains (including wildcard domains) or a custom CSR (either standalone or completely automated), renew if a certificate is about to expire or defined set of domains changed, and revoke certificates.
Kimchi is an open-source HTML5-based KVM management tool that is designed for ease of use. This web-based virtualization management platform provides an intuitive, flexible interface that displays and provides control of all the VMs running on a system. Allows you to manage most of the basic features you need to create and control a set of guest virtual machines.
HESK is a basic, lightweight help desk tool with an integrated knowledgebase that helps customers quickly resolve some common issues on their own. Includes scripted responses, ticket templates, custom data fields and statuses and much more. Tickets can be prioritized and organized, and they include request details, your ongoing discussion with the customer, which staff member is assigned, notes, files, status and time spent on resolution. Staff accounts can be created with restrictions on access and functionality, and you can track who is working on what.
Otter allows you to easily run complex PowerShell and Shell scripts that provision servers and manage their configuration. The custom GUI includes templates that make it easy for users to develop complex, multi-server orchestrations regardless of programming expertise. Includes dashboards and reports that show the state of your infrastructure, permissions and installation status. Free version has no server limit and includes all features but gives all users unrestricted access.
Murder enables you to use Bittorrent to distribute files to a large amount of servers within a production environment. This approach allows for fast, scaleable deploys in large, data-center environments with hundreds or thousands of servers—where centralized distribution systems wouldn’t otherwise function.
TCP Throughput Calculator can help you determine your network’s theoretical limit, bandwidth-delay product and TCP buffer size to help you avoid or troubleshoot network speed issues. Explains, “If traffic is TCP-based, latency can have a huge effect on bandwidth.”
BorgBackup is an open-source deduplicating archiver that features compression and authenticated encryption for efficient storage of your backups. Tells us, “Borg Backup is something that has proven itself a lifesaver when doing one-off stuff. For example, Raspberry Pis at a remote location, I have them dump to Borgbase, and if I get a note that Borgbase has not seen one of them check in and do a backup, it is time to head out and see what’s going on.”
MeshCentral is a multi-platform, self-hosted, feature-packed website for remote device management. You can use the public, community server for free or install on your own server. The server and management agent run on Windows, Linux, MacOS and FreeBSD. Explains, “I would recommend meshcentral. It has worked great for our 200+ computers and it’s open source.”
openDCIM is designed for simple, complete data-center asset tracking. Offers support for multiple rooms; management of space, power and cooling; basic contact management and integration into existing business directory via UserID; fault tolerance; computation of center of gravity for each cabinet; template management for devices (with ability to override per device); optional tracking of cable connections within each cabinet and for each switch device; archival functions for equipment sent to salvage/disposal; integration with intelligent power strips and UPS devices.
AdminDroid is a free-for-MVPs-only reporting option that is more user-friendly than what you’ll find in the Office 365 Admin portal. It serves as a single tool to manage your entire Office 365 infrastructure, with advanced reporting capabilities such as scheduling, export, customizable reports, advanced filters and more.
StackStorm is an automation engine that can connect your apps, services and workflows. Allows you to create everything from simple if/then rules to complicated workflows within your existing infrastructure for a customized, automated remediation and security response.
Openfire is a powerful instant messaging and groupchat server that combines easy setup and administration with solid security and performance. Uses the open-source extensible messaging and presence protocol (XMPP) real-time collaboration (RTC) server.
Fast Software Audit offers you a quick, easy way to gather details on the installed software and Windows product keys/IDs from remote computers. Enter the computer name you want to scan, or specify multiple computers by importing a list of names from a CSV file. Results can be viewed on screen or exported to CSV for use elsewhere.
Homebrew is known as “The Missing Package Manager for macOS (or Linux).” It’s designed to easily install all the useful items your original OS installer didn’t bother to include.
Micro is a highly customizable, intuitive terminal-based text editor that’s easy to install. Supports over 75 languages; 16, 256 and truecolor themes; and Sublime-style multiple cursors. Explains, “It is very similar to Nano. It is a single-file, stand-alone executable that has mouse support, macro record/playback and syntax highlighting. It also has a Windows binary available for download (as well as Linux and MacOS).”
Total Commander, a simple file-manager replacement, has been around forever because it is genuinely useful and works well. While the popular Windows version is offered as shareware, the mobile version (Android, Windows Phone, PocketPC/WinCE)—which can be quite helpful in certain situations—is absolutely free.
inSSIDer is a simple tool to show how your WiFi network is configured as well as how other WiFi networks in the area are affecting yours. Also offers suggestions to improve speed and security. Can be a nice tool to suggest when users ask for help with problems on their home network.
RackTables helps document hardware assets, network addresses, space in racks, network configuration and more for datacenter and server room asset management. Allows you to compile a list of all devices, racks and enclosures; mount the devices into the racks; maintain physical ports of devices and links between them; manage IP addresses, assign them to devices and group into networks; document NAT rules; describe loadbalancing policy and store configuration; attach files to various objects in the system; create users, assign permissions and allow/deny their actions; and label everything and everyone with a flexible tagging system.
Logstash is a server-side data processing pipeline that dynamically ingests data from logs, metrics, web applications, data stores and assorted AWS services, and then transforms and ships it to your favorite “stash” in a continuous, streaming fashion. Regardless of format or complexity—Logstash filters parse each event as data travels from source to store, identify named fields to build a structure, and transform them into a common format to better facilitate analysis.
Alacritty is a modern terminal emulator with both a nice set of defaults and the option for extensive configuration. It integrates with other applications to offer a flexible set of features with high performance. Supports BSD, Linux, macOS and Windows. While currently in beta—i.e., there are still a few missing features and bugs to be fixed—it is appreciated by many for daily use.
Network Stuff is a portable, open-source application with a host of useful network tools. Includes TCP/UDP telnet, ping/traceroute, DNS resolver, whois, ARP, stats and TCP/UDP/IP tables (iphelper functions), TCP/UDP/ICMP/CGI multithreaded scan (TCP and CGI scan could be done throw HTTP or socks proxy), raw packet capture (multiple options including application name), raw packet forging, wake on LAN and remote shutdown and interactive TCP/UDP transparent proxy.
Speed Test WiFi Analyzer EXPERT includes a robust set of tools for analyzing network connections. Provides speed tests, wireless coverage 360 analyzer, WiFi analyzer, multi pinger and LAN connected devices. Adds, “I use https://analiti.com/ daily on my Android tablet, Amazon fire devices, etc. The free version is good. The paid version is cheap and great.”
Everything Toolbar is the easy-access interface you’ve been craving for Everything that enables you to quickly search for files, folders and more right from the Windows taskbar.
Observium Community is a low-maintenance, auto-discovering network monitoring platform that supports a wide range of device types, platforms and operating systems. It offers a powerful, intuitive interface for assessing the health and status of your network so you can proactively respond to more issues before they affect your services. Automatically collects and displays information on services and protocols and provides long-term metric collection and intuitive visual representations of collected performance data.
Samplicator is a simple tool for receiving UDP datagrams on a given port and resending them to a specified set of receivers for occasions when you need to export NetFlow traffic to more than one NetFlow collector. Can also be configured to individually specify a sampling divisor N for each receiver that will only receive one in N of the received packets. Adds, “It’s normally used for replicating netflow data, but can also replicate any UDP traffic.”
Security Content Automation Protocol (SCAP) is a compliance checker tool for evaluating the hardening of your machines. It used to be available only for DoD, government or contractor use but was recently released to the public by DISA. This automated program scans a machine (locally or remotely) to determine security posture based on Security Technical Implementation Guidelines (STIGs)—the checklists that identify what constitutes an open or closed vulnerability and how to remediate it. Notes that “STIGs (the rules SCC derives from) are what the DoD and DISA think should be set in order to harden machines… some of the items they hit against are no longer standard practice (eg expiring passwords). This is why it’s important to not just blindly remediate open STIG items without understanding how it impacts your environment.”
gProfiler is an easy-to-use, open-source tool that produces a unified visualization of what your CPU is working on, displaying stack traces of your processes across native programs, Java and Python runtimes and kernel routines. It’s a lightweight combination of different sampling profilers that requires minimal overhead, so it can be truly continuous. You can even upload results to the Granulate Performance Studio, which aggregates results from different instances over different periods to provide a holistic view of what is happening on your entire cluster. Comes with a pre-made Container image, and needs no changes or modifications to get started.
netmiko is a multi-vendor library to simplify Paramiko SSH connections to network devices. It provides a fairly uniform programming interface across a broad set of devices and handles many of the low-level SSH details that can be time consuming and problematic.
Problem Steps Recorder is a useful tool for creating documentation that can be found in all versions of Windows since Windows 7 (client) and Windows 2008 R2. It quickly and easily captures each step of your procedures on the fly during execution and allows you to add comments—although sadly, keystroke capture is not included.
ipcalc is a simple way to calculate the broadcast, network, Cisco wildcard mask and host range for any IP address/netmask—presenting the subnetting results in easy-to-understand binary values. Suggests it “if you do a lot of network stuff. I’ve had it for years as a favorite. I’m sure there’s fancy new ones out there, but for some reason I keep using it.”
TortoiseGIT is an open-source Windows Shell Interface to Git that offers overlay icons showing the file status, a powerful context menu for Git and more. Works with whatever development tools you like and with any type of file. The primary means of interaction with TortoiseGit is through the context menu of Windows Explorer.
IPinfo allows you to quickly pinpoint user locations, customize their experiences, prevent fraud, ensure compliance and more. Explains: “It responds to invoke-webrequest with info about your IP.”
Napalm provides a vendor neutral, cross-platform unified API to network devices. Since the configuration and management of network devices differs by vendor and platform, Napalm aims to make things simpler with a consistent API you can use across network devices from various vendors. This open-source solution works with all the most-popular automation frameworks.
Squid is a caching proxy for the Web that supports HTTP, HTTPS, FTP and more to reduce bandwidth and improve response times. It can route content requests to servers in a wide variety of ways to build cache server hierarchies that optimize network throughput. Offers extensive access controls and runs on most available operating systems. Explains, “Squid is not only a proxy, it also is an in-memory cache and has load balancing capabilities… Squid is used by companies, CDN’s and ISP’s around the world, legally, to help optimize delivery of content to consumers more efficiently and quickly.”
Apcupsd is designed for power management and control of most of APC’s UPS models on Unix and Windows machines. During a power failure, it notifies users that a shutdown may occur. If power is not restored, a system shutdown will follow when the battery is exhausted, a timeout (seconds) expires, or runtime expires based on internal APC calculations determined by power consumption rates. Apcupsd works with most of the Smart-UPS models and most simple signaling models such as Back-UPS and BackUPS-Office.
Pping measures the roundtrip delay application that packets experience relative to any capture point on the connection’s path, using the naturally occurring reflected signal that can be obtained when the timestamp option is used in a TCP connection. These delays are collected per TCP connection with outbound packets providing the signal and inbound packets the reflection, and Pping measures the delay of two different round-trips from the monitored packets. Suggests it as a “more intriguing option [for service assurance monitoring] … It’s an edgier solution but not synthetic in any way. The philosophy is spot on. The execution requires a lot of effort though.”
Pynetbox is a Python API client library for Digital Ocean’s well-loved NetBox. Explains, “it’s basically a wrapper for requests and allows you to lookup and delete objects via the API in a python script. You can also create and delete via dictionaries. Very powerful when combined with for loops.”
iTop is designed to manage the complexity of shared infrastructures, giving you the ability to analyze the impact of an incident or a change on various services and contracts. This open-source web application is flexible enough to adapt to your processes whether you want rather informal and pragmatic processes or a strict ITIL-aligned behavior. Features include documenting IT infrastructure and the relationships between elements and stakeholders of the infrastructure; managing incidents, user requests and planned outages; documenting IT services and contracts with external providers including SLAs; manual or scripted information export; and mass import (manually and using scripts) or synchronize/federate any data from external systems.
perfSONAR is an open-source network measurement toolkit that provides visibility to the nuances of your network to help with debugging. It offers federated coverage of paths and helps establish end-to-end usage expectations.
Network UPS Tools provides support for assorted power devices, like UPSs and PSUs. It offers many control and monitoring features and a uniform control and management interface. Covers over 140 manufacturers and thousands of power device models.
CherryTree is a hierarchical, wiki-style notetaking application for organizing your notes, bookmarks, source code and more. Features rich text, syntax highlighting and the ability to prioritize information.
VSCodium is a repository of scripts that automatically build the Microsoft vscode repository into free-licensed binaries with a community-driven default configuration. Explains, “It’s just Visual Studio Code (which is open source), but with the telemetry/branding/licensing removed.”
LibreSpeed is a configurable, lightweight self-hosted speed test for HTML5 and more. Supports PHP, Node, multiple servers and more. Features download, upload, ping, jitter, IP Address, ISP, distance from server, telemetry, results sharing and Multiple Points of Test.
Unimus is a multi-vendor network device backup and configuration management system aimed at making automation, disaster recover, change management and configuration auditing easy. Free for up to 5 device licenses. Explains, “Unimus fully discovers devices that you add into it, no need to configure each device credentials, vendor, model, etc. manually – just add a bunch of IPs in, it will figure everything out. Mass Config Push for automation is also really nice. Config change notifications with a few clicks. You have a multi-user RBAC system, with per-device access rights. It supports proxies for distributed device polling … I could go on :)”
Joplin is an open-source notetaking/to-do app that can sync via plain text files for optimal flexibility. Notes can be organized in notebooks; are searchable; and can be copied, tagged and edited from the applications directly or from your text editor. Adds, “I have been using Joplin with success, android, windows, linux and a web browser clipping tool. All sync using one drive or nextcloud. Markdown.”
Filezilla is a fast, reliable cross-platform FTP, FTPS and SFTP client and server. It’s ability to connect to SSH secured hosts makes it a great choice if you need to give access to a client who is more comfortable with GUI than CLI interfaces.
Kate is a feature-packed editor for viewing and editing text files. Offers a wide variety of plugins, including an embedded terminal that can launch console commands, a powerful search and replace, on-the-fly spellcheck and a preview that shows how your MD, HTML and SVG will look. Supports highlighting for 300+ languages, understands how brackets work and helps navigate complex code block hierarchies. Appreciates the “session feature which can resume everything i was previously working on. When it starts, a menu displays all of the sessions you saved and leaves it up to your choice. The tabs features saves me from having to open more than one window. You can also change the Kate’s window theme, which is a small feature but very noticeable.”
Mailcow is an open-source suite for running a self-hosted mailserver. It is a collection of different applications—like SOGo, Postfix and Dovecot—with an intuitive web interface for managing accounts. Adds, “[It’s] free, dockerized, comes with rspamd, a powerful webgui, easy single-command upgrades and sogo (webmail/calendar/contacts). Obviously based on open-source software. I’ve been running it for 3 years. Never a single issue, it’s just fantastic.”
Security Trails allows you to access current and historical DNS, domain and IP data. A free account gets you 50 queries per month.
Moodle is an open-source, web-based learning management platform. Offers scalability and customizability, a simple interface with drag-n-drop features, good documentation and lots of plugins and add-ons. Explains, “It ties into Banner and plenty of other college ERP systems, but does have a little bit of a learning curve/quirks.”
ViewDNS offers a nice, online collection of DNS and OSINT tools. The tools are also offered as an API to give webmasters the ability to easily integrate them into their own sites. A free API “sandbox” account has a monthly limit of 250 queries.
TRex is an open-source tool that generates realistic L3-7 traffic for testing end-to-end network perfomance. Stateless functionality includes support for multiple streams, the ability to change any packet field and provides per-stream/group statistics, latency and jitter. Advanced Stateful functionality includes support for emulating L7 traffic with fully featured scalable TCP/UDP support. Emulation functionality includes client-side L3 protocols i.e ARP, IPv6, ND, MLD, IGMP, ICMP, DOT1X in order to simulate a scale of clients and servers. Can scale up to 200Gb/sec with one server.
kube-state-metrics is an add-on agent that listens to your Kubernetes API server to generate metrics on the state of objects like deployments, nodes and pods. Exposes raw data so you can get it unmodified and perform your own heuristics. Suggests it for Kubertnetes users, “To see the status, you use kube-state-metrics to get the Kubernetes status of your services into Prometheus/Grafana.”
Hashtab is an intuitive Windows tool for calclulating and displaying hash values from more than 2 dozen popular hashing algorithms. Simply select your file, go to properties and select the “File Hashes” tab to get started. Combines drag-n-drop simplicity with copy/paste and a built-in browse option.
Read the Docs is an open-source solution that helps organize your software documentation and keep it up to date through versioning. Hosts your documents and automatically builds them as you push code to Git, Mercurial, Bazaar or Subversion. Can host and build multiple versions of docs by having a separate branch or tag in your version control system.
FSumFrontend is a drag-and-drop tool that allows you to compute message digests, checksums and HMACs for files and text strings. Can handle multiple files at once. Explains, “[It] generates hash values from a huge number of cryptohash algorithms. Good to prove file integrity when sending out data to other organizations, use it on the daily.”
Audacity is an intuitive open-source multi-track audio editor and recorder. “I’m hardly an audiophile and definitely not an audio engineer, but any changes that I’ve ever needed to make to an audio file (convert from FLAC to 320 KbPS MP3, add fades, splice tracks, etc.) has been easily handled by Audacity, especially when you add additional libraries (LAME for MP3, FFmpeg, etc.)”
Bees With Machine Guns is a utility for creating micro EC2 instances to load test web applications. You simply enter a target url and an army of “bees” will simulate traffic originating from several different sources to hit the target.
Altaro VM Backup is a reliable, easy-to-use backup solution for Microsoft Hyper-V or VMware. The award-winning free version allows you to back up 2 virtual machines per host, so smaller businesses can enjoy robust, streamlined, enterprise-level functionality.
The Dude is a network monitor designed to improve the way you manage your network environment. It automatically scans all devices within specified subnets, maps the networks, monitors services and alerts you to problems. Allows you to mass upgrade RouterOS devices and configure them, run network monitoring tools and more.
vRIN is a VM appliance that can inject a large number of routes into a network, with routing, load test and GNS3. Generates /32 IPv4 and /128 IPv6 static routes and redistributes them into the selected routing protocol(s). Supports BGP (IPv4/6), OSPF, OSPFv3, RIPv2 and RIPng. Appreciates it as “a small VM with an easy-to-use interface to inject as much routes as you like.”
Policy Analyzer for analyzing and comparing sets of Group Policy Objects (GPOs) to highlight redundant settings, internal inconsistencies or differences between versions or sets of Group Policies. Can compare GPOs against current local policy and registry settings. Explains… “Maybe it’s not user friendly, but it’s a very good tool for comparing policies! You can export results to Excel as well.”
ONLYOFFICE is an open-source office and productivity suite that includes viewers and editors for text, spreadsheets and presentations. It is fully compatible with Office Open XML formats. Describes it as an “[o]nline ‘O365’-like product, [that] includes some project management and CRM stuff as well.”
MemTest86 is a comprehensive, standalone memory tester for x86 and ARM computers. It boots from a USB flash drive and checks for faults using a set of algorithms and test patterns that have been in development for over 20 years.
Vistumbler is wireless network scanner for Windows that uses wireless and GPS data to map and visualize the access points around you.
Diagrams.net offers collaborative, security-focused diagramming for teams. Available as either a convenient online tool or a desktop app for those who need maximum privacy and control.
Bulk Rename Utility is a Windows tool for easily renaming files and folders according to whichever criteria you choose. Allows you to add date/timestamps, replace numbers, insert text, convert case, add auto-numbers and more.
iTerm2-Color-Schemes is a nice resource for MobaXterm users, explains “I’ve taken screenshots of 230+ syntax color schemes from GitHub and assembled them in an Imgur album … To install you’ll need to find the matching entry in the GitHub and replace the corresponding section in your ‘MobaXterm.ini’ configuration file found wherever Moba is installed. Just make sure Moba is not opened when you save the .ini file.”
Invoke-GPOZaurr is a cmdlet found in the GPOZaurr PowerShell module that allows you to access a nice assortment of useful group policy reports. Recommends it as “a tool to eat your Group Policies and tell you what’s wrong with them or give you data for further analysis with zero effort on your side.”
CADE is a 2D vector editor that’s ideal for creating detailed network diagrams, flowcharts, schemas, maps and more with an intuitive GUI. It’s Visio-style functions allow you to drag-n-drop and connect predefined blocks, shapes and both raster and vector images. Blocks/attributes collections can be modified and extended.
TFC Temp File Cleaner cleans out the folders that house temporary files for Java and Windows and the IE, Opera, Chrome and Safari caches. It cleans the folders for all accounts on the computer, including Admin, NetworkService and LocalService.
GNU Wget enables you to retrieve files from the web via HTTP and FTP. Retrievals can be time-stamped, so a new version can be retrieved when the file has changed. Supports proxy servers, for a lighter network load and access behind firewalls.
VcXsrv is an open-source display server for Microsoft Windows that allows a Windows OS user to run GUI programs designed for the X Window System. VcXsrv can run Linux GUI programs installed with WSL, the Windows Subsystem for Linux.
Visual Paradigm Online is a network diagram tool with support for UML, Org Chart, Floor Plan, wireframe, family tree, ERD and more. Features a simple, intuitive diagram editor and the ability to work collaboratively with your team.
RUPS (Reading and Updating PDF Syntax) enables you to look inside a PDF document to see all the PDF objects and content streams. This tool is built atop iText.
Trello is a simple, intuitive app for organizing all your task lists and to-dos.
QuickLook offers a quick preview of file contents when you press the spacebar. Explains that it “gives you preview like in MacOS… I love this, it’s one of my favorite mac tools, now on Windows.” (Not for Windows 10 S devices)
Shodan is a search engine for Internet-connected devices that allows you to discover all the IoT devices on your network. Find out what is connected, where it’s located and with whom it’s communicating.
f.lux changes the color temperature of your display based on the time of day, which can be far easier on your eyes. Adds, “It takes a while to get used to the hue, but it’s an easy solution to headaches (besides blue-light blocking lenses). Only disadvantage is if you’re doing color-sensitive work since the color will be distorted (but even then, you can disable it for as long as you need).”
ImHex is a hex editor for “reverse engineers, programmers and people that value their eyesight when working at 3 AM.”
NetzTools is a secure, lightweight multitasking network app. It contains the following tools: show ip interface, ping, ping6, secure shell, telnet, port scan, traceroute, LAN scan, OUI lookup and name lookup.
Ant Renamer makes the task of renaming large groups of files and folders easier. You simply select the files you want to rename and choose one of the provided renaming rules. Allows you to stop and undo renaming tasks in case you have regrets. Supports Unicode names.
Unchecky is a quick answer to installers that try to push crapware or system modifications by requiring you to uncheck boxes at installation. Should you miss unchecking a box, you end up having to remove programs or reconfigure later on. Unchecky automatically unchecks unrelated installs and warns you about potentially suspect offers.
Course
IW Mentor is offering a full day of FREE Power Automate advanced training with about 9 hours of content plus labs start at 12:00 AM on 7/16/2021 and end at 12:00 AM on 1 July 2021. Ramp up your skills in this in-depth class, taught by Microsoft MVP, Laura Rogers. Basic knowledge of the Flow interface and concepts is necessary. Visit IW Mentor and click Register Now button for registration.

Tutorial
Everything You Always Wanted to Know About Optical Networking – But Were Afraid to Ask is a nice tutorial that touches on every area related to fiber in order to provide a basic understanding of how and why these networks function. Covers topics from the day-to-day to the advanced.
Developing NetBox Plugins is a series of how-tos on creating small, self-contained applications that can add new functionality to Netbox—extending as far as creating full-fledged apps. Plugins can access existing objects and functions of NetBox and use any libraries, external resources and API calls.
20 CIS Controls & Resources offers detailed explanations of key controls you’ll want to address in your security planning. Finds this resource from Center for Internet Security “useful to help get understanding and prioritization of critical security controls to focus on implementing or building up.”
Red Team Blues: A 10 step security program for Windows Active Directory environments provides a nice set of steps you can take to make it dramatically more difficult for attackers to create an opening that allows them to move inside your Active Directory environment.
Linux Upskill Challenge is a month-long course for those who want to work in Linux-related jobs. The course focuses on servers and commandline, but it assumes essentially no prior knowledge and progresses gently. This valuable content was offered as a paid course in the past, but is now free and fully open source.
NetworkChuck Video Channel features tutorials on pretty much any IT certification area you might be pursuing offered by a CBT Nuggets Trainer. Covers Cisco, CompTIA, AWS and Microsoft with a focus on teaching the concepts in a way that is actually fun.
Lawrence Systems Blog offers video tutorials on firewalls, storage solutions, MSP tools, security tools and open-source topics. There’s also discussion on some of the products and solutions they’ve worked with in addressing problems for their clients.
Robert McMillan’s YouTube Channel offers videos that teach how solve various complex technical problems—with a focus on speed. The videos quickly cover the essentials, so you can get the answers you need without a lot of extraneous detail. McMillan is an IT consultant, MCT and college instructor with over 50 technical certifications.
Shell Scripting Tutorial covers some of the basics of shell scripting and helps explain the powerful potential of programming available in the Bourne shell.
This excellent blog post explains exactly how to use the GPOZaurr command. Tells us, “I’d highly recommend getting familiar with the GPOZaurr powershell module that in minutes can produce an excel doc of all your gpo’s, let you know which ones have issues, reveal passwords stored in GPO’s and much more.”
NANOG Tutorials is the video channel of the North American Network Operators’ Group, which offers a good selection of highly useful tutorials on networking engineering, operations and architecture. Content is intended for both students and those working in the field, with a goal of sharing industry best practices, tools and resources.
Microsoft Virtual Training Days are 1-2 day virtual events for enhancing your skills. Take advantage of expert webinars on Microsoft Azure, Microsoft 365, Microsoft Dynamics 365 or Microsoft Power Platform and interact with Microsoft experts. Explains, “you can get 2 free certifications and insight into newer Microsoft products, totally free.” US options here.
Training Resource
dn42 is a large, dynamic VPN that uses various internet technologies (BGP, whois database, DNS etc.) where you can learn networking and experiment with routing. Gives you an opportunity to build your understanding of routing technologies risk-free using a reasonably large network.
flAWS Challenge is a fun way to learn about security issues to watch for with AWS and devops. A series of levels teach about how to avoid common mistakes as well as AWS-specific “gotchas.” Hints are provided that teach you how to discover what you need to know. If you’re in a hurry, you can just use the hints to go from one level to the next instead of playing along.
A Practical Guide to (Correctly) Troubleshooting with Traceroute is a rather lengthy slide deck from Richard Steenbergen’s presentation on how to make the best use of the traceroute tool in troubleshooting network connections. Walks you through the hows, whys and how tos of this highly useful tool.
Vscode Vim Academy is a game to help you learn and practice vim and vscode keys in an enjoyable way. Covers 2-5 vim keys per level, with level text and keys randomly generated per level. You race to complete 10 sets of tasks with as few keystrokes as possible.
Documentation Resource
A Proper Server Naming Scheme is a terrific blog post that explains a well-thought-out approach to hardware naming for small- to medium-sized businesses. These best practices are designed to help you avoid common problems as the list of devices grows and changes over time.
Affinity symbol set is a collection of printable, manufacturer-independent 2D icons you can use in your computer network diagrams. “Just drag and drop these svg icons onto your visio doc. They’re high quality and look good.”
Free eBook
Office 365/Microsoft 365 – The Essential Companion Guide covers everything from basic descriptions to installation, migration, use-cases and best practices for all features within the Office/Microsoft 365 suite. This 100+ page second-edition eBook, written for Altaro by Microsoft Certified Trainer Paul Schnackenburg, is the perfect desktop reference guide for current and aspiring Office/Microsoft 365 admins.
Websites
MITRE ATT&CK Navigator is a simple, open-source web app that provides basic navigation and annotation of the ATT&CK for Enterprise, ATT&CK for Mobile and PRE-ATT&CK matrices. It allows you to manipulate the cells in the matrix by color coding, adding a comment, assigning a numerical value and more.
urlscan allows you to scan and analyze websites by submitting a URL to find out if if it is targeting users. It automatically assesses the domains and IPs contacted, the resources (JavaScript, CSS etc.) requested from those domains and additional information about the page itself then takes a screenshot of the page and records the DOM content, JavaScript global variables, cookies created and a lot of other details.
MITRE ATT&CK is a global knowledge base of cybercrime tactics and techniques that is compiled from real-world observations. It is intended to fuel development of threat models and methodologies in the private sector, government and the cybersecurity product and service community.
Networking with FISH is a networking website that shares both technical information and relevant career tips and life lessons from Denise Fishburne, a talented CCIEx2 and CCDE.
Threatpost provides the latest cybersecurity information for an audience of IT pros. Includes security news, videos, original feature reports, expert commentary and reader discussion on high-priority news.